生信站,持续更新临床生信文献与思路解读,感兴趣的老师可以点点关注 🌈🌈扫描上方二维码,了解更多生信服务❤️❤️今天小星为大家带来的这篇文章堪称是纯生信的典范,跟着小星一起来看看它的发文亮点吧🌟🌟🌟❤️
🌈🌈扫描上方二维码,了解更多生信服务❤️❤️今天小星为大家带来的这篇文章堪称是纯生信的典范,跟着小星一起来看看它的发文亮点吧🌟🌟🌟❤️🌟方法学突破点
用传统的NHANES数据库,套上了“可解释机器学习(SHAP+LIME)”这个时髦方法。不仅是验证“运动有用、久坐有害”的老结论,还通过非线性拐点和个体化解释挖掘出了新意。这种“经典数据+前沿算法+打开黑箱”的套路,是目前生信和临床预测模型领域很讨喜的发文模板,复用性高,容易模仿和升级。
生信发文没思路或者需要数据分析生信服务的老师可扫码联系小星。🌈🌈
下面我们来看具体文章内容
文章标题:Physical activity and sitting time as correlates of cardiometabolic multimorbidity risk in U.S. adults: an explainable machine learning classification model using SHAP and LIME
中文标题:美国成年人心脏代谢多病风险的身体活动和久坐时间:基于 SHAP和LIME的可解释机器学习分类模型
