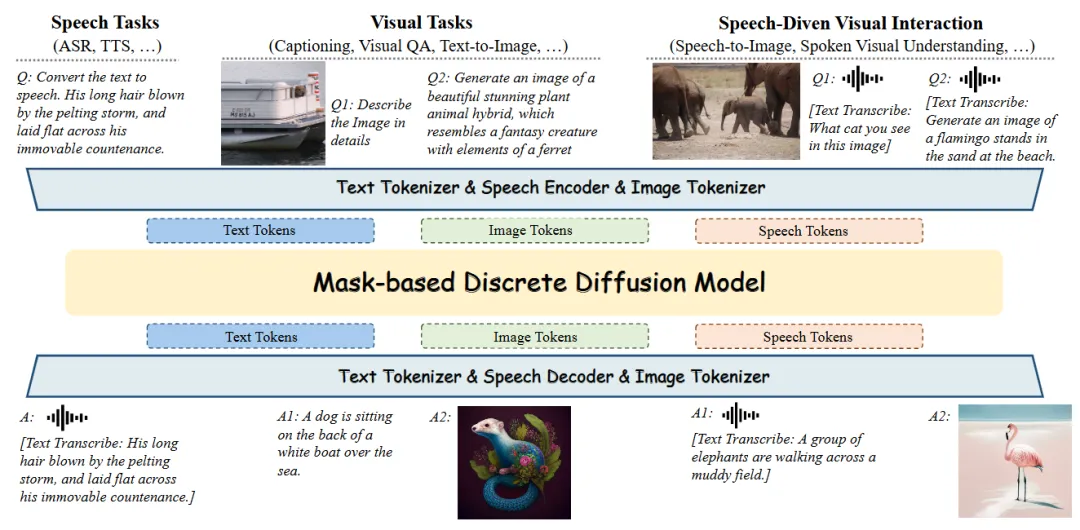
想象一下,你对着手机说一句"画一只站在沙滩上的火烈鸟",AI没有逐字逐句地"憋"回答,而是像拼图复原一样,从模糊到清晰,直接把图像和语音同时推到你面前。更夸张的是,它还能反过来——听你描述、看你上传的照片、再用语音告诉你里面有什么。论文链接:https://arxiv.org/pdf/2603.06577v1github链接:https://github.com/VITA-MLLM/Omni-Diffusionhuggingface链接:https://huggingface.co/lijiang/Omni-Diffusion这不是科幻,而是南京大学与腾讯优图实验室最新发布的Omni-Diffusion正在做的事。作为首个完全基于掩码离散扩散模型的Any-to-Any多模态系统,它第一次证明:不依赖传统的自回归架构,AI也能同时玩转文本、语音和图像的理解与生成。
自回归"一统天下"的局面,被扩散模型撕开了口子
过去几年,如果你关注多模态AI,会发现一个奇怪的现象:不管是能看图说话的GPT-4V,还是能语音对话的VITA,骨子里几乎都是同一套自回归架构的变体。
研究者们的做法高度一致——找一个预训练好的大语言模型当"主脑",再给它接上图像编码器、语音解码器等各种"外挂"。模型先理解你的问题,然后从左到右、一个字一个字地"憋"出回答,最后再通过额外的输出头把文本隐藏状态转换成图像或语音。
这套方案确实有效,但它有一个天然的瓶颈:生成是串行的。
就像一个人说话必须按顺序吐字,不能跳过也不能并行。更关键的是,现有方案本质上是让LLM只负责文本生成,其他模态的数据被压缩成文本的"附属品",通过投影层来回转换。这种"文本中心主义"的设计,让不同模态之间的语义对齐始终隔着一层窗户纸。
与此同时,另一条技术路线正在悄然崛起。
扩散模型在图像生成领域已经杀疯了,Midjourney、Stable Diffusion的出图质量有目共睹。更令人意外的是,近几个月扩散模型开始"跨界"进军自然语言处理,Dream-7B等离散扩散语言模型证明:不采用自回归,AI也能生成流畅文本,而且支持并行解码、生成轨迹可控。
但把扩散模型同时用于文本、语音、图像三种模态,并且实现任意模态输入到任意模态输出,这在Omni-Diffusion之前几乎没人做到。南京大学与腾讯优图实验室的这项研究,第一次把掩码离散扩散模型推上了Any-to-Any多模态系统的中心位置。它不是给自回归模型打补丁,而是直接换了一条路:用统一的扩散 backbone,同时建模文本、语音和图像的联合分布。
Figure 1:Omni-Diffusion整体架构示意图,展示模型统一处理文本、图像、语音三类模态的输入输出流程
