编委精选 | 中国科学院自动化所和南京理工大学联合团队:面向Diffusion Transformer加速的分层时间步感知缓存框架HiCache
- 2026-06-12 12:03:07
编者按:Diffusion Transformer(DiT)因其强大的生成能力在图像、视频等任务中广泛应用,但其高计算成本和慢推理速度成为实际部署的瓶颈。近年来,研究者提出了多种无需修改架构或轻量级修改的加速方法,包括在扩散过程中缓存部分中间特征,避免重复计算。但现有的多数缓存策略仅在相邻时间步之间进行特征复用,难以充分挖掘扩散过程中的时间冗余。同时,按照固定时间步或预先设定规则进行缓存判断的机制,易导致无效复用和生成质量退化。今天给大家带来解决这些挑战的分层时间步感知缓存框架HiCache,研究成果来自中国科学院自动化研究所和南京理工大学联系团队。

论文信息
题目:HiCache: Hierarchical Timestep-aware Caching for Diffusion Transformer Acceleration
作者:Changwang Mei, Peisong Wang, Shuang Qiu, Gang Li, Qinghao Hu, Yifan Zhang, Zhihui Wei and Jian Cheng
引用格式:Changwang Mei, Peisong Wang, Shuang Qiu, Gang Li, Qinghao Hu, Yifan Zhang, Zhihui Wei & Jian Cheng (2026). HiCache: Hierarchical Timestep-aware Caching for Diffusion Transformer Acceleration. Visual Intelligence, Volume 4, Article no. 9.
全文链接:https://link.springer.com/article/10.1007/s44267-026-00112-6
关键词:Computer vision, Image generation, Diffusion models, Generation acceleration
文章概述
现有针对Diffusion Transformer的加速方法虽然能够降低采样开销,但多数缓存策略仅在相邻时间步之间进行特征复用,缓存比例通常受限于较低范围,难以充分挖掘扩散过程中的时间冗余;同时,按照固定时间步或预先设定规则进行缓存判断的机制,往往忽视了不同层、不同时间步之间真实的语义相似性,容易导致无效复用和生成质量退化。针对这一问题,研究团队提出了分层时间步感知缓存框架HiCache,旨在通过更大范围的时间步复用与更合理的缓存决策机制,提升扩散采样过程中的计算效率与缓存利用率,同时尽可能保持生成结果的质量稳定性。
