南京邮电大学通信与信息工程学院季薇教授团队在《郑州大学学报(理学版)》上发表题为:“基于语音信号时频特征融合的帕金森病检测方法”的研究型论文。
Cite: WANG Chenzhe, JI Wei, ZHENG Huifen, et al. Parkinson′s Disease Detection Method Based on Time-frequency Feature Fusion of Speech Signals[J]. Journal of Zhengzhou University(Natural Science Edition), 2025, 57(1): 53-60.
帕金森病(Parkinson′s disease, PD)是仅次于阿尔茨海默病的第二大神经退行性疾病。其早期诊断对干预治疗至关重要。语音损伤是PD的早期核心症状,表现为声音嘶哑、音量低沉、语速缓慢等特征。这种由喉部及呼吸肌肉控制力下降引发的语音损伤,为疾病的早期筛查提供了重要的生物学线索。利用语音信号结合人工智能技术进行帕金森病检测,凭借其非介入式、采集便捷且低成本的天然优势,能够有效缓解医疗资源紧张的压力,极大地提升诊疗效率。
尽管深度学习在语音信号处理领域已取得显著进展,但现有的帕金森病语音检测方法仍面临诸多瓶颈。一方面,传统方法多依赖持续元音数据,难以捕捉长句语料中丰富的时序病理信息;另一方面,常用的梅尔刻度特征在表征特定病理信息时存在局限性,且现有模型往往难以兼顾语音信号的全局时序与细粒度局部特征。因此,如何充分挖掘长句语音中的深层病理特征,构建准确高效的检测模型,成为当前极具社会意义与研究价值的核心课题。
针对上述挑战,本文提出了一种基于语音信号时频特征融合的帕金森病语音检测方法。该方法创新性地对传统的S-vectors模型进行改进,引入Conformer编码器模块,利用自注意力机制与卷积神经网络的协同作用,实现了对语音时域全局特征与局部特征的深度提取。同时,通过将频域全局特征嵌入时域特征,有效弥补了单一特征的表征缺陷。这一研究不仅显著提升了模型对帕金森病病理信息的学习与识别能力,更为未来开发普惠式、智能化的神经退行性疾病早期筛查系统提供了强有力的技术支撑。
构建基于 Conformer 的改进 S-vectors 模型将S-vectors模型中的原有编码层替换为Conformer架构。该设计结合了Transformer的全局自注意力机制与CNN的局部卷积优势,不仅能捕捉语音的长时依赖关系,还能通过相对位置编码和深度可分离卷积提取细粒度的局部特征,有效解决了传统模型难以兼顾全局与局部特征的难题。
提出时频特征融合策略,针对单一梅尔特征表征能力不足的问题,引入与PD病理密切相关的频域全局特征(如基频包络、Jitter等)。通过特征嵌入模块将103维频域特征与256维时域特征融合,从时域和频域双维度挖掘病理信息,显著增强了模型对PD语音特征的表达能力。
验证多语料环境下的检测性能,在公开的MDVR-KCL数据集(英文)及自采中文语音数据集上进行了广泛验证。实验结果表明,该方法在不同语言和语料环境下均优于基线模型,展现了极强的泛化能力与临床应用潜力。
本文针对帕金森病(PD)语音检测中现有模型难以兼顾全局时序信息、且传统梅尔刻度特征难以精准表征病理信息的痛点,提出了一种基于语音信号时频特征融合的检测方法。该研究创新性地利用长句语料,结合深度学习与信号处理技术,显著提升了检测精度。
检测方法包含源域预训练与目标域微调两个阶段。模型以语音的梅尔频率倒谱系数(Mel frequency cepstrum coefficients, MFCC)作为输入。在S-vectors模型的基础上,本文进行了关键改进——将原有的编码层替换为Conformer架构的编码器模块。这一改进结合了Transformer的自注意力机制和CNN的卷积模块,使其能有效关注PD语音中响度降低、语速异常等长距离时序特征。
为了弥补单一时域特征的局限,本文引入了频域全局特征嵌入模块。在微调阶段,利用DisVoice库提取了包括基频包络、Jitter、PPQ及清浊音能量等在内的103维频域特征。这些特征经过归一化和映射后,被嵌入到Conformer提取的256维时域特征中,形成320维的融合特征,最终通过全连接层实现分类。
