蛋白质的序列与修饰状态的精准解析是理解细胞功能、诊断疾病的关键。然而,现有的蛋白质测序技术如Edman降解与质谱法,在检测限、通量及单分子灵敏度方面存在局限。纳米孔技术凭借其单分子传感能力,已在核酸测序中取得巨大成功,但在蛋白质测序中,如何同时高精度区分所有20种氨基酸及其翻译后修饰,仍是尚未实现的关键挑战。
南京大学黄硕教授团队在《Nature Methods》上发表了一篇题“Unambiguous discrimination of all 20 proteinogenic amino acids and their modifications by nanopore”的研究论文。该研究设计并构建了一种带有单一镍离子(Ni²⁺)修饰的异源八聚体MspA纳米孔,首次实现了对全部20种蛋白质氨基酸及4种代表性修饰氨基酸(甲基化精氨酸、乙酰化苏氨酸、糖基化天冬酰胺、磷酸化丝氨酸)的明确区分。结合机器学习算法,整体识别准确率达98.6%,并成功应用于复合氨基酸片剂及肽酶消化产物的分析,为基于纳米孔的蛋白质测序奠定了关键基础。
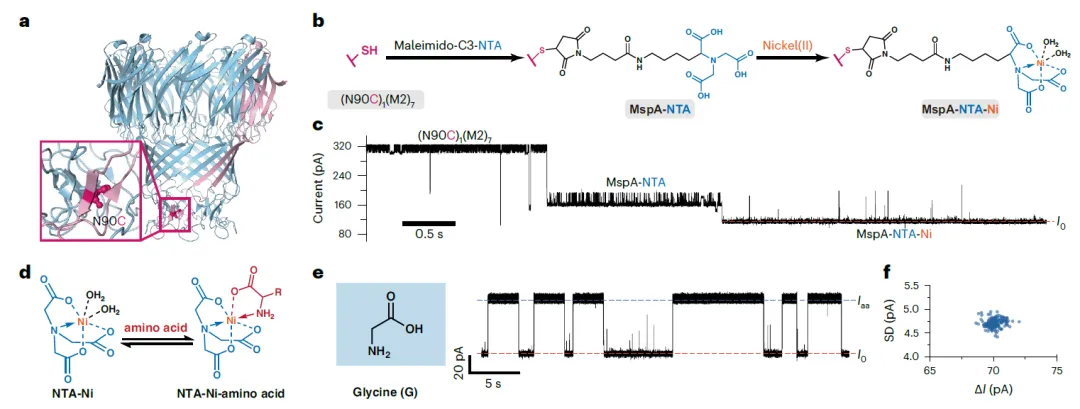
传统纳米孔因分辨率不足,难以同时区分所有氨基酸。该研究受固定化金属亲和色谱启发,在锥形MspA纳米孔的最窄处引入单一的镍-氮川三乙酸适配体。该设计利用氨基酸作为双齿配体与固定的Ni²⁺可逆结合,从而在孔道内产生特征性的电流信号。当氨基酸结合时,电流从开放水平跃迁至更高的水平,产生具有独特幅度和噪声特征的“电流指纹”。
图1. 用于氨基酸传感的Ni-NTA修饰纳米孔的构建与工作原理示意图
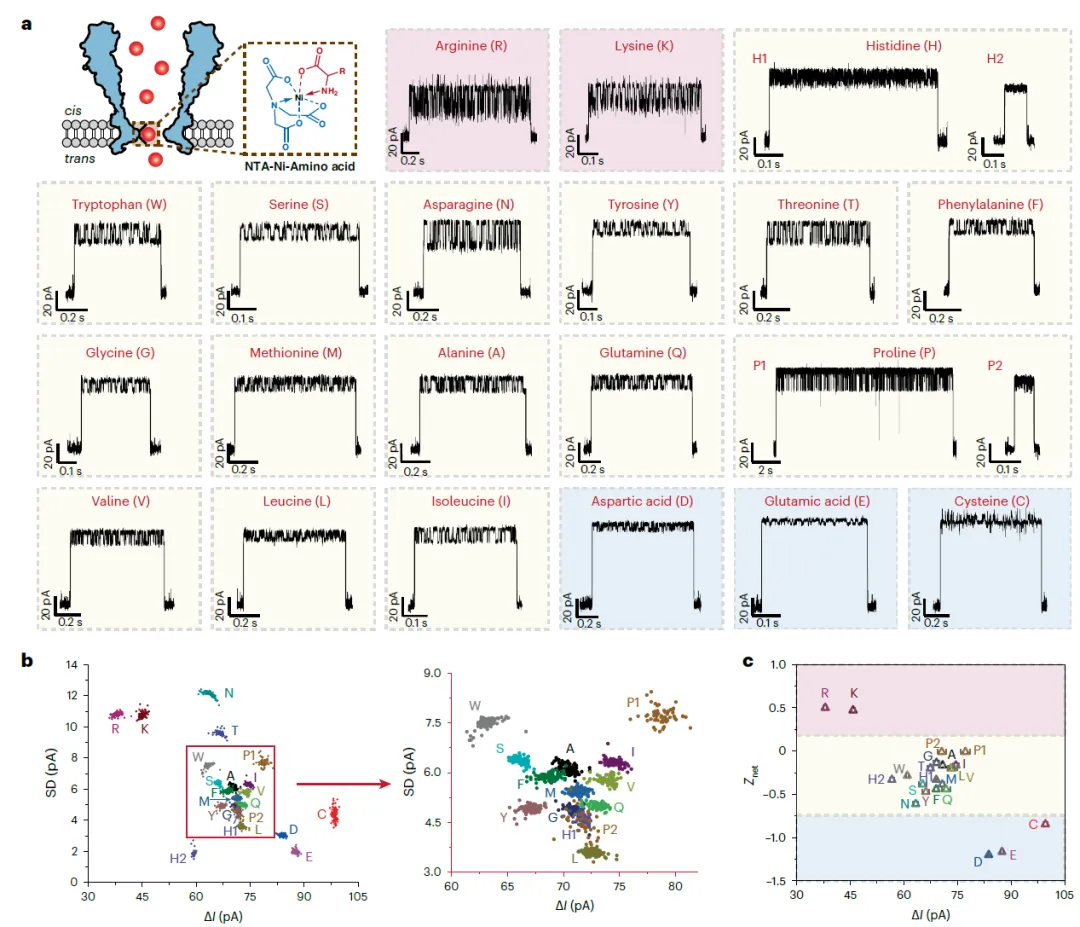
研究人员对20种氨基酸逐一进行了测试。结果显示,每种氨基酸均产生独特的事件波形。通过分析电流阻断幅度与噪声的二维散点图,绝大多数氨基酸事件可被清晰区分。值得一提的是,即使是难以用质谱区分的同分异构体亮氨酸与异亮氨酸,也能被该纳米孔明确辨别。
图2. 使用MspA-NTA-Ni区分20种氨基酸