为验证方法有效性,团队在DiT、Large-DiT和U-ViT等代表性的Diffusion Transformer模型上开展了系统实验。实验结果表明,HiCache在保证生成质量的同时有效降低了推理延迟和计算开销,在不同采样步数和模型规模下均展现出较优的质量—效率权衡。即使在较高缓存比例设置下,该方法仍能较好保持图像细节、结构一致性和视觉质量,说明其具有良好的鲁棒性与可扩展性。
主要贡献
1) 设计了语义引导缓存损失(Semantic-Guided Cache Loss,SGCL),该方法不再依赖固定规则进行缓存判断,而是显式利用当前特征与缓存特征之间的语义相似性,自适应调整缓存强度,使模型在语义冗余较高时优先复用缓存、在相似性较低时倾向重新计算,从而提高缓存决策的稳定性与有效性。
2)提出了一种层级化的时间步缓存学习机制(Timestep Block Cascade Learning,TBCL)。该方法将扩散过程中的时间步组织为粗粒度父块与细粒度子块,并通过级联式约束实现跨连续时间步的稳定缓存复用,从而突破现有方法大多局限于相邻时间步复用的限制,显著扩展缓存搜索空间,提升高缓存比例下的复用效率。
3)提出了统一的分层时间步感知缓存框架 HiCache,将TBCL与SGCL有机整合到端到端的Diffusion Transformer加速方案中,仅需优化轻量级路由参数,无需对主干模型进行大规模重训练。实验结果表明,HiCache在多个代表性的Diffusion Transformer模型上均取得了较优的质量—效率权衡。在DiT-XL/2模型的实验设置下,HiCache相较基线方法同时降低了推理延迟并提升了生成质量。上述结果说明,该方法即使在较高缓存比例下,仍能较好兼顾生成质量与推理效率,展现出良好的鲁棒性与可扩展性。
主要内容
现有针对Diffusion Transformer的缓存加速方法主要面临两类问题:一是缓存复用范围有限,现有方法大多只在相邻时间步之间进行特征复用,缓存比例通常受限于较低范围,难以充分挖掘扩散过程中的时间冗余。二是缓存决策方式较为粗糙,许多方法主要依据固定时间步或预设规则进行判断,而未显式利用不同层、不同时间步之间的语义相似性,容易造成无效复用,并影响生成质量。
为解决上述问题,论文围绕层级缓存控制与语义引导优化构建了HiCache框架,其主要内容如下(见图1):
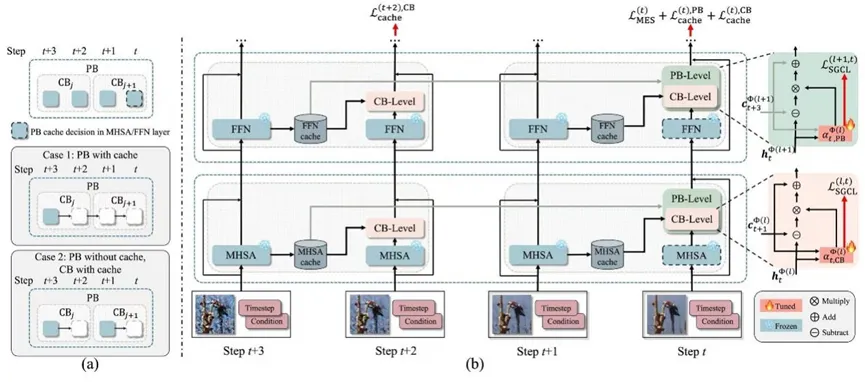
图1 HiCache 总体框架
1)语义引导缓存损失(SGCL)
该模块主要解决现有缓存方法语义感知不足的问题,在各层Transformer模块中引入可学习路由参数,并结合当前特征与缓存特征的余弦相似度,对缓存复用与重计算进行自适应调节,从而将基于固定规则的缓存判断转化为基于语义相似性的动态优化过程,提升缓存学习的稳定性与有效性。该机制仅在训练阶段提供语义引导,不会带来额外推理开销。语义引导缓存损失核心公式详见论文公式(4)和(5)。
