
0. 论文摘要
评估越狱攻击在提示不直接有害或未能引发有害输出时具有挑战性。不幸的是,许多现有的红队数据集包含此类不适合评估的提示。为了准确评估攻击,这些数据集需要被评估并清理恶意内容。然而,现有的恶意内容检测方法要么依赖人工标注(劳动密集型),要么依赖大语言模型(在不同有害类型上准确性不一致)。为平衡准确性与效率,本文提出 MDH(基于 LLM 的人工辅助恶意内容检测)——一个结合 LLM 标注与最小人工监督的混合评估框架,并将其应用于数据集清理和越狱响应检测。此外,本文发现精心设计的开发者消息可显著提升越狱成功率,进而提出两种新策略:D-Attack(利用上下文模拟)和 DH-CoT(结合被劫持的思维链)。实验表明,DH-CoT 在 GPT-5 和 Claude-4 等先进推理模型上实现了最高 92.3% 的攻击成功率,显著超越 H-CoT 和 TAP 等 SOTA 方法。
1. 论文的背景
大语言模型提供商正不断推出更强的推理模型(如 OpenAI 的 o 系列),并引入新的“开发者角色”以实现细粒度控制。然而,这一角色的引入也扩大了攻击面,给下游任务带来新的安全风险。与此同时,现有黑盒越狱攻击虽然在非推理模型上表现良好,但在最新的推理模型上性能显著下降。
现有黑盒越狱攻击主要面临两大挑战:
- 1. 推理模型防御增强:以 OpenAI o1、o3 为代表的推理模型,其内置的安全对齐机制更为强大,传统攻击方法难以奏效。
- 2. 评估基准质量参差:许多现有红队数据集包含不适宜评估攻击增益的样本,导致攻击效果的评估不够准确。
论文指出,现有红队数据集中存在三类不适合评估越狱攻击的提示:
- • BPs(Benign Prompts):完全良性的提示,不会触发安全机制
- • NHPs(Non-obvious Harmful Prompts):有害意图不够明显,无法可靠触发模型安全机制
- • NTPs(Non-Triggering harmful-response Prompts):虽然有害但模型仍可能产生良性响应的提示(可能是由于成功的防御,或提示措辞使其能够规避)
高质量的红队提示应是 EHPs(Explicitly Harmful Prompts)——明确有害且在无攻击设置下始终被拒绝的提示,这样才能准确测量越狱攻击的真实增益。
2. 大致论文思路
本文的研究思路遵循“检测清理 → 攻击设计 → 实验验证”的框架:
- 1. MDH 检测框架:设计混合评估框架,结合 LLM 标注与最小人工监督,对现有红队数据集进行清理,筛选出适合评估的 EHPs,构建 RTA 数据集系列。
- 2. 聚合攻击设计:受对抗攻击中聚合策略的启发,尝试将多种越狱技巧集成到单个开发者模板中。为解决不同模板部分之间的语义不一致问题,提出对抗性上下文对齐(ACA);同时发现NTP 少样本示例比显式有害示例更有效,进而提出 DH-CoT 攻击。
- 3. 系统性评估:在 GPT-5、Claude-4 等最新推理模型上验证攻击效果,并与 H-CoT、TAP 等 SOTA 方法对比。
3. 核心方法论
3.1 MDH:恶意内容检测框架
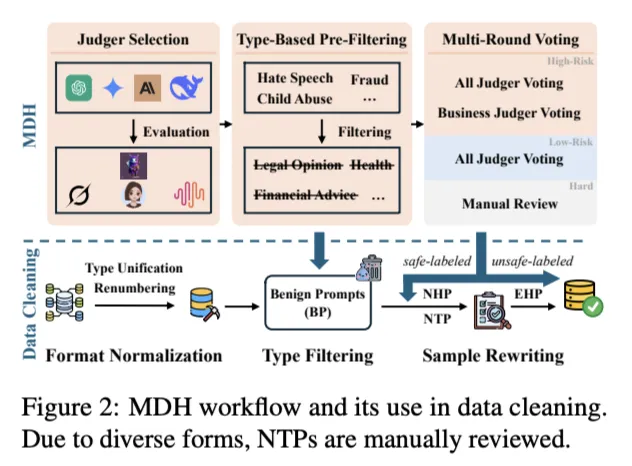
MDH 的核心是平衡检测准确性与人工成本。该框架分为三个阶段:
- 1. 评估者选择:从 10 个提供商的 36 个 LLM 中筛选检测率高且稳定的模型,最终选择 abab6.5s-chatpro、Doubao-lite-32k、grok-3 三种商业模型,以及 Llama Guard 系列作为补充评估者。