在MDVR-KCL公开数据集(包含英/西语)和自采帕金森中文数据集上进行了验证,旨在评估模型在不同语言环境下的泛化能力。实验选取了S-vectors、X-vectors及ResNet18等主流模型作为基线,结果表明本文提出的方法在各项指标上均显著优于基线模型。具体数据方面,在自采中文数据集上,本文方法(fe3配置)的准确率(acc)达到了90.24%,敏感度(sen)为91.82%,AUC值为0.91,而在MDVR-KCL数据集上准确率更是高达95.20%。通过对比不同嵌入位置发现,将频域特征嵌入到全连接层-3(fe3)的效果优于嵌入到层-4(fe4),且参数敏感性分析显示,当编码层数设置为2层、注意力头数为4时模型性能最佳,过多的层数反而容易导致过拟合。
为进一步剖析模型内部各组件的贡献,本文进行了消融实验。实验结果有力地证实了自注意力机制与相对位置编码的关键作用,一旦去除,模型仅依赖卷积提取局部特征,导致准确率从95.20%大幅下降至86.34%左右,这说明缺乏对全局时序信息的捕捉将使模型难以学习到清浊音转换次数等关键病理特征。同时,实验也验证了卷积模块及频域全局特征嵌入的必要性,去除这些模块均会在不同程度上削弱模型性能,从而证明了融合局部细粒度特征与多维度频域信息对于提升帕金森病语音特征表征能力的重要性。
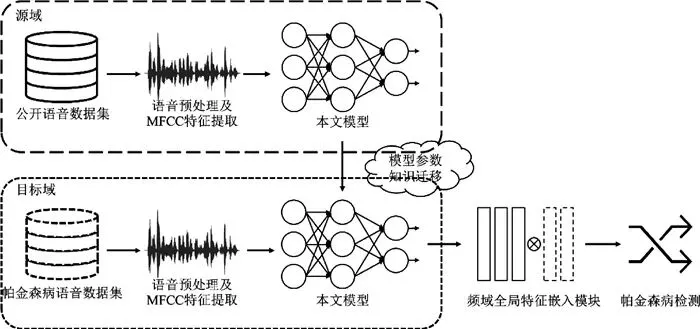
图1 本文方法训练流程图。该图展示了基于迁移学习的帕金森病语音检测框架。流程上,模型先在公开语音数据集(源域)进行预训练,再将参数迁移至帕金森病数据集(目标域)微调,并引入频域全局特征嵌入模块。这直观体现了“通用特征学习”到“病理特征适配”的过程,利用大规模数据提升小样本下的检测性能。
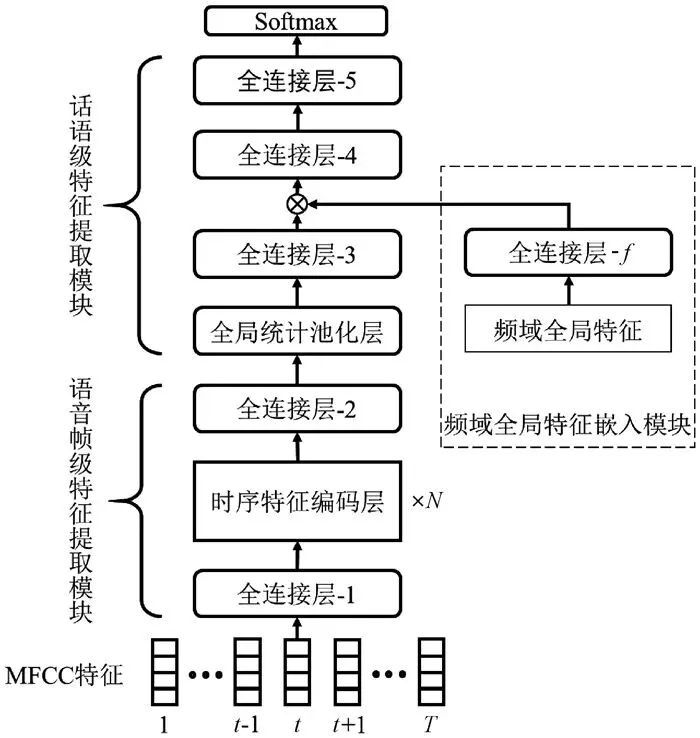
图2 本文模型结构图。该图清晰展示了模型的双模块结构。左侧展示了语音帧级特征如何通过Conformer编码器提取时域信息;右侧展示了频域全局特征的嵌入过程。图中直观呈现了30维MFCC特征与103维频域特征如何融合为320维的联合特征向量,体现了“时频互补”的设计思路。
表1 MDVR-KCL数据集实验结果
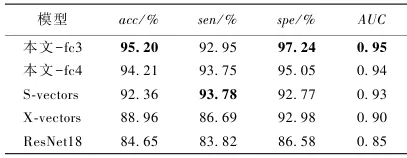
表2 自采帕金森数据集实验结果
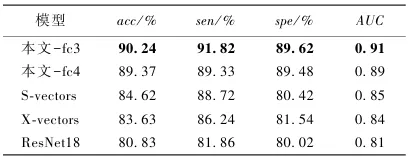
从表1与表2可以看出,对比了本文方法与S-vectors、X-vectors及ResNet18在MDVR-KCL及自采数据集上的表现。数据显示,本文方法在准确率(Acc)和AUC指标上均取得了最优成绩(如MDVR-KCL数据集上Acc达95.20%),证明了模型在不同语言环境下的优越性。
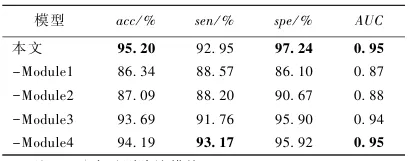
表3 消融实验
表3可以看出,通过逐一移除自注意力机制、相对位置编码、卷积模块及频域嵌入模块,量化分析了各组件的贡献。结果表明,去除频域嵌入模块(Module 4)后准确率下降了1.5%,而去除自注意力机制后下降幅度更大,有力验证了Conformer架构与时频融合策略对提升PD检测精度的核心价值。第一作者:季薇 教授
南京邮电大学 通信与信息工程学院
研究方向:主要从事信号处理与机器学习研究
E-mail:jiwei@njupt.edu.cn
引用格式:
王晨哲, 季薇, 郑慧芬, 等. 基于语音信号时频特征融合的帕金森病检测方法[J]. 郑州大学学报(理学版), 2025, 57(1): 53-60.
WANG Chenzhe, JI Wei, ZHENG Huifen, et al. Parkinson′s Disease Detection Method Based on Time-frequency Feature Fusion of Speech Signals[J]. Journal of Zhengzhou University(Natural Science Edition), 2025, 57(1): 53-60.

扫描上方二维码,或点击文末“阅读原文”查看文献。
https://html.rhhz.net/ZZDXXBLXB/html/20250108.htm

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
