南京信息工程大学|基于多边形编码和改进深度可学习相似性网络的大容量H.265/HEVC视频隐写(IEEE TDSC 2026)
一、方法简介
现有基于P帧PU划分模式的H.265/HEVC视频隐写算法主要面临两方面关键挑战:一是嵌入容量受限。虽然已有方法通过构建不同的映射策略来提升PU划分模式对秘密信息的表达能力,但由于映射机制设计不够合理,PU模式之间的组合潜力未被充分挖掘,导致整体嵌入效率仍然有限;二是视觉质量不足。在隐写过程中,对PU划分模式的修改会破坏原始编码决策的最优性,从而引入额外失真。尽管部分研究引入神经网络对含密视频进行后处理以缓解失真,但由于网络结构或特征建模能力的限制,其对复杂纹理和细节信息的恢复仍不充分,难以实现理想的视觉效果。因此,如何在提升嵌入容量的同时兼顾视频视觉质量,成为当前亟待解决的问题。
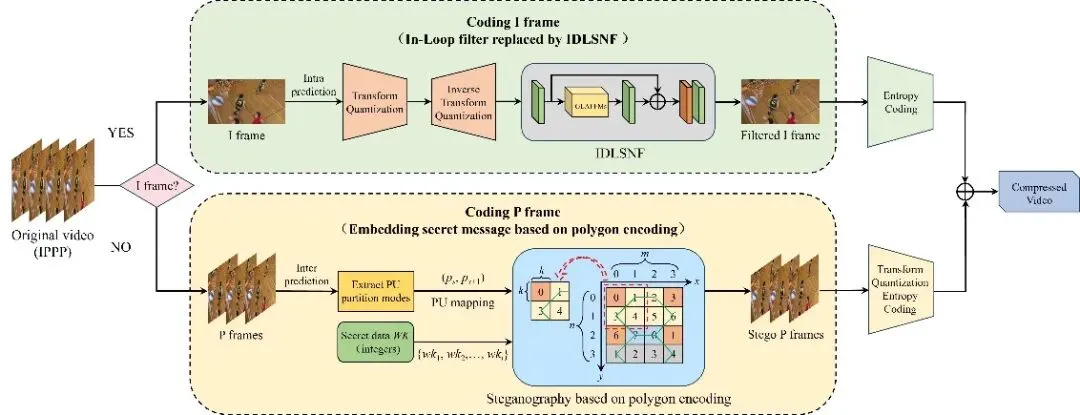
图1 隐写方法框架
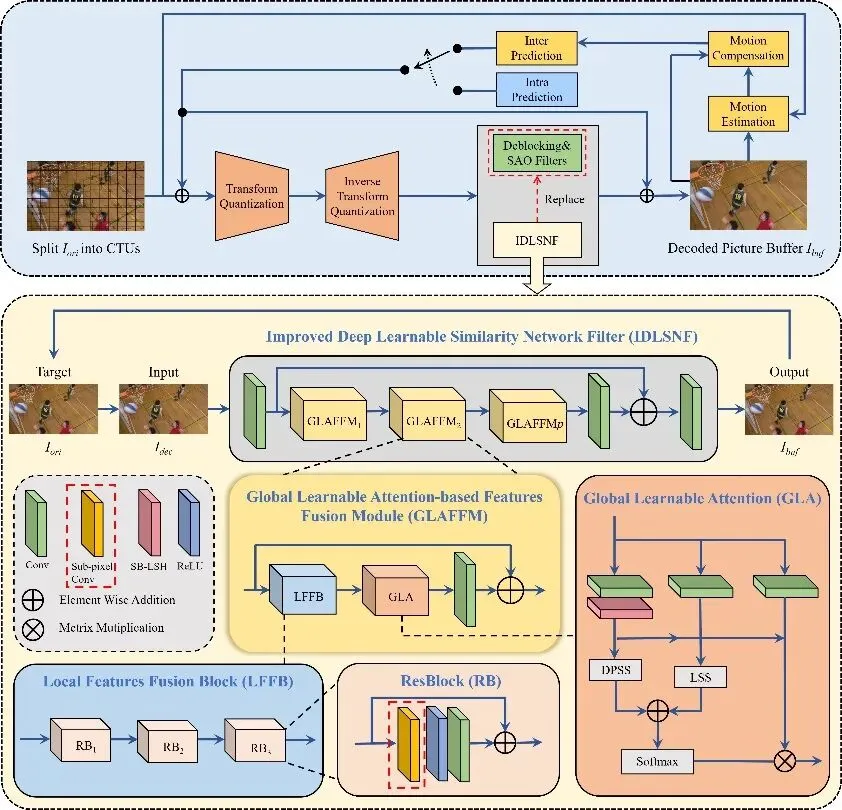
针对上述问题,本文提出了一种基于多边形编码与改进深度可学习相似性网络滤波器(IDLSNF)的H.265/HEVC视频隐写方法(如图1)。在容量提升方面,构建二维坐标系并设计新颖的多边形编码规则,将不同整数映射为多边形中的唯一元素,并利用P帧中相邻PU划分模式分别对应横纵坐标,实现信息的联合表达与嵌入。