发表期刊:BMC Public Health
发表时间:2026年4月
影响因子:3.6
研究背景
心血管代谢多病(CMM)已成重大公卫挑战,体力活动不足与久坐是关键可干预因素。现有研究多聚焦单一疾病,且传统回归难以处理非线性关系。为此,本研究基于NHANES数据,结合SHAP与LIME等可解释机器学习方法,系统评估体力活动及静坐时间与CMM的关联,并构建透明化的CMM分类模型。
研究方法
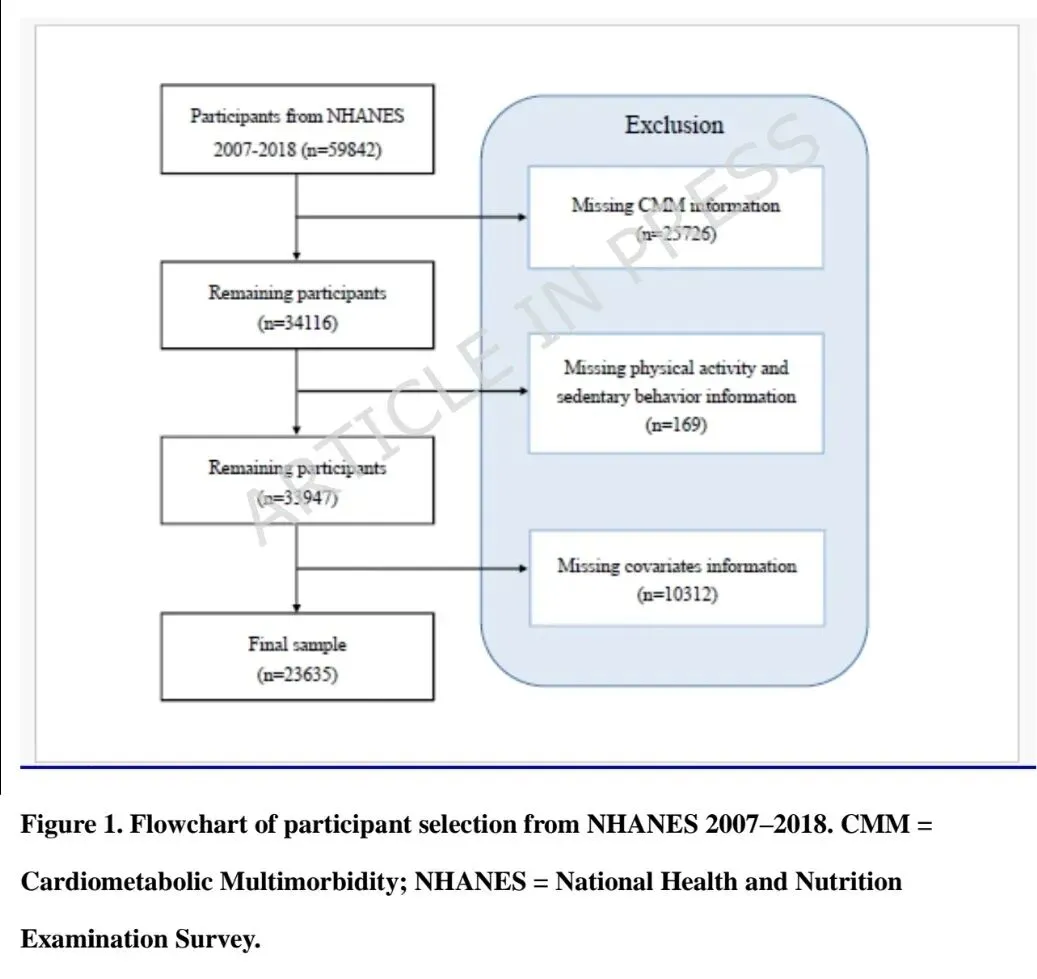
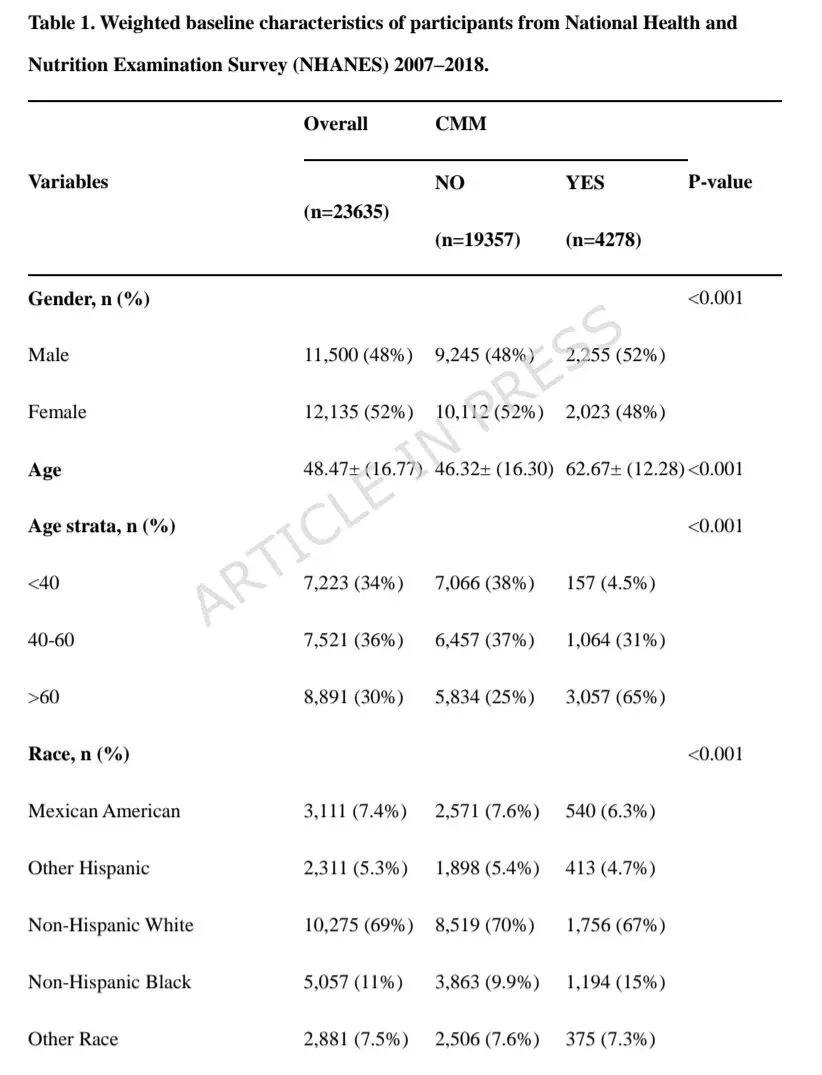
