第一作者: Ziang Zhu
通讯作者: 王瑾丰
DOI: https://doi.org/10.1021/acs.est.5c15251
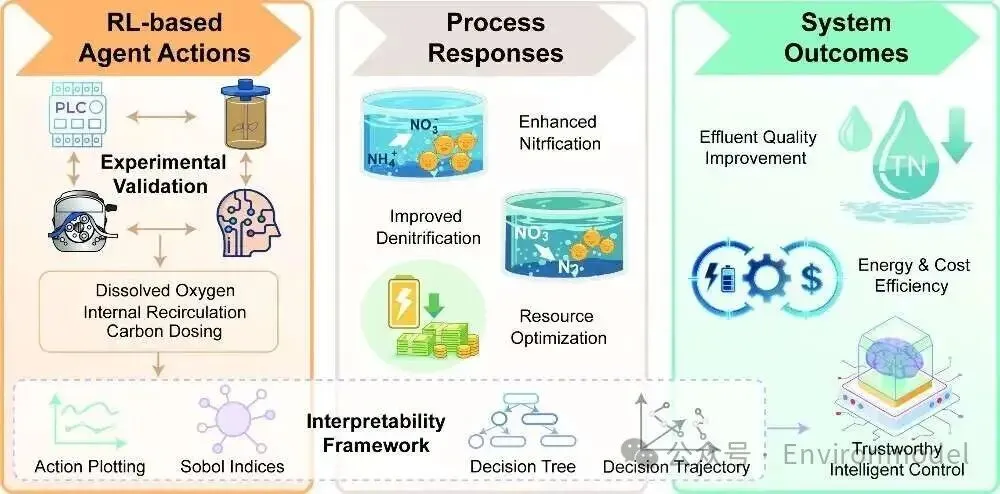
内容速览
文字摘要
强化学习智能体的智能控制与优化已成为生物营养物去除过程中极具前景的框架。然而,现有的大多数研究仍局限于模拟环境,这限制了其实际可信度和工程相关性。此外,强化学习智能体的黑盒性质也阻碍了操作人员的信任。本研究建立了一个反应器-智能体集成系统,实现了物理生物反应器与基于强化学习的智能体之间的直接交互,证明了基于智能体的控制在应对进水扰动方面优于传统策略。实验结果表明,在短期扰动下,与基于知识的控制相比,基于强化学习的控制使氮类物质超标减少了约30%,同时通过协调调整溶解氧设定点和内部混合液回流,实现了36.5%的运营成本下降。为了增强可解释性,本研究提出了一种分析框架,将算法智能与工艺工程的透明度联系起来。该框架结合了控制器动作可视化、替代决策树、Sobol敏感性分析和决策轨迹分析,以阐明强化学习智能体的决策逻辑,并将其与过程动力学和控制原理相关联。这些洞察将强化学习策略从黑盒转化为可解释、符合工艺逻辑且可审计的控制策略。总体而言,结果证明了基于智能体的智能控制在真实环境条件下的可行性、鲁棒性和透明度,为其在全面规模污水处理厂的可靠部署铺平了道路。
图片摘要
 img
imgKeywords