这意味着什么?简单来说,以前的多模态模型是"一个翻译官带多个秘书",而Omni-Diffusion试图成为"一个真正精通三门语言的人"。
Omni-Diffusion的核心设计:把三种模态"压"进同一套token体系
那么,Omni-Diffusion到底怎么把三种截然不同的数据"塞"进同一个模型里?答案是把所有模态都压扁成离散token。
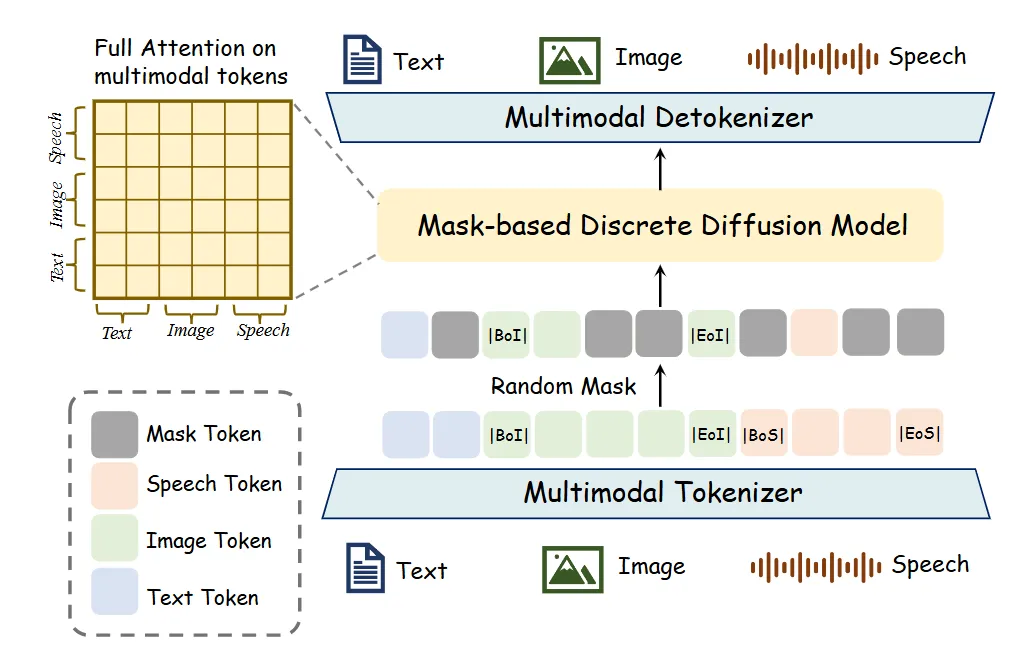
论文里的思路非常直接:文本、语音、图像,本质上都可以被切分成一串离散的符号。Omni-Diffusion没有走"LLM生成文本再投影"的老路,而是直接学习这些离散token的联合分布。具体来说,模型会把输入的文本、语音波形和图像像素,分别送进各自的tokenizer,变成三组token序列。然后,这些token被特殊的起始符和结束符包裹,拼接成一条统一的序列。
这里的技术细节值得拆开看看。
图像方面,团队用了预训练的MAGVIT-v2作为图像tokenizer,把图像压缩成离散token,下采样因子是16,codebook大小8192。也就是说,一张图最终被表示成一串取自8192个视觉"单词"的序列。
语音方面,编码用SenseVoiceSmall提取语义特征,再通过轻量MLP适配到模型的隐藏维度;生成时则用GLM-4-Voice的tokenizer把语音转成离散token,codebook大小16384,采样率12.5Hz。
文本则直接基于预训练的Dream-7B离散扩散语言模型。
最关键的设计在模型 backbone 里。
Omni-Diffusion采用掩码离散扩散的范式:训练时,从统一序列中随机选一部分token替换成[MASK],然后让模型根据上下文预测这些被遮住的原始token。损失函数是简单的交叉熵,但只计算被mask位置上的误差。不管这个token来自文本、图像还是语音,训练方式完全一样,没有模态专属的优化目标。
Figure 2:Omni-Diffusion架构详解图,展示多模态tokenizer、掩码扩散模型与detokenizer的完整数据流
这种设计的聪明之处在于,它让模型在训练过程中自发地学到一个内在对齐的语义空间。因为文本token和图像token是在同一个序列里被联合预测的,模型不得不理解"这个词"和"那个像素块"之间的对应关系。相比之下,传统方案里不同模态的信息要在LLM的隐藏层里"挤"在一起,对齐效果很大程度上取决于投影层的设计。
论文里特别强调,这种联合分布建模与现有方案有本质区别。NExT-GPT等模型虽然也能做Any-to-Any,但它们依赖冻结的LLM生成文本,再通过适配器驱动外部的扩散解码器。NExT-Omni用了离散流匹配,但 backbone 仍然是纯文本的。而Omni-Diffusion从token化到生成,全程都在同一个掩码扩散框架里完成,没有"内外之分"。