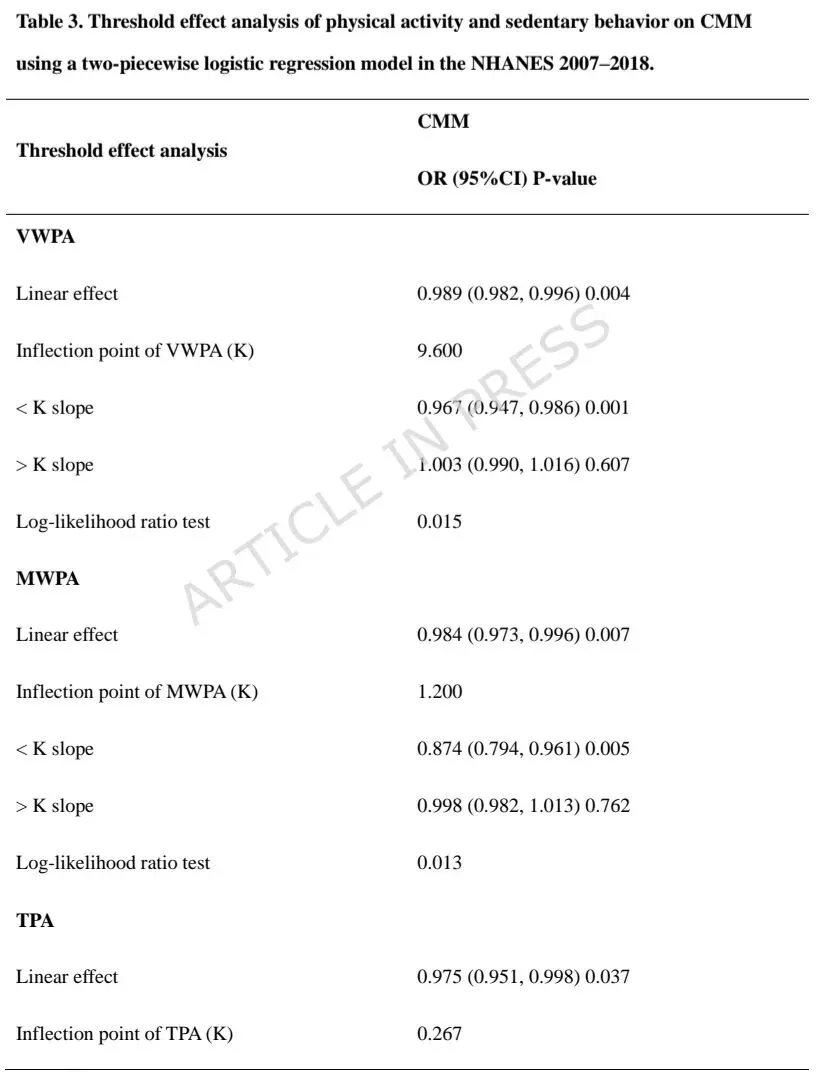
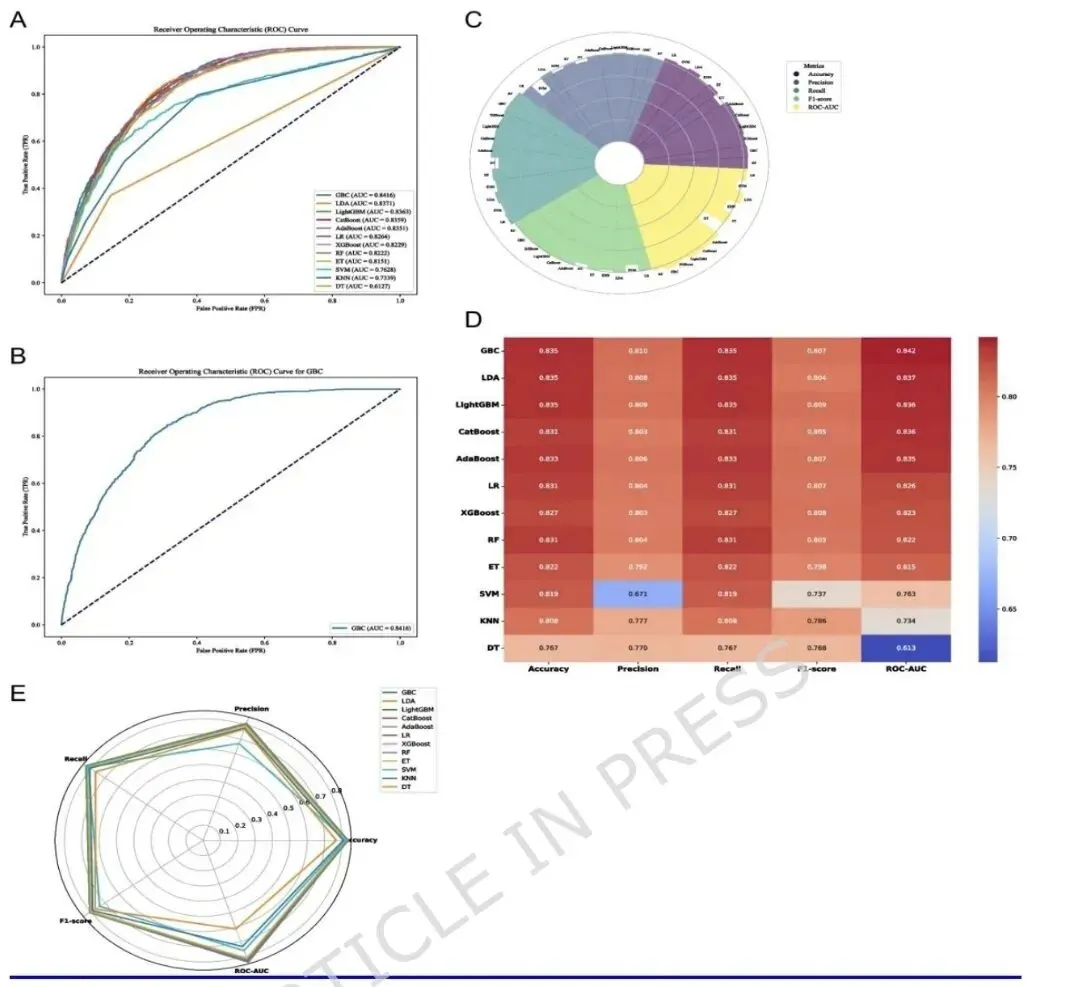
本研究基于2007-2018年美国国家健康与营养调查(NHANES)中23,635名成年人的横断面数据,将心脏代谢多病(CMM)定义为同时患有高血压、糖尿病、卒中或心肌梗死中的至少两种。体力活动(以MET-小时/周计)和静坐时间(小时/天)通过自报问卷获取。在描述性统计和逻辑回归中应用了调查抽样权重,并采用限制性立方样条(RCS)分析非线性关系。