Agent-Based Control; Optimization; Biological Nutrient Removal; Accelerated Recovery after Disturbance; Enhanced Transparency; Improved Credibility
研究背景
生物废水处理的控制优化正不可避免地从基于规则的自动化转向基于智能体的智能控制。虽然自动化控制系统在操作稳定性和一致性方面具有优势,但在处理非线性过程动态和快速变化的进水条件时仍存在局限。相比之下,基于智能体的智能控制提供了卓越的适应性和决策自主性,能够有效应对工艺过程变异性、多目标权衡和进水特征的不确定性等重大挑战。
尽管如此,目前大多数用于生物营养物去除的强化学习智能体应用仍局限于模拟环境。模型与实际之间的偏差往往导致模拟策略无法准确捕捉现实工艺的复杂性,因此实验验证对于证明强化学习智能体能够适应性地调节溶解氧设定点和内部回流等关键变量至关重要。尤其是在动态应对水力负荷峰值或底物波动、实现有效脱氮与控制外部碳源投加成本之间寻求平衡,需要通过物理反应器的实际验证来确认控制策略在真实工况下的可行性与鲁棒性。
另一个阻碍强化学习智能体部署的主要障碍是其算法的黑盒性质。由于缺乏可解释性,操作人员对该系统在真实污水处理操作中的信任度较低。黑盒模型不仅难以进行与控制动作相关的机理分析,也缺乏能够直观总结主要决策逻辑的方法,导致无法将算法行为有效地与现有控制系统进行整合与知识转移。此外,理解不同变量在制定控制策略中的相对重要性,以及探究智能体如何与环境交互以实现多目标优化,对于全面解析决策机制不可或缺。因此,强化学习智能体必须具备高度可解释性,使得控制与决策逻辑能够被工程师完全理解和审计。