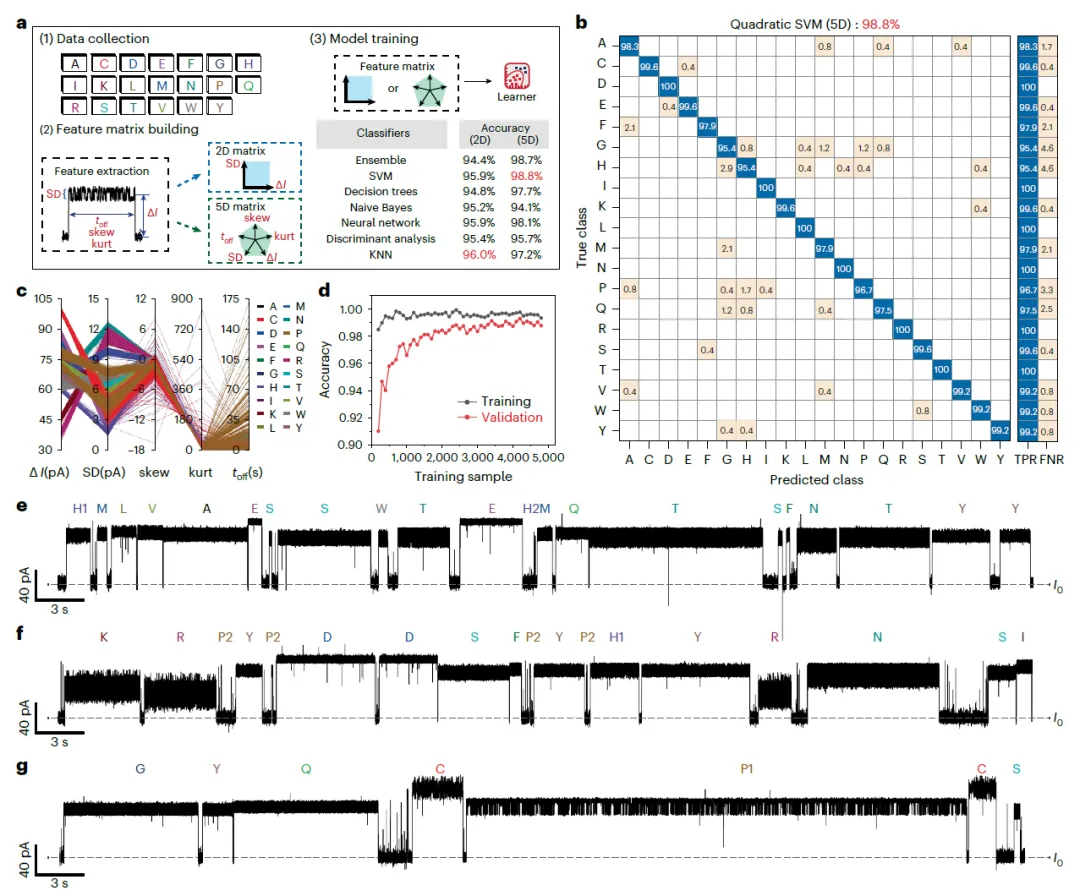
为实现自动化、无偏见的识别,团队开发了定制的机器学习流程。从每个氨基酸的传感事件中提取五个关键特征构建特征矩阵。经比较,二次支持向量机模型在十折交叉验证中表现出最高的98.8%验证准确率。即使是在二维散点图上有部分重叠的组氨酸与脯氨酸事件,在五维特征空间中也实现了95%以上的准确识别。
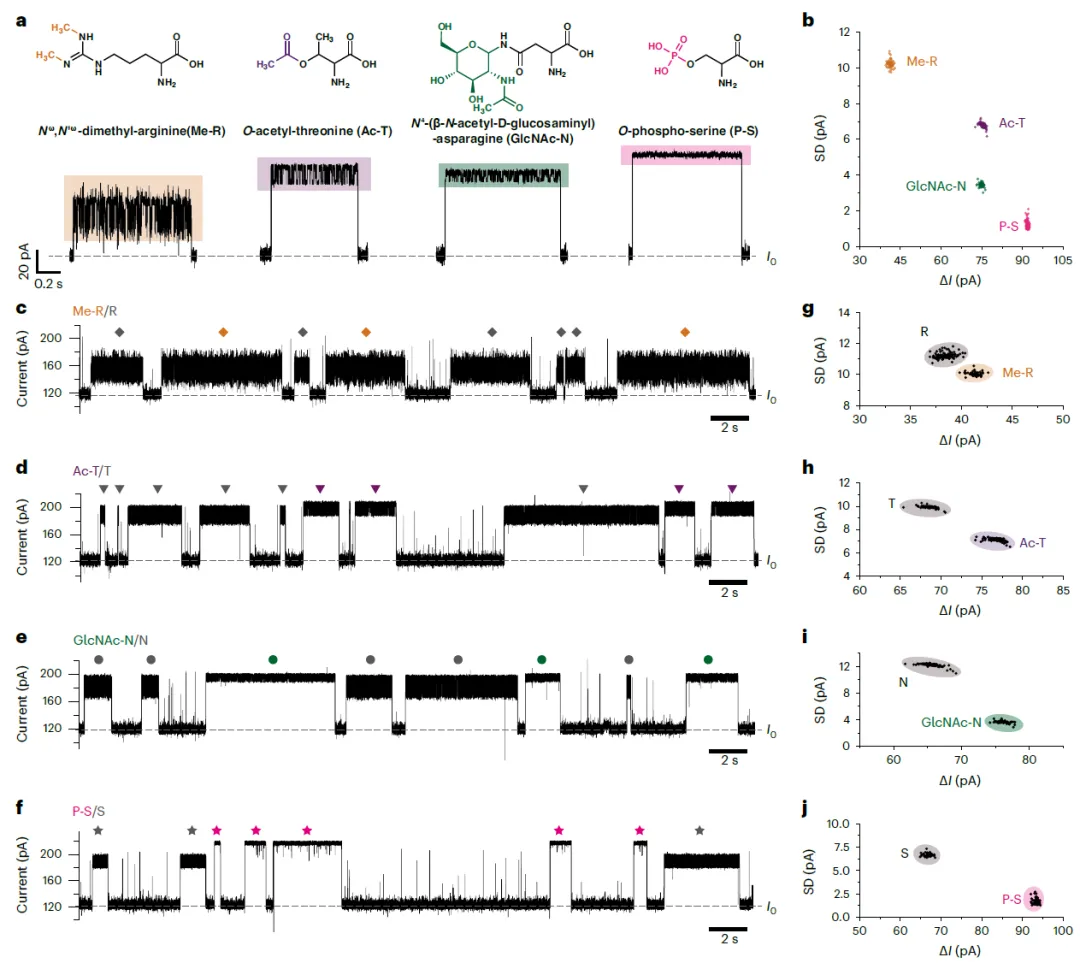
该技术的优势进一步体现在对翻译后修饰的识别上。研究测试了四种常见的修饰氨基酸。这些修饰氨基酸产生的事件特征与其未修饰前体明显不同,在散点图中形成独立的聚类。将20种天然氨基酸与4种修饰氨基酸的数据合并训练,机器学习模型仍能保持98.6%的高准确率,证明了该策略强大的分辨能力与扩展潜力。
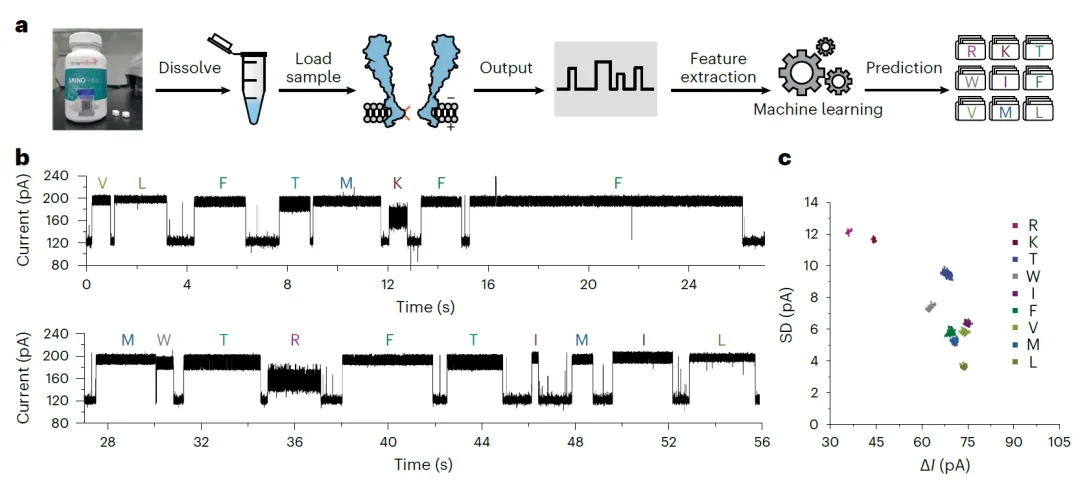