通过LASSO回归和Boruta算法进行特征筛选后,将70%样本用于训练12种机器学习模型,并在30%独立测试集中评估其性能,其中梯度提升分类器(GBC)表现最佳。模型可解释性方面,运用了SHAP进行全局特征重要性排序,并采用LIME对个体预测结果提供局部解释。 CMM患病率为18.1%。CMM组人群年龄更大、男性比例更高、BMI更高,且体力活动水平显著低于非CMM组(34.4 vs. 63.0 MET-小时/周)。
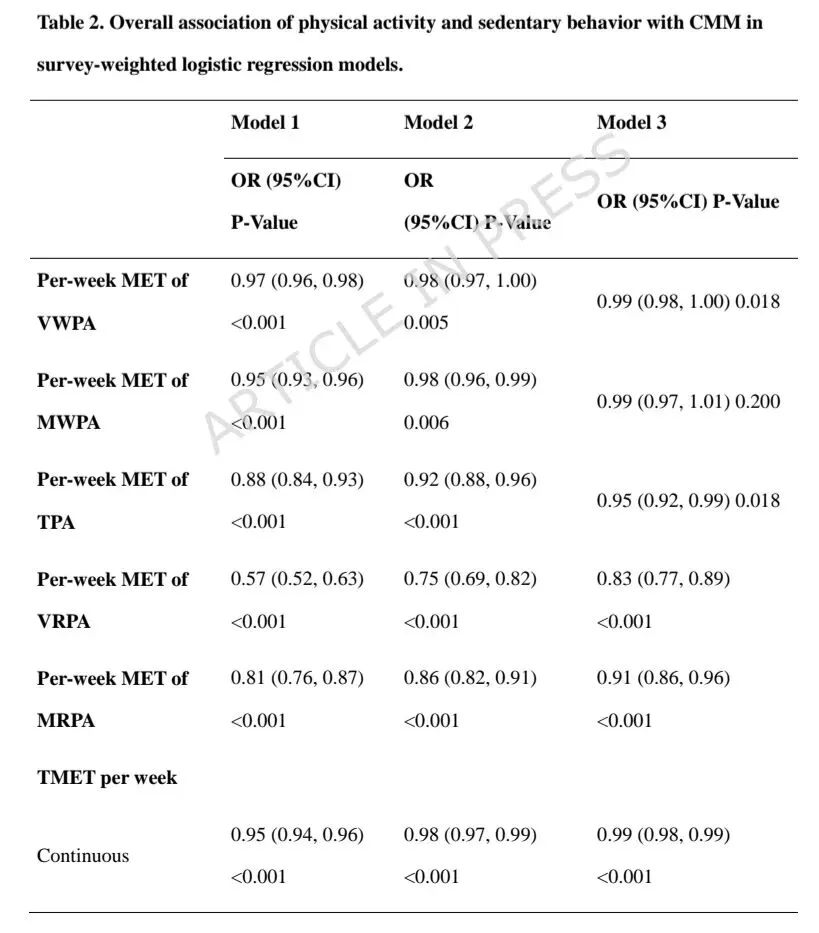
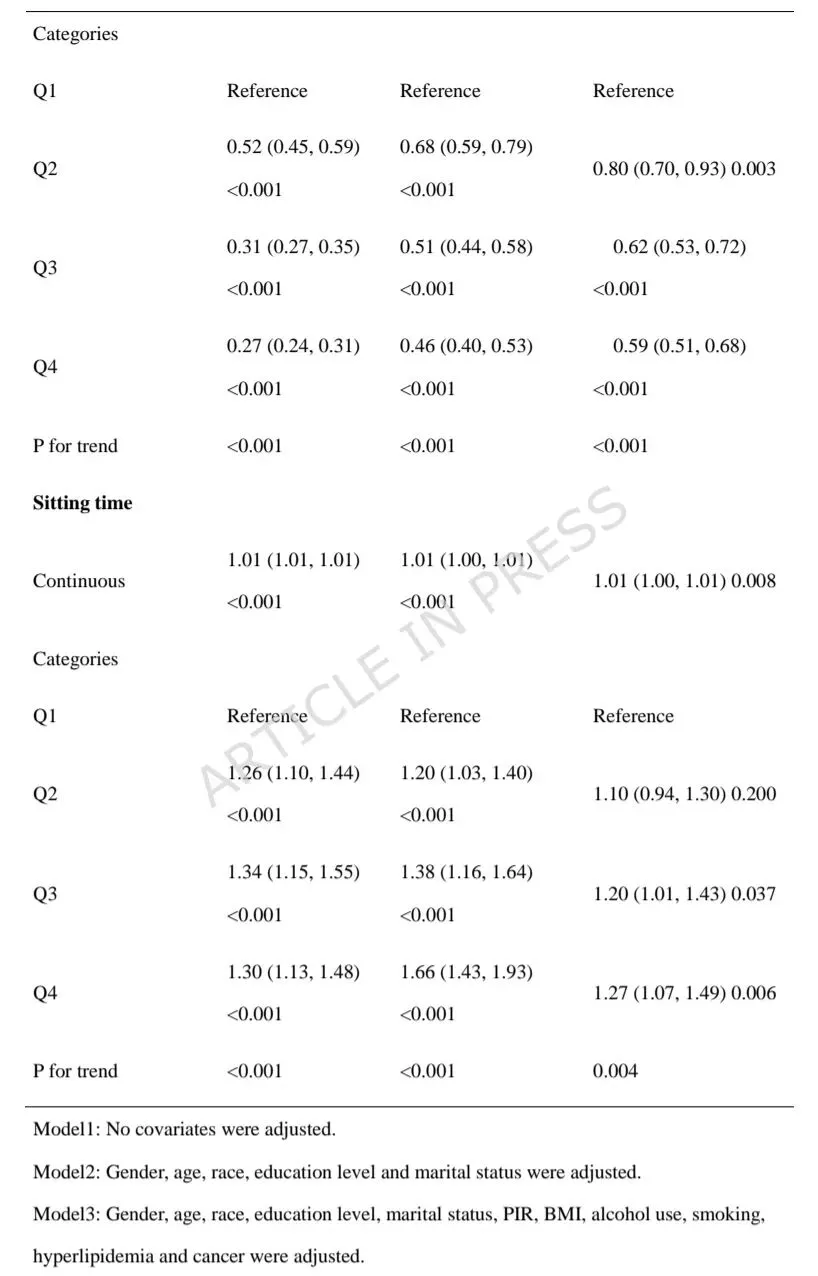