主要研究手段
本研究构建了一个实验室规模的反应器系统以验证生物营养物去除系统的智能体控制优化。该反应器采用了厌氧-缺氧-好氧-缺氧配置,通过引入第二个缺氧区来提高脱氮效率并进一步去除残留营养物。系统使用当地污水处理厂的真实废水作为进水,并根据批次进行分时段进料,从而在确保每个测试周期内水质稳定性的同时,引入了批次间的自然浓度波动,以便全面评估控制策略的泛化能力。
在控制架构方面,物理反应器与强化学习智能体通过可编程逻辑控制器等基础设施实现了闭环集成。算法核心采用基于深度Q网络架构的混合建模框架,并与SUMO过程模拟平台进行交互学习。研究设置了两个场景:场景一侧重于实验室规模反应器的实验验证,主要测试不同水力扰动流态下单变量维度的控制响应;场景二完全在模拟环境中运行,引入了降雨引发的流量与浓度双重突变及低碳氮比条件,加入了外部碳源投加作为额外的控制维度。
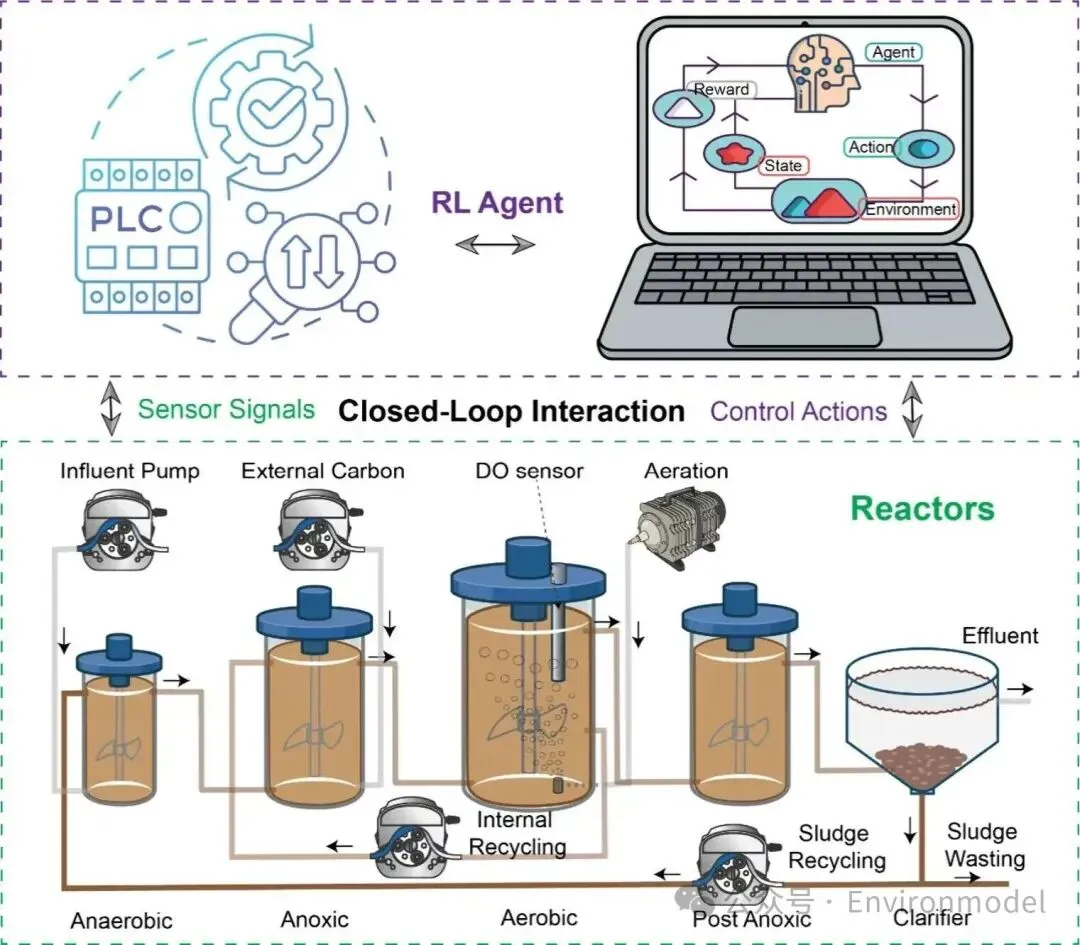
该图表展示了实验室规模反应器与强化学习智能体的闭环集成原理。系统实时采集传感器和泵的状态信号传输给强化学习智能体,智能体据此计算出最优控制动作,指令随后下发至底层控制器以调整物理设备的运行状态。这种设计在物理生化过程与智能数据决策之间建立了连贯的通信通路。
 img
img图 1. 实验室规模反应器与强化学习智能体的闭环集成。强化学习智能体接收来自传感器和泵的实时信号并确定最佳控制动作。然后反应器执行相应的操作调整,从而在物理过程和基于强化学习的智能决策之间建立连续的反馈回路。