2)时间步块级联学习(TBCL)
为稳定利用连续时间步之间的冗余关系,TBCL将扩散采样过程组织为父块与子块两级结构,并通过级联式缓存继承机制联合建模长程复用与局部决策,从而在较高缓存比例下实现稳定推理。其两级缓存控制过程可进一步表示为块级特征更新与整体优化目标,核心公式详见论文公式(9)、(11)和(15)。
3)HiCache 分层训练与推理流程
在整体实现上,HiCache将TBCL与SGCL整合为统一的分层时间步感知缓存框架。论文在冻结预训练DiT主干参数的基础上,仅引入并优化轻量级路由参数,以较低训练成本实现缓存策略学习;在推理阶段(见图2),则采用“先父块、后子块”的两级门控流程,优先利用长程时间冗余,再通过局部判断补充细粒度控制。
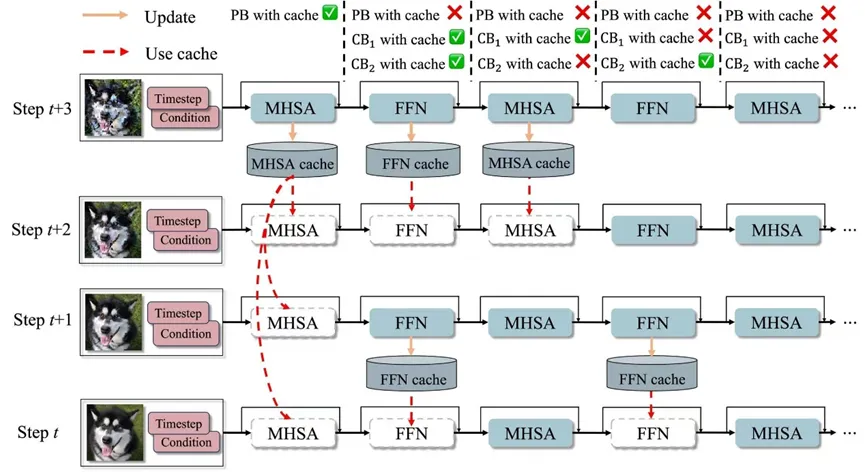
图2 HiCache 推理流程
论文通过将语义感知的缓存决策与层级化时间步复用机制相结合,构建了统一的HiCache框架,并验证了该框架在较高缓存比例条件下兼顾生成质量与计算效率的可行性。
实验结果
1) 实验设置:在ImageNet上对HiCache进行了系统验证,覆盖DiT、Large-DiT和U-ViT三类代表性的Diffusion Transformer模型。其中,DiT与Large-DiT采用DDIM采样器,U-ViT采用DPM-Solver-2,采样步数设置为10–50;训练阶段冻结原始主干参数,仅优化轻量级路由参数,以实现分层缓存策略学习。
2)评估指标:IS(图像清晰度与多样性)、FID(生成分布与真实分布差异)、sFID(空间结构一致性)、Precision(样本保真度)、Recall(分布覆盖能力),以及TMACs、推理延迟和峰值显存占用。定量实验中每次生成50,000张图像,并在单张A5000 GPU上测试批量生成延迟,最终结果取5次实验平均值。
3)关键结果:HiCache在DiT、Large-DiT和U-ViT三类代表性的Diffusion Transformer模型上均取得了较优的质量—效率权衡,表现出良好的生成质量、推理效率与方法可扩展性,见表1、表2和表3。
表1 HiCache在DiT模型上的性能结果
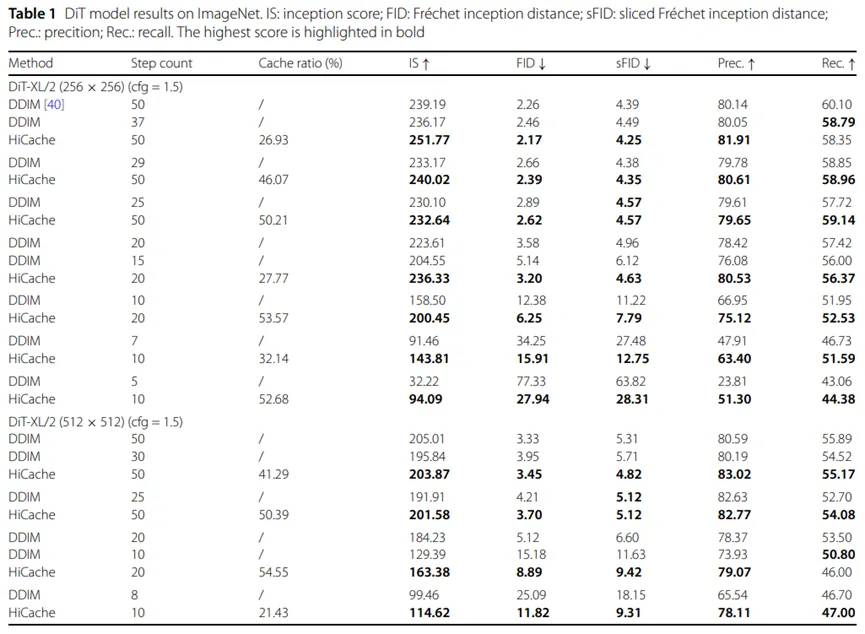
表2 HiCache在Large-DiT模型上的性能结果
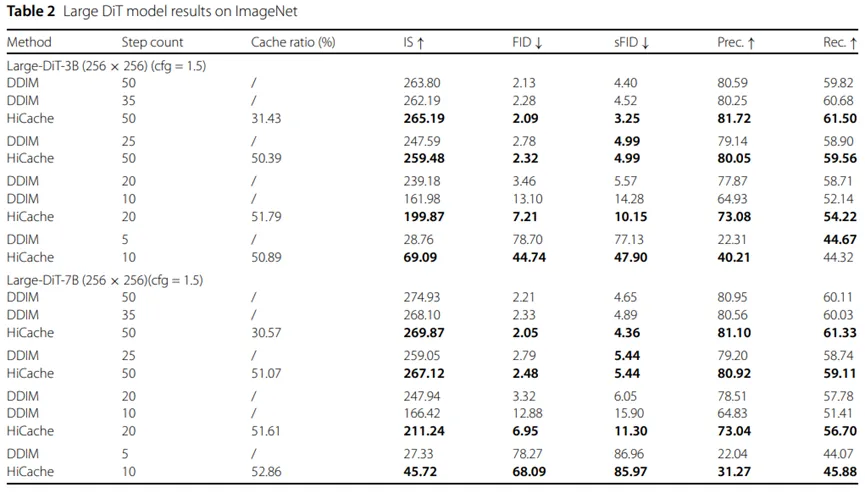
表3 HiCache在U-ViT模型上的性能结果
4)可视化结果:HiCache在较高缓存比例下仍能较好保持图像细节、结构一致性和整体视觉质量,见图3。

图3 HiCache在高缓存比例下的图像生成结果
结论和展望