完全校正后,高PA与低CMM风险显著相关(最高vs最低四分位:OR = 0.59),长静坐时间与高CMM风险显著相关(最高vs最低四分位:OR = 1.27)。2. 非线性关系与亚组一致性
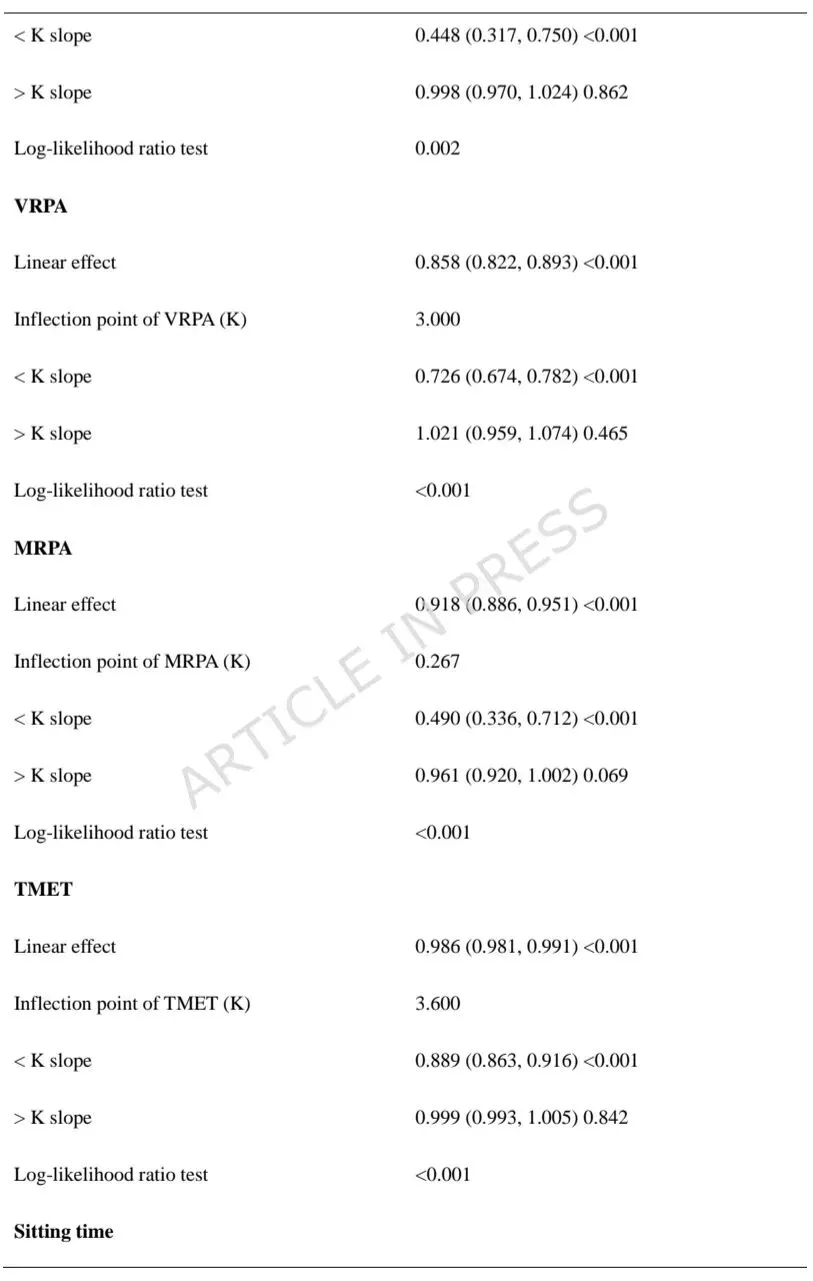
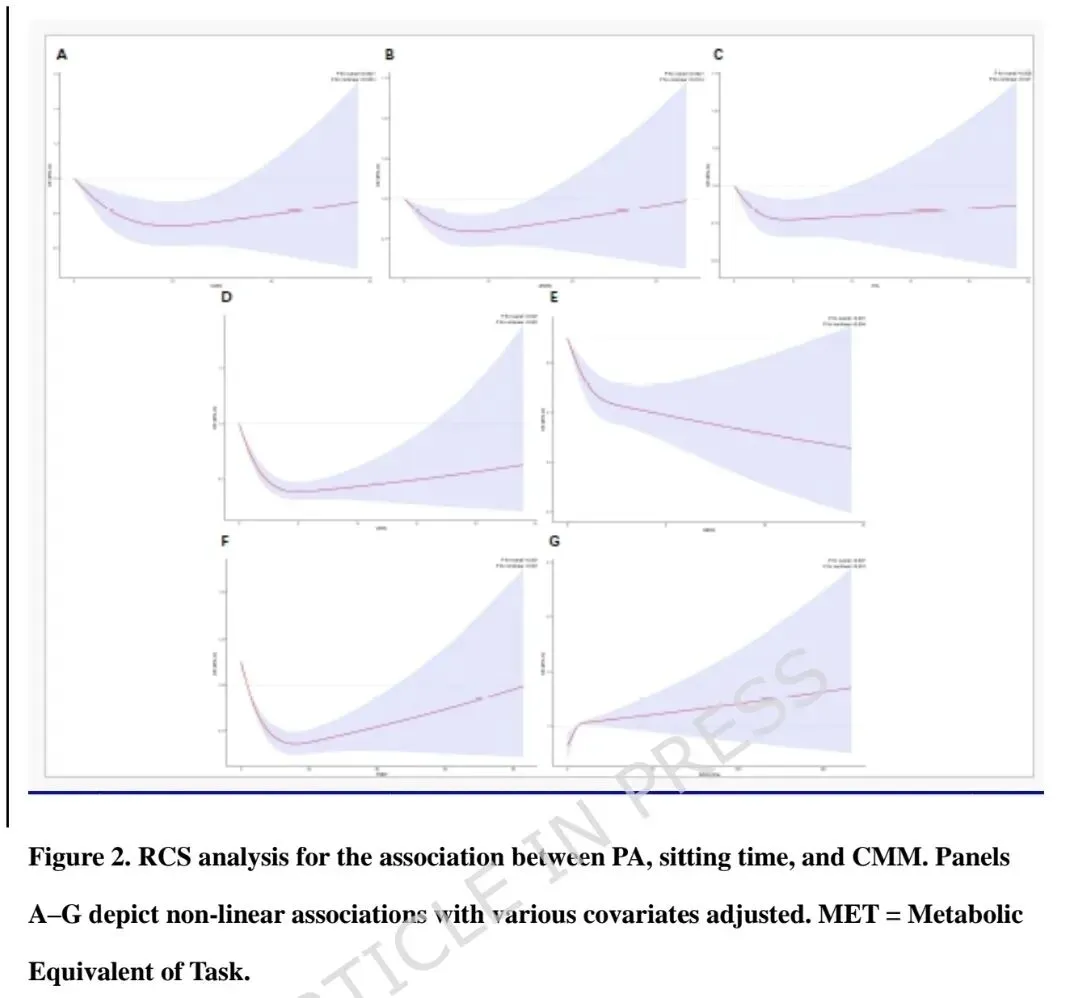
PA与CMM之间存在非线性负相关,拐点为3.6 MET-小时/周;低于该水平时PA的保护作用更强,超过后作用减弱。静坐时间拐点为11小时/天。上述关联在年龄、性别、BMI、种族、吸烟、饮酒等各亚组中保持一致,无显著交互作用。3. 机器学习模型性能与关键特征