为了打破黑盒算法的不透明性,研究引入了系统的可解释性分析框架。该框架采用了四种互补的可解释性工具,包括控制器响应与进水动态的聚类可视化、替代决策树建模、Sobol敏感性分析以及决策轨迹分析。这些方法协同工作,不仅量化了系统状态如何被智能体感知,也揭示了不同输入变量的优先级排序,最终清晰地描绘了复杂工况下控制动作的演变与选择过程。
主要结论
实验验证表明,在短期水力负荷扰动下,基于强化学习的控制策略显著优于静态及基于知识的传统策略。强化学习智能体通过对溶解氧设定点和内部混合液回流比例进行动态联合调控,有效地削减了出水水质峰值,加速了系统各项指标恢复至合规限值的进程。通过这种智能协同调节,强化学习控制在提高出水水质指数的同时,大幅降低了包含曝气和泵送在内的运营成本与能耗,实现了资源利用的高度可持续化。
该图表对比了三种不同控制策略在模拟降雨水力扰动工况下的出水表现与整体效能指标。图表详尽分析了进水流量突增对出水氨氮及总氮浓度的瞬时影响。数据验证了强化学习控制器在缩减污染物超标时间段上的卓越表现,并展示了其在提升整体水质与降低综合系统功耗层面的显著统计学优势。
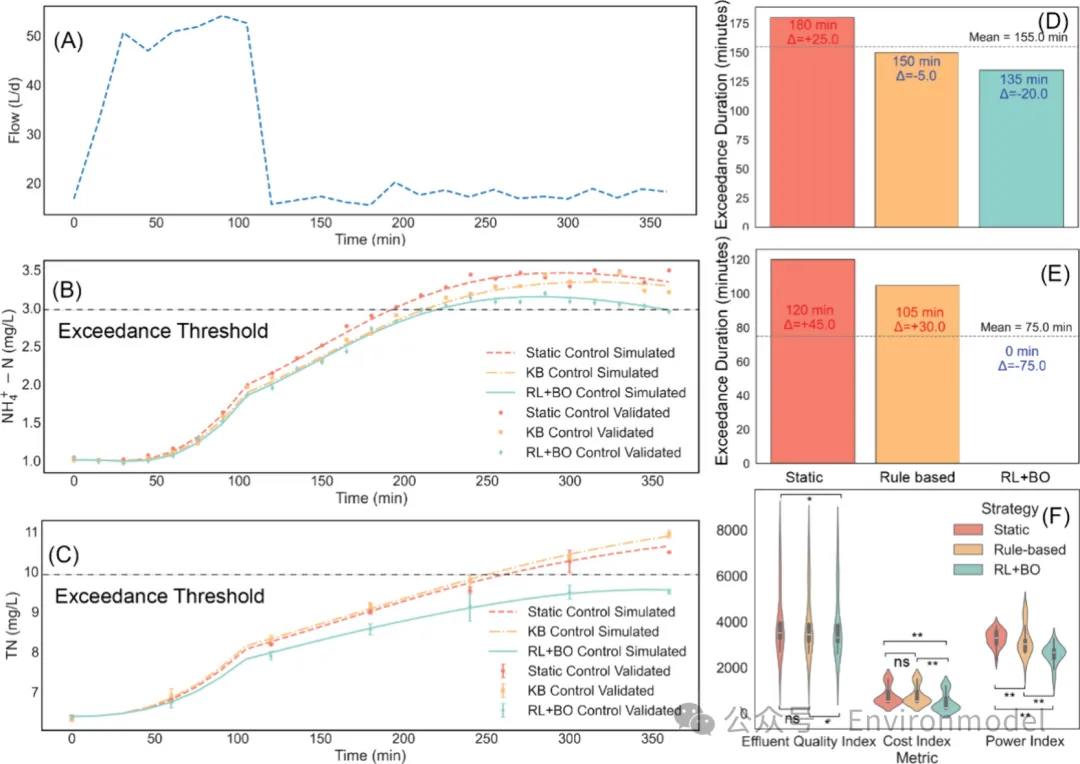 image-20260320144710940