本文提出HiCache框架通过联合建模层级化时间步缓存控制与语义引导缓存决策,实现了Diffusion Transformer采样效率与生成质量的协同提升。其中,TBCL依托父块与子块组成的两级层次结构,实现了连续时间步之间的稳定缓存复用;SGCL基于特征语义相似性对缓存决策进行动态引导,从而抑制无效复用并提升时间冗余利用效率。实验结果表明,HiCache在DiT、Large-DiT和U-ViT等代表性的Diffusion Transformer模型上均表现出较优的质量—效率权衡,并在较高缓存比例下保持了较好的生成质量,验证了该框架在多种Diffusion Transformer模型中的有效性。
未来工作可从以下几个方面展开:
1)自适应块结构优化:当前方法仍依赖预设的时间步块划分方式,后续可探索更灵活的自适应块结构设计,以提升对不同采样阶段和冗余模式的适应能力;
2)动态路由机制增强:现有框架对路由控制和超参数设置仍具有一定依赖,未来可进一步引入更灵活的动态调节机制,以增强方法的泛化性与稳定性;
3)更复杂任务扩展:可将该框架进一步推广到更多Diffusion Transformer架构及更复杂的生成任务中,验证其在更广泛场景下的适用性与实用价值。
作者简介
梅长旺,南京理工大学与中国科学院自动化研究所联培博士生,主要研究方向为高效视觉生成。
王培松,中国科学院自动化研究所副研究员,硕士生导师,主要研究方向为轻量化人工智能。
邱爽,香港城市大学助理教授,主要研究方向为生成式模型、强化学习、多模态大模型等。
李钢,中国科学院自动化研究所副研究员,主要研究方向为计算机体系结构和深度学习。
胡庆浩,中国科学院自动化研究所副研究员,硕士生导师,主要研究方向为深度神经网络轻量化。
张一帆,中国科学院自动化研究所研究员,博士生导师,主要研究方向为视觉内容分析与高效计算。
韦志辉,南京理工大学教授,博士生导师,主要研究方向为稀疏低秩建模和图像与视频分析。
程健,中国科学院自动化研究所研究员,博士生导师,主要研究方向为神经网络高效计算、智能科学计算、智能芯片架构设计等。

编辑:丁予聆
审核:彭琳
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【南京那家医院治疗腋臭比较好】注射肉毒素治疗腋臭的效果能维持多久?
- 岚山“圈粉”徐州、南京!
- 【南京大学主办|往届会后三个多月实现EI检索|IET Fellow支持】第二届数字经济与智能计算国际学术会议 (DEIC 2026)
- 3人!南京大学苏州校区招聘 含办公室文员、秘书等
- 【大学PK】浙江大学VS南京大学
- 南京银行· 惠聚4月 | 城北中支活动精彩放送
- 南京同仁堂酸枣仁百合茯苓茶
- ECNUMUNA2026 | 南京大学全国模拟联合国大会参会回顾暨喜讯
- 考研复试丨南京邮电大学教育科学与技术学院 2026年硕士研究生复试录取工作实施细则
- 南京兼职 04月14日 南京兼职 南京招聘信息