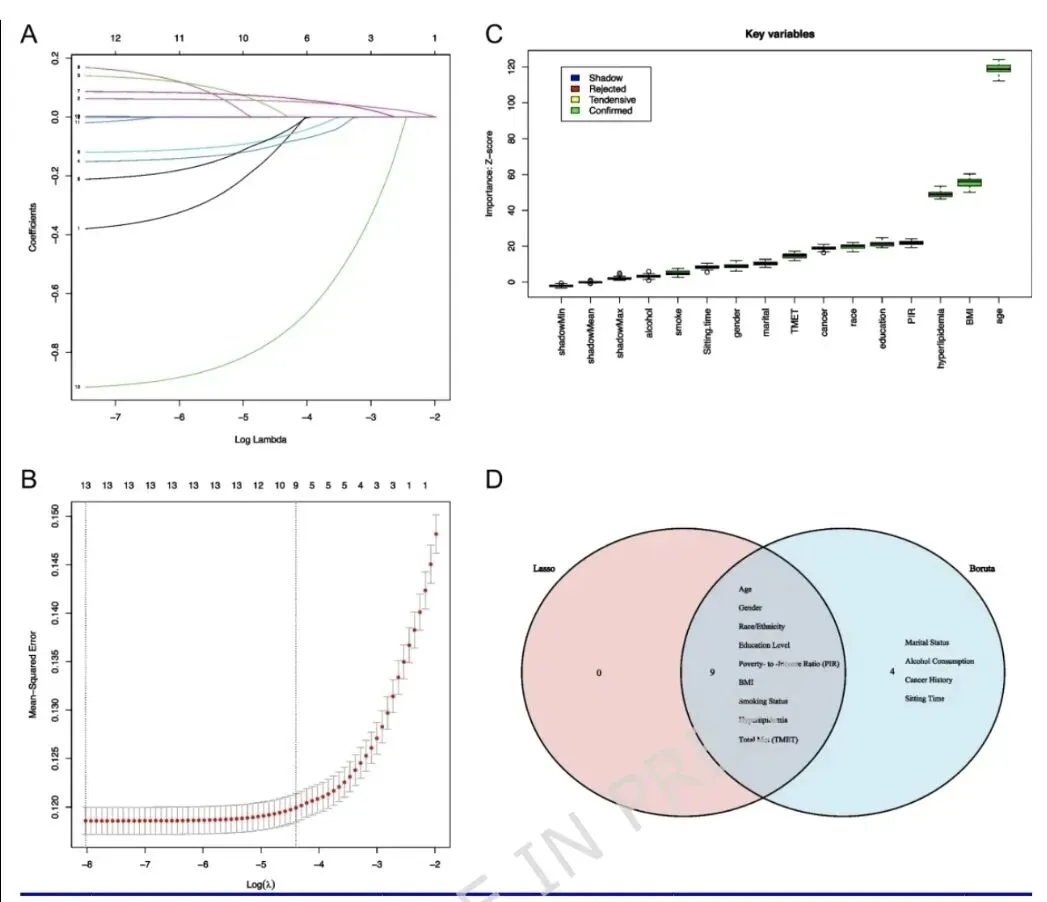
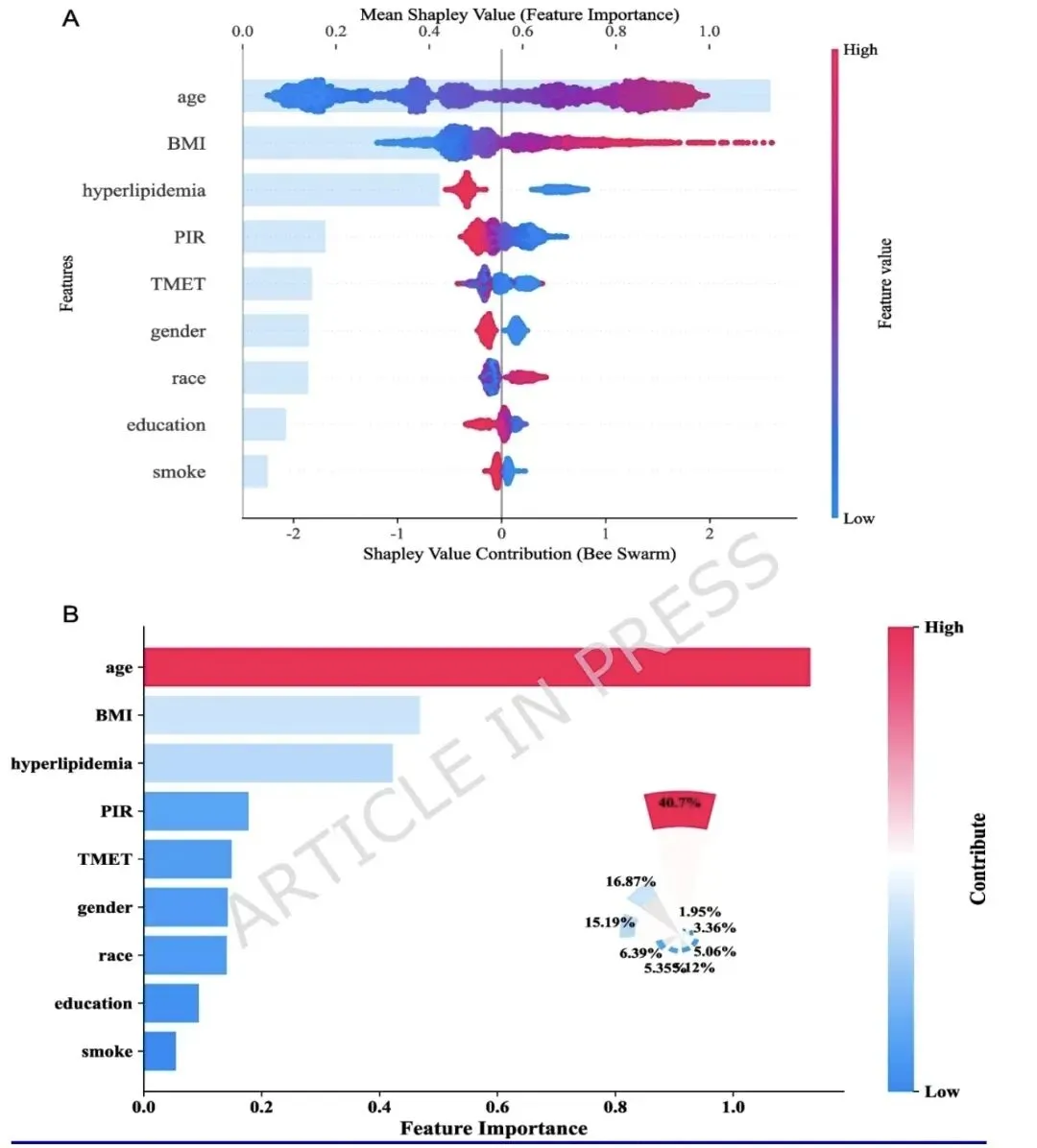
LASSO与Boruta共同筛选出13个关键特征(包括PA和静坐时间)。Gradient Boosting Classifier(GBC)表现最佳,AUC为0.84,准确率0.78,校准良好。SHAP全局重要性显示:年龄、BMI、高脂血症、收入贫困比、PA是前五大贡献变量。4. 局部个体解释与模型局限性
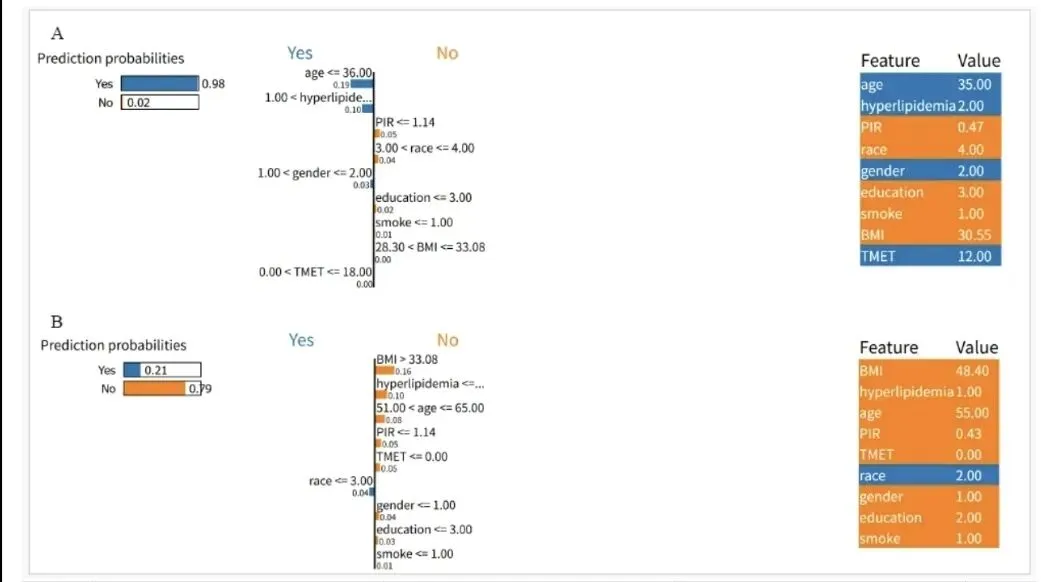
LIME提供了CMM阳性和正常个体的局部预测解释,展示各特征对单个预测的贡献方向与大小,但强调其反映的是模型行为而非因果关系。
研究为横断面设计,PA和静坐时间为自报数据,模型需外部验证,且未区分静坐类型,存在残余混杂与偏倚风险。本研究首次将可解释机器学习(SHAP和LIME)应用于NHANES大规模数据,在传统回归分析基础上,不仅证实了体力活动和静坐时间与心脏代谢多病风险的独立关联及非线性剂量-反应关系,还提供了一个透明、可解释的个体化风险分类框架,为心血管代谢疾病的精准预防和临床决策支持工具的开发提供了方法学参考和假设生成依据。(对文章数据库和分析方法感兴趣或需要生信分析服务的老师,欢迎关注小星一起交流)