当然,把三种模态硬塞进同一套token体系,训练稳定性是个大问题。团队为此设计了一套三阶段渐进训练策略。
三阶段"渐进式"训练:从图文对齐到语音视觉联合,再到跨模态交互
把文本、语音、图像三种数据直接倒进同一个模型里开训,结果大概率是灾难性的。三种模态的分布差异极大,模型很容易陷入"顾此失彼"的泥潭。Omni-Diffusion的解法很务实:一步一步来,先学会两门,再学第三门,最后让它们联动起来。
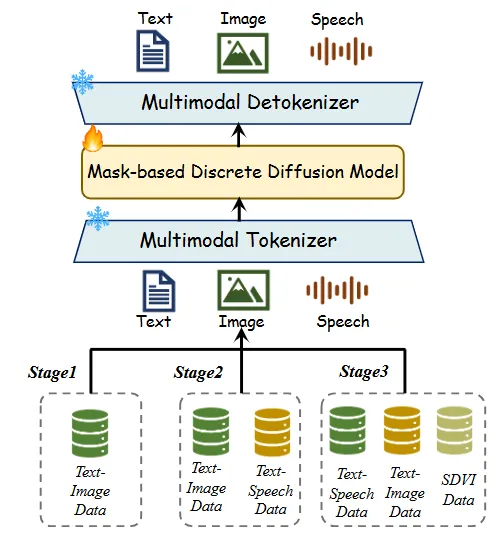
第一阶段叫视觉-语言预对齐。团队保留了预训练好的Dream-7B语言能力,然后只用文生图和图像描述的数据来训练。这一步的目标很明确:让模型先"认识"图像token长什么样,建立文本和视觉之间的初步映射。相当于给扩散语言模型配了一副眼镜,让它从"只会写字"变成"能看图说话"。
第二阶段升级为语音-视觉-语言联合对齐。在保留第一阶段图文数据的基础上,引入自动语音识别(ASR)和文本转语音(TTS)任务。这时候模型开始同时处理三种模态,但任务相对"单纯"——主要是文本和语音之间的双向转换,以及已经熟悉的图文交互。这一步相当于让模型学会"听"和"说"。
真正的难点在第三阶段:语音驱动视觉交互能力强化。这里需要模型同时理解语音指令、分析图像内容、再生成跨模态的输出。为了这一步,团队专门构建了一个SDVI数据集(Speech-Driven Visual Interaction)。
他们从LLaVA-OneVision里取了问答对,用CosyVoice2把问题合成为语音,过滤掉数学计算和编程题,把选择题改成开放式问答,再砍掉答案超过100字的样本,最终得到3万多条口语化视觉问答数据。另外还从Blip3o-JourneyDB里做了3万条语音到图像的生成数据。
Figure 3:Omni-Diffusion三阶段渐进训练流程图,展示从图文对齐到语音视觉联合再到跨模态交互的数据扩展过程
训练策略上还有一个细节值得注意。扩散模型在训练时通常会在序列末尾填充随机数量的pad token,让模型适应变长生成。但团队发现,如果pad token和正常token被同等概率地mask,模型会过拟合pad token,推理时疯狂输出pad。
于是他们提出了衰减尾部填充掩码策略:给pad token的mask比例乘上一个小于1的衰减因子(实际设为0.6),让梯度更新主要由语义token驱动。这个看似微小的调整,直接解决了生成结果里"废话连篇"的问题。
实测结果:文生图、语音生图、视觉问答、语音合成,一个模型全包
练完了,得拉出来遛遛。Omni-Diffusion的评测结果相当能打,而且不是"偏科生",是全科优等生。