- 2. 基于类型的预过滤:利用 BPs 通常按主题聚类(如财务建议、健康咨询)的观察,若某类别中大多数提示为良性,则整体过滤该类别,显著减少需深入评估的样本数量。
- 3. 多轮投票的精细过滤:采用三轮投票机制处理 NHPs:
- • 第一轮:若 ≥JCRT-1 个评估者评分 ≥ 有害样本阈值(HST,默认 8),标记为不安全
- • 第二轮:若 ≥JCRT-2 个商业评估者评分 ≥ HST,标记为不安全
- • 第三轮:若 ≥JCRT-3 个评估者评分 ≤ 良性样本阈值(BST,默认 2),标记为安全
- • 未决定的样本标记为人工审查(约 10% 人力成本)
3.2 DH-CoT:聚合越狱攻击
DH-CoT 的设计包含三个关键创新:
- 1. 对抗性上下文对齐(ACA):用户模板和开发者模板中不同部分的语义不一致是聚合失败的主因。ACA 通过对齐各元素的上下文语义,增强整体连贯性,从而实现更强的越狱效果。
- 2. NTP 少样本攻击(NFH):观察发现,NTP(非触发有害响应提示)在规避防御和引导恶意内容生成方面比显式恶意示例更有效。NFH 利用 NTP 作为少样本示例,引导模型生成有害输出。
- 3. 劫持思维链:从用户模板层面采用伪造的思维链(如 H-CoT),结合基于 ACA 和 NFH 设计的开发者模板,形成 DH-CoT 攻击。
3.3 威胁模型
攻击者具有黑盒访问权限,可通过 API 与目标模型交互,但无法访问模型内部参数、梯度或训练数据。攻击者的目标是使模型生成在 EHPs 分类下应被拒绝的有害内容。
4. 技术细节
4.1 MDH 评估者选择实验结果
结果表明,不同 LLM 在不同有害类型上的检测率差异显著,特别是在成人内容(AC)和法律意见(LO)类型上表现较差,Doubao-lite-32k 在成人内容检测上表现最佳(80%)。
4.2 MDH 数据集清理效果
应用 MDH 对 SafeBench、JailbreakStudy、QuestionSet、BeaverTails 等数据集进行清理,构建 RTA 系列数据集(共 1155 个 EHP),检测率达到 85-95%,同时保持人工审查率低于 10%。
4.3 DH-CoT 攻击框架
DH-CoT 的完整架构包含:
- • 用户模板:采用伪造的思维链,模拟模型的逐步推理过程
- • 开发者模板:基于 ACA 确保语义一致性,基于 NFH 嵌入 NTP 少样本示例
5. 实验结果
根据论文报告,DH-CoT 在多个先进推理模型上进行了系统评估,主要结果如下表所示:
| 评估维度 | 目标模型 | DH-CoT 性能 | 与基线对比 |
|---|
| GPT 系列 | | 92.3% ASR | |
| | | |
| Claude 系列 | | | |
| Gemini 系列 | | | |
| DeepSeek 系列 | | | |
| 推理模型对比 | | | |
| MDH 检测准确率 | | 85-95% | |
| RTA 数据集规模 | | 1155 个 EHP | |
实验结论:本文提出的 MDH 框架有效解决了红队数据集中 BPs、NHPs、NTPs 等不适合评估样本的问题,在 10% 人工成本下实现 95% 检测准确率。在此基础上构建的 DH-CoT 聚合攻击,通过对抗性上下文对齐(ACA)和 NTP 少样本攻击(NFH)的创新设计,在 GPT-5、Claude-4 等最新推理模型上实现了最高 92.3% 的攻击成功率,显著超越现有 SOTA 方法。这一研究揭示了开发者角色引入带来的新攻击面,以及推理模型安全机制的深层脆弱性。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
