突破纳米孔蛋白质测序技术:实现70余种氨基酸与肽段高分辨率识别蛋白质是生命活动的主要承担者,其序列决定了功能。然而,相较于核酸测序技术的快速发展,蛋白质测序技术长期滞后。传统的Edman降解仅能解析N末端序列且速度慢、读长短;质谱法在识别极短或极长肽段时存在覆盖空隙,且对翻译后修饰和不完全酶解产物的解析存在模糊性。由于缺乏蛋白质扩增技术,复杂样品中低丰度蛋白质的鉴定极具挑战。因此,开发一种可靠的单分子蛋白质测序方法成为迫切需求。
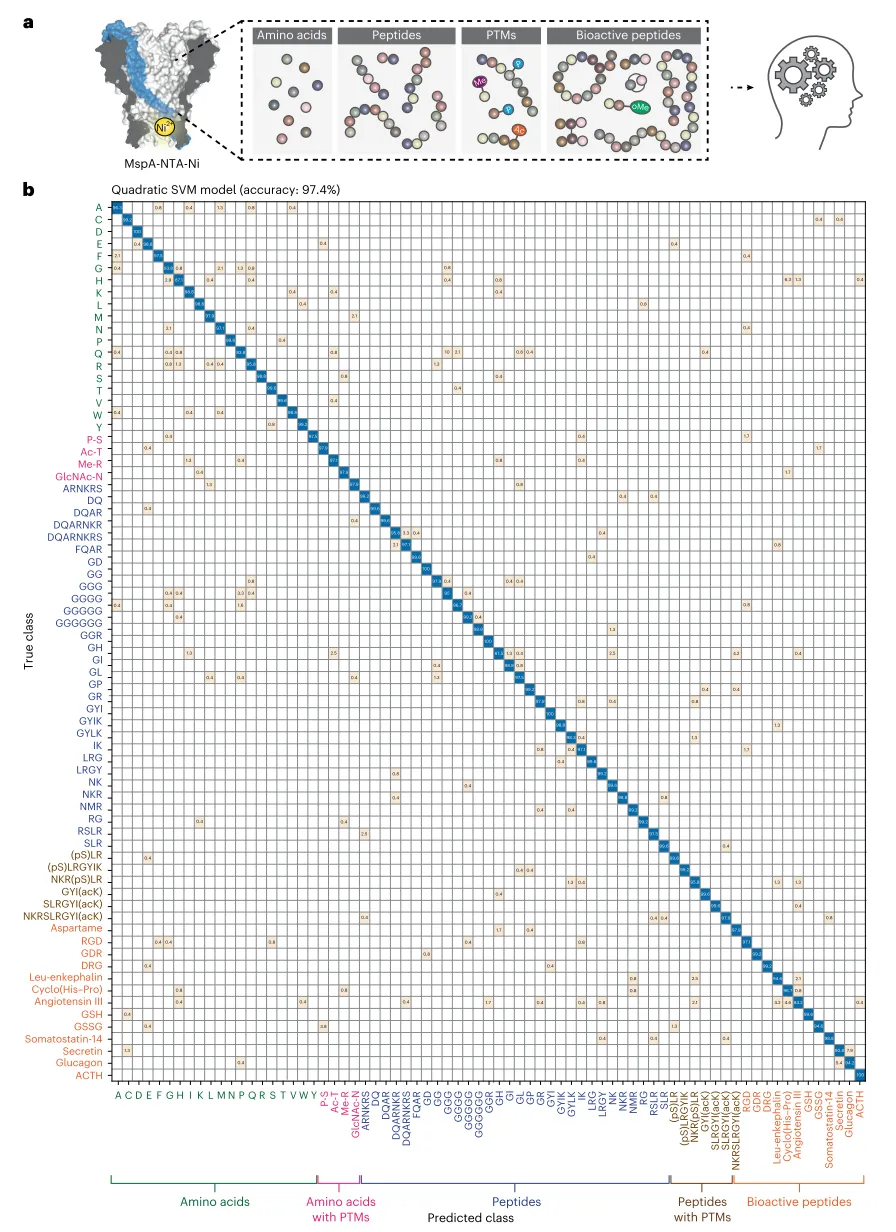
近日,南京大学黄硕教授团队报道了一种基于镍离子修饰的耻垢分枝杆菌孔蛋白A纳米孔的高分辨率肽段传感、谱图分析与序列组装方法。该MspA-NTA-Ni纳米孔能够在相同条件下识别20种蛋白源氨基酸、4种翻译后修饰氨基酸、32种肽段、6种修饰肽段、11种生物活性肽和2种新抗原肽段,结合机器学习分析,分类验证准确率高达97.4%。该平台不仅支持直接肽段识别,还能通过酶解实现肽段谱图分析与序列重建,对突变、缺失和翻译后修饰具有高度敏感性。相关论文以题为“Programmed synthesis of mesoporous protein crystals in cellular reactors”发表在最新一期《nature nanotechnology》上。