为展示其实用性,该技术被直接用于分析商业复合氨基酸片剂。仅需将片剂溶解并加入测量体系,纳米孔即可连续报告事件。机器学习模型成功从90分钟的记录中识别出精氨酸、赖氨酸、苏氨酸等九种氨基酸成分,与产品说明书完全一致,展现了其在营养产品质量控制中的直接应用潜力。
图5. 利用MspA-NTA-Ni快速分析复合氨基酸片剂
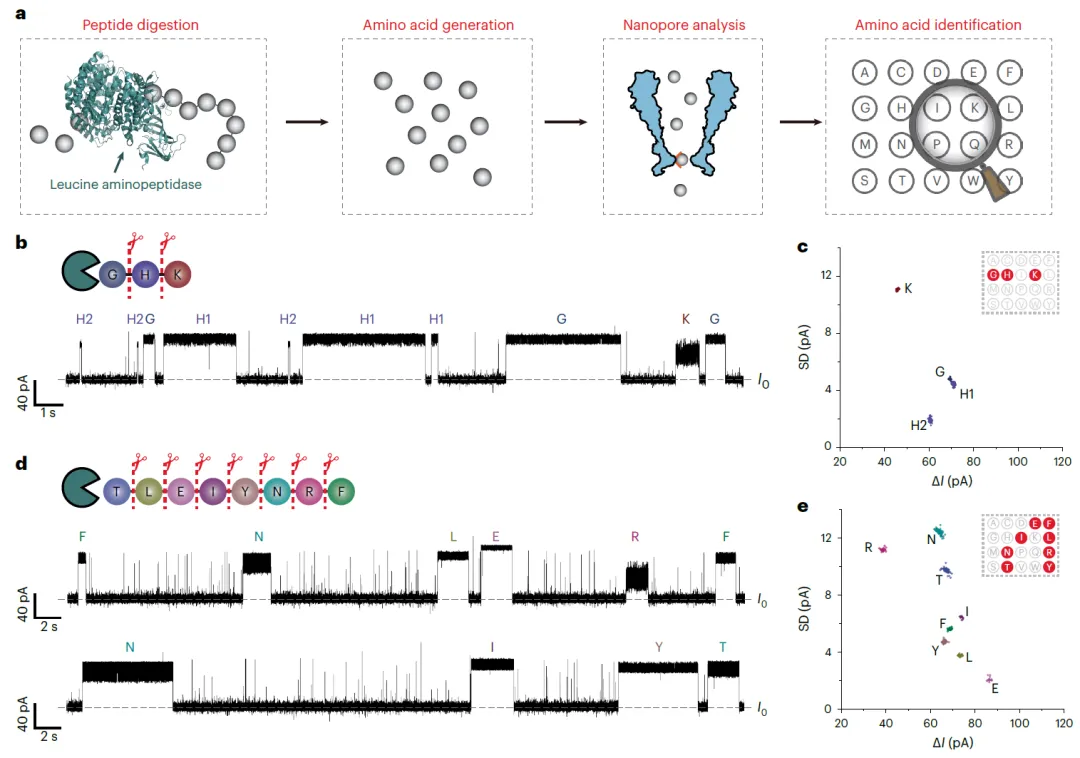
更重要的是,该研究展示了一条通往蛋白质测序的可行路径。使用亮氨酸氨基肽酶将三肽和八肽消化成游离氨基酸后,利用该纳米孔进行检测,成功鉴定出了消化产物中的所有氨基酸成分,且结果与肽序列完全匹配。这验证了基于“水解测序”策略的可行性:未来若将蛋白酶与纳米孔偶联,即可实现对目标蛋白的逐步水解与氨基酸的实时、顺序读取,从而达成单分子蛋白质测序。
点评与总结:
该研究报道了一种工程化的MspA-NTA-Ni纳米孔传感器,首次实现了对所有20种蛋白质氨基酸及其多种翻译后修饰的同时、高精度、单分子区分。其成功关键在于:锥形MspA孔道对离子电流的聚焦效应,放大了传感信号;单一的Ni²⁺修饰位点提供了稳定且特异的氨基酸结合口袋,产生了高度一致的特征事件;机器学习算法有效挖掘了多维事件特征,实现了自动化精准分类。这项工作突破了纳米孔蛋白质传感领域长期存在的分辨率瓶颈,不仅为复杂生物样本中氨基酸的直接鉴定提供了新工具,更为实现最终的单分子蛋白质全长测序铺平了道路。
声明:
1. 本文版权归原作者所有,若公众号或其他媒体需要转载,请务必与我们联系并获得授权。
2. 文中难免存在不足或疏漏,敬请读者批评指正。
3. 本文主要参考相关文献资料,仅用于科学研究的介绍与学习分享,不得用于任何商业用途。如涉及版权问题,请及时与我们联系。
Wang K, Zhang S, Zhou X, et al. Unambiguous discrimination of all 20 proteinogenic amino acids and their modifications by nanopore. Nat Methods, 2024. DOI: 10.1038/s41592-023-02021-8