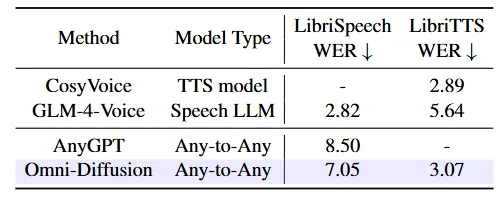
先看语音任务。在LibriSpeech语音识别基准上,Omni-Diffusion的词错误率(WER)降到了7.05%,而作为对比的Any-to-Any模型AnyGPT是8.50%。在语音合成方面,LibriTTS上的WER为3.07%,已经非常接近专门的TTS专家模型CosyVoice的2.89%,并且大幅优于语音大模型GLM-4-Voice的5.64%。一个模型同时做识别和合成,还能逼近专家水平,这本身就说明了扩散架构在语音上的潜力。
Table 1:Omni-Diffusion在LibriSpeech和LibriTTS上的ASR与TTS性能对比表,WER越低越好
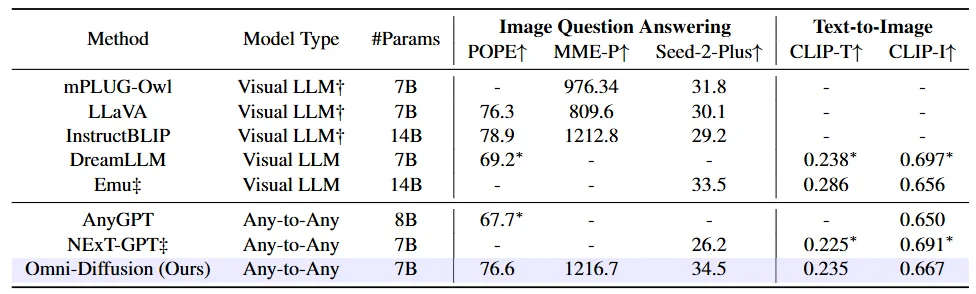
视觉任务的成绩同样亮眼。在视觉问答(VQA)评测中,Omni-Diffusion在POPE上拿到76.6分,在MME-Perception上拿到1216.7分,在Seed-2-Plus上拿到34.5分。MME-Perception这个分数是什么概念?它几乎追平了14B参数的InstructBLIP(1212.8),并且超过了14B Emu的33.5。而在文生图任务上,MSCOCO验证集上的CLIP-T达到0.235,CLIP-I达到0.667,文本-图像对齐度明显优于其他Any-to-Any模型。
Table 2:Omni-Diffusion在VQA和文生图任务上的性能对比表,涵盖POPE、MME、Seed-2-Plus及CLIP分数
更关键的是语音生图的测试。团队把MSCOCO的文本描述转成语音,再让模型根据语音生成图像。结果显示,语音驱动生成的图像在CLIP-T和CLIP-I指标上与文本驱动几乎持平。这意味着,模型不是简单地"听到语音先转文字再画图",而是真正在共享的语义空间里,把语音和图像直接关联了起来。
Figure 5:Omni-Diffusion文本生图与语音生图效果对比,上下两行展示相同语义输入下的生成一致性
除此之外,Omni-Diffusion还自带两个"彩蛋"。
第一个是图像修复(inpainting)。由于扩散模型的掩码预测机制,直接把图像的未知区域填成[MASK],模型就能无缝补全内容,不需要额外训练。
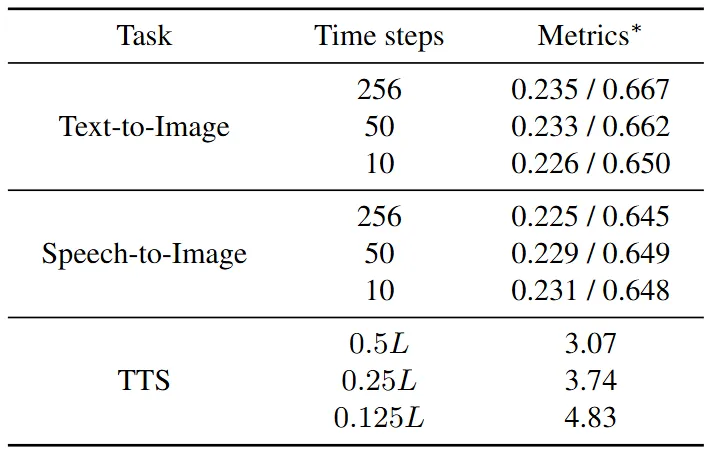
第二个是采样效率。传统自回归模型必须逐token生成,而扩散模型可以并行解码。实验显示,文生图任务从256步压缩到10步,图像质量依然可用;TTS任务用0.25倍序列长度的步数,性能也保持稳定。
Figure 6:Omni-Diffusion图像修复示例,左为原图与掩码,右为模型根据提示补全后的结果