该方法充分挖掘PU模式之间的组合关系,有效提高编码空间利用率,从而提升嵌入容量并降低由模式修改带来的率失真开销。在视觉质量优化方面,本文对传统DLSN结构进行改进,提出IDLSNF模块(如图2),引入全局可学习注意力机制以捕获更丰富的非局部相关性,并以I帧为先验信息对重建过程进行引导,从而实现对高频细节与纹理信息的有效恢复。通过上述设计,所提方法在不同分辨率视频上均能在嵌入容量与视觉质量之间取得更优平衡。
图2 IDLSNF框架
二、实验评估
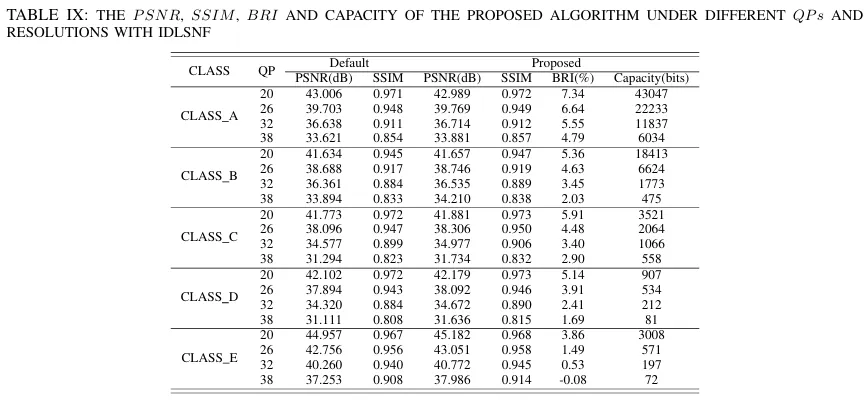
为了验证本文所提方法的性能,在H.265/HEVC参考软件HM 16.15平台上,选取14个经典YUV序列作为测试数据,开展了充分的实验评估。实验结果表明,该隐写方法在PSNR、SSIM和BRI等指标上均取得了显著性能提升(图3)。尤其是在IDLSNF模块的辅助下,含密视频的相关性能指标甚至优于原始H.265/HEVC编码结果。
图3 客观性能实验
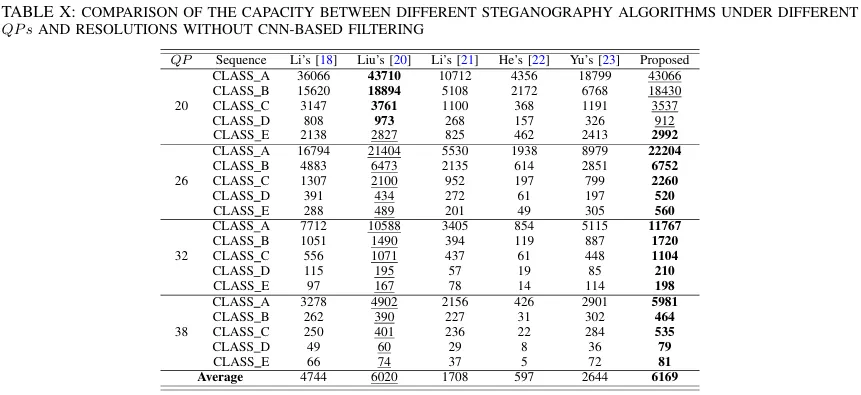
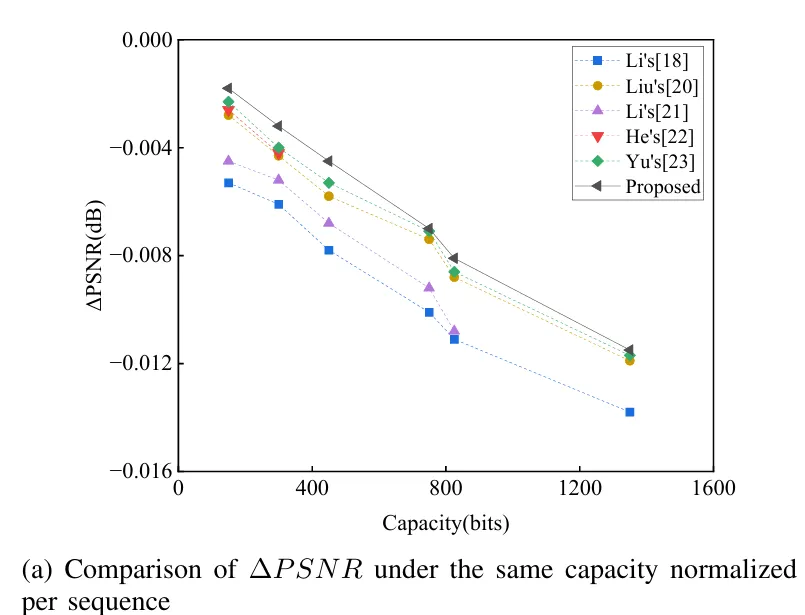
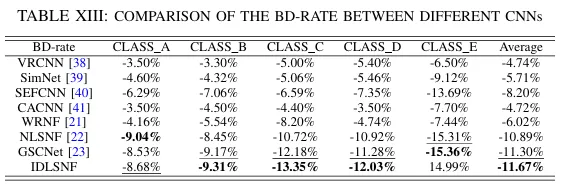
在与其他先进的基于P帧PU划分模式的隐写方法对比中,所提方法在嵌入容量(图4)和PSNR性能(图5)方面均表现出明显优势。另外,我们将设计的IDLSNF与其他研究中用于H.265/HEVC编码中的CNN网络进行了对比(图6),实验表明IDLSNF具有更优异的性能。
图4 嵌入容量对比试验
图5 PSNR对比试验
图6 网络对比试验
论文信息
该研究工作已被IEEE Transactions on Dependable and Secure Computing录用,作者为南京信息工程大学谢佳辰,张翔(通讯作者),付章杰,彭飞,王帆,黄文斌,付道勇,龙敏。
Jiachen Xie, Xiang Zhang*,Zhangjie Fu, Fei Peng, Fan Wang, Wenbin Huang, Daoyong Fu, Min Long, Large Capacity H. 265/HEVC Video Steganography Based on Polygon Encoding and Improved Deep Learnable Similarity Network, IEEE Transactions on Dependable and Secure Computing, 2026. https://doi.org/10.1109/TDSC.2026.3671762.
供稿:谢佳辰
义务编辑与校对:薛禹良博士