image-20260320144710940图 2. 强化学习控制策略与静态和基于知识的策略在动态进水流量条件下的性能对比。(A) 模拟降雨引起干扰的进水流量曲线。(B, C) 出水氨氮和总氮浓度时间序列:不同控制策略下的模拟值与测量值,并标注了排放阈值。(D, E) 柱状图说明了每种控制策略下氨氮和总氮的超标持续时间,突出了基于强化学习的控制器在扰动恢复方面的改进。(F) 三种控制策略实现的 EQI、CI 和功率指数的性能。统计显著性表示为 * p < 0.05, ** p < 0.01。
可解释性分析的结果表明,强化学习控制的优越性源于其更广泛且连续的动作空间以及更深层的决策逻辑。替代决策树模型成功将黑盒策略转化为了直观的规则表达,显示出结合贝叶斯优化的强化学习策略具备更简洁均衡的决策结构和更高的预测一致性。Sobol敏感性分析进一步指出,优化后的强化学习策略大幅提升了对进水流量等核心水力负荷指标的感知敏感度,从而能够更前瞻性地分配控制动作。
该图表呈现了仅采用强化学习与结合贝叶斯优化强化学习策略在替代决策树建模及敏感性特征层面的差异。图表左侧对两种策略的决策树深度及分支阈值进行了拆解,右侧则利用Sobol敏感性指数的柱状分布,直观说明了不同策略下状态变量对最终控制决策主效应及交互效应贡献度的根本性转变。
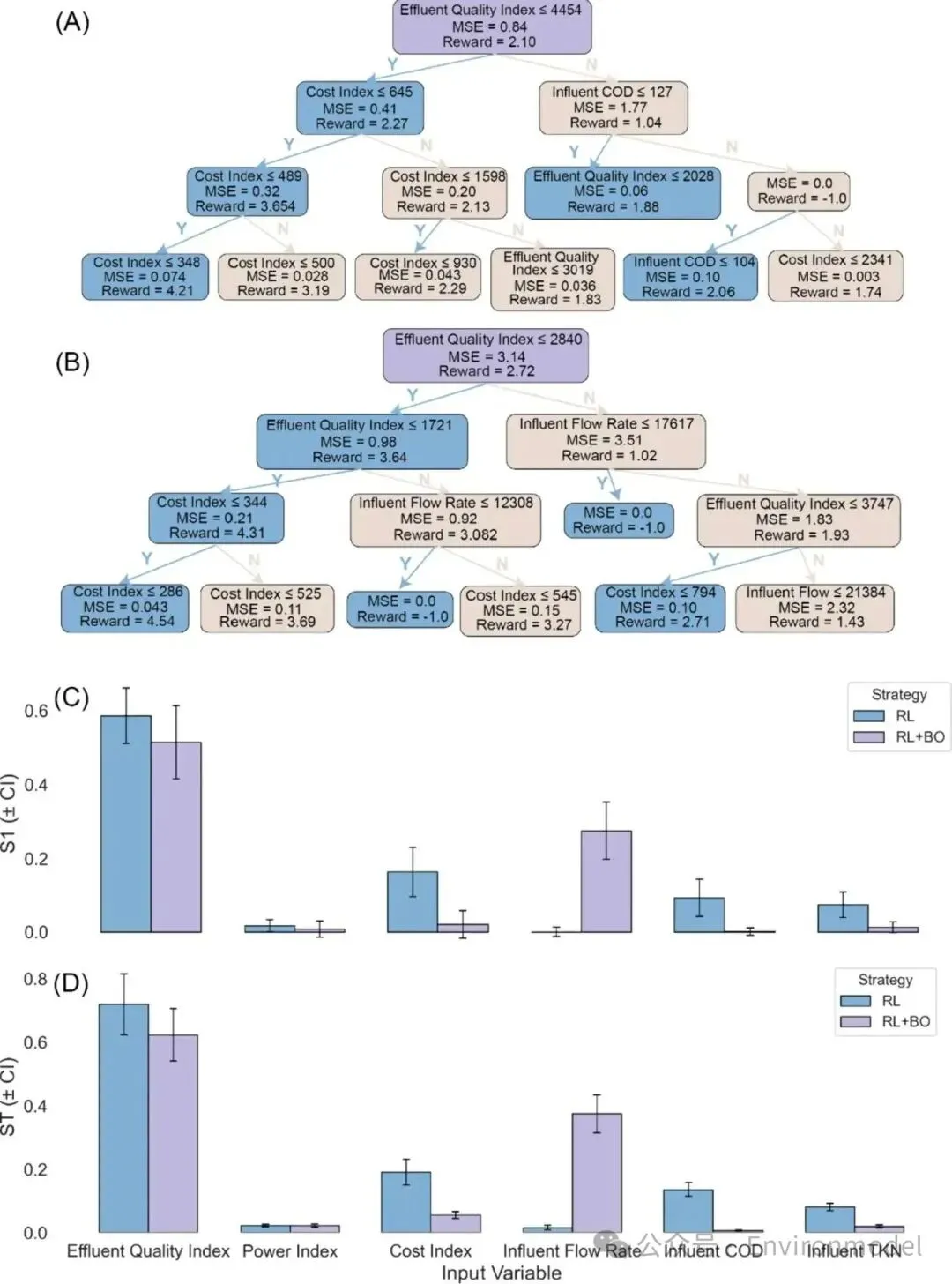 image-20260320144724190
image-20260320144724190图 3. 使用替代决策树和 Sobol 敏感性指标对仅使用 RL 和 RL+BO 控制策略进行可解释性分析。(A) 拟合到仅 RL 策略的决策树模型。