Figure 7:Omni-Diffusion在不同采样步数下的文生图效果对比,展示10步即可生成高质量图像
不止于"全能":推理阶段的三个巧思,让它又快又稳
如果说训练决定了模型的天花板,那么推理设计决定了它能不能落地。Omni-Diffusion在推理阶段做了几件事,件件都打在扩散模型的痛点上。
首先是位置惩罚。团队发现,扩散模型解码时喜欢从序列两端向中间同步推进,导致生成的图像上下区域出现重复图案。于是他们给序列末尾的token logits乘上一个小于1的衰减因子,软性约束生成顺序,而不是强行分块自回归。这个小调整直接改善了视觉质量。
其次是特殊token预填充。语音对话有个麻烦:模型得同时输出文本和语音,两者长度比例不固定。Omni-Diffusion在初始mask序列的1/4位置硬塞一个[begin-of-speech]token,强制前1/4生文本、后3/4生语音。这样模型在合成语音时能明确"看到"自己要说的文字内容,逻辑连贯性大幅提升。配合自适应token长度分配——TTS时初始长度设为文本的3.5倍,ASR时设为语音的0.2倍——采样步数被大幅压缩。
Table 3:Omni-Diffusion在不同采样步数下的图像生成与TTS性能表,验证扩散模型的并行解码效率优势
这些技巧叠加的效果很直观。文生图任务里,采样步数从256砍到10步,CLIP分数只是轻微下滑,图像依然可用;TTS任务用0.25倍序列长度步数,词错误率保持稳定。更妙的是,基于mask预测机制,Omni-Diffusion无需额外训练就能做图像修复:把想改的区域直接填成[MASK],模型根据周围像素和文本提示自动补全。
Figure 4,注释:Omni-Diffusion语音视觉交互示例,模型根据口语提问分析图像内容并生成语音回答
结语:多模态大模型的架构之争,或许才刚刚开始
Omni-Diffusion的实验结果传递了一个清晰的信号:扩散模型完全有资格成为多模态系统的基础 backbone。它不是在某个单项上刷榜,而是证明了统一架构下,文本、语音、图像的理解与生成可以共享同一套概率建模框架。
当然,这并不意味着自回归架构就此退场。
两种路线各有优劣:自回归在长文本连贯性上仍有优势,扩散模型在并行解码和生成可控性上更灵活。但至少,多模态AI的架构设计不再是"单选题"。
当研究者不再执着于给LLM接外挂,而是从头设计一个真正"模态平等"的联合分布模型时,下一代Any-to-Any系统的可能性空间,正在被重新打开。
持续关注本公众号【赛博雷达】,我们会第一时间拆解更多前沿开源模型、本地AI实战和Agent最新进展。喜欢这篇文章就点个关注+转发给正在专注AI的朋友,一起拥抱这个免费又强大的AI核弹!
感谢阅读,我们下期见~