(B) RL+BO 策略的决策树,其显示出更简洁的结构和更清晰的决策边界。(C) 反映单个变量主要影响的一阶 Sobol 指数 (S1)。(D) 总阶 Sobol 敏感性指数 (ST),用于量化输入变量对奖励的组合交互影响。
决策轨迹分析动态验证了智能体在复杂工况下的调控一致性。面对不同极端进水情景(特别是低碳氮比条件),结合贝叶斯优化的强化学习智能体能够迅速收敛到一条极其平滑且回报率最优的控制路径上,避免了无效的策略试错与波动。这种将抽象控制转化为符合硝化反硝化机理的工程可视化的方法,极大增强了策略的可审计性,证明了强化学习具备作为现代污水处理厂中坚实且透明的决策支持工具的潜力。
该图表展示了强化学习与结合贝叶斯优化的强化学习在四种不同进水冲击情景下控制响应的三维演化过程。图表精准描绘了在有限的试错步骤内,不同策略在溶解氧设定、混合液回流以及外部碳源投加三个维度上的空间移动路径。轨迹的紧凑程度直接反映了控制系统面对复杂约束时迅速寻优并稳定维持高回报运行状态的算法韧性。
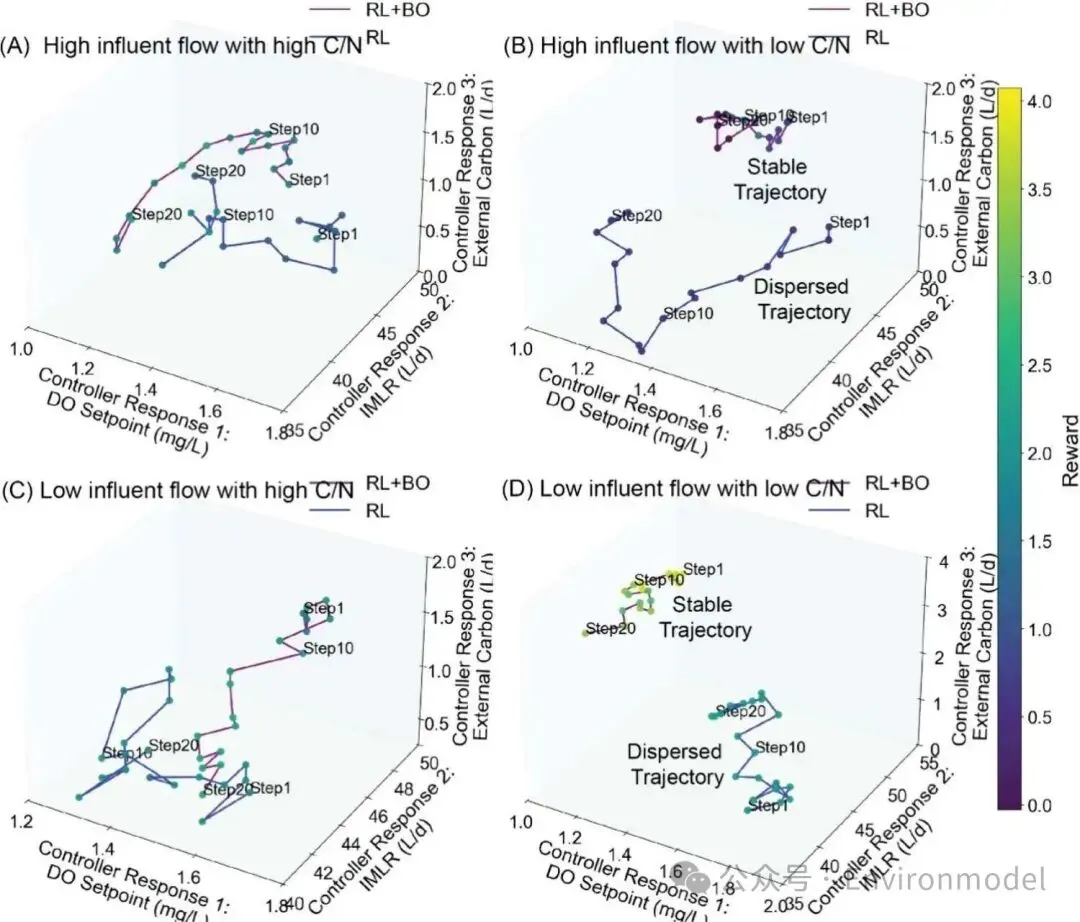 img
img图 4. RL 和 RL+BO 策略在四种进水情景下的控制决策轨迹比较。每个子图代表在不同的进水流量和碳氮比条件下,20 个决策步骤中三个控制动作的 3D 轨迹。RL+BO 表现出更稳定、与奖励一致的控制路径,表明在不同运行状态下提高了泛化能力和策略可解释性。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