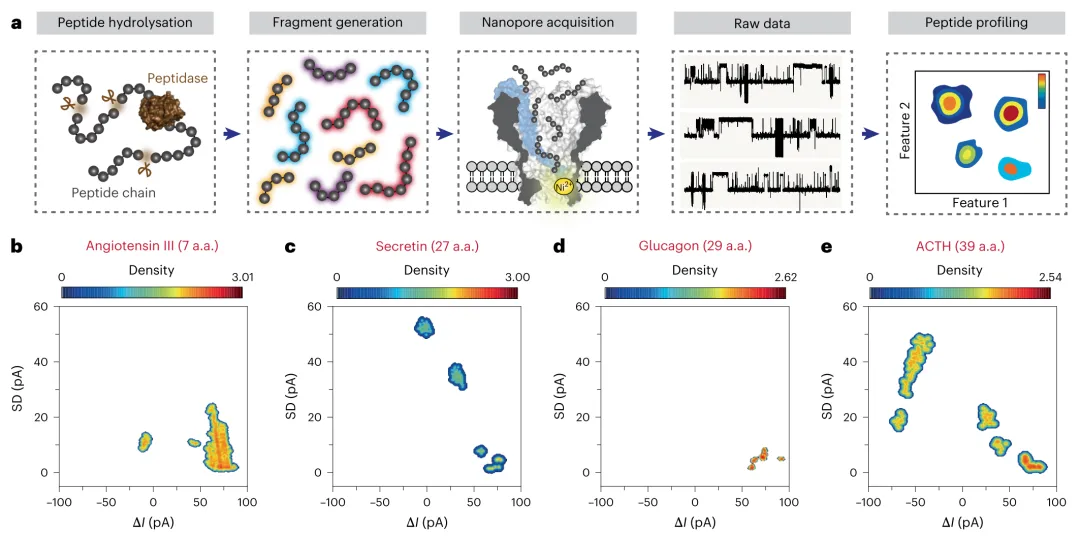
研究首先展示了MspA-NTA-Ni纳米孔对肽段的高分辨率识别能力。该纳米孔在孔道收缩处修饰了单个氮三乙酸-镍适配体,通过肽段N末端与镍离子的配位相互作用实现瞬时固定,从而抑制热运动、提高传感分辨率。实验表明,游离N末端是肽段传感的必要条件,而M2 MspA对照孔无法产生结合事件,证实了NTA-Ni适配体的关键作用。通过定义开放孔电流、事件电流、噪声幅度、驻留时间和事件间隔等核心参数,研究团队发现阻断幅度与甘氨酸肽段长度呈负相关,而标准差和驻留时间与链长呈非线性关系。值得注意的是,较长的肽段无需完全穿出孔道即可被感知。研究构建了包含30种模型肽段的肽段池(图1a),每种肽段均产生高度可区分的特征事件(图1b)。尽管部分肽段事件外观相似,但定量比较即可完全区分。在ΔI与SD的事件散点图中,所有肽段清晰可辨(图1c,d)。即便是一对常规质谱难以区分的序列异构体二肽RG和GR,MspA-NTA-Ni也能明确分辨。在同时添加DQ、IK、SLR、NKR和LRG五种肽段的混合实验中,训练好的二次支持向量机模型成功自动预测并标记了每个事件的身份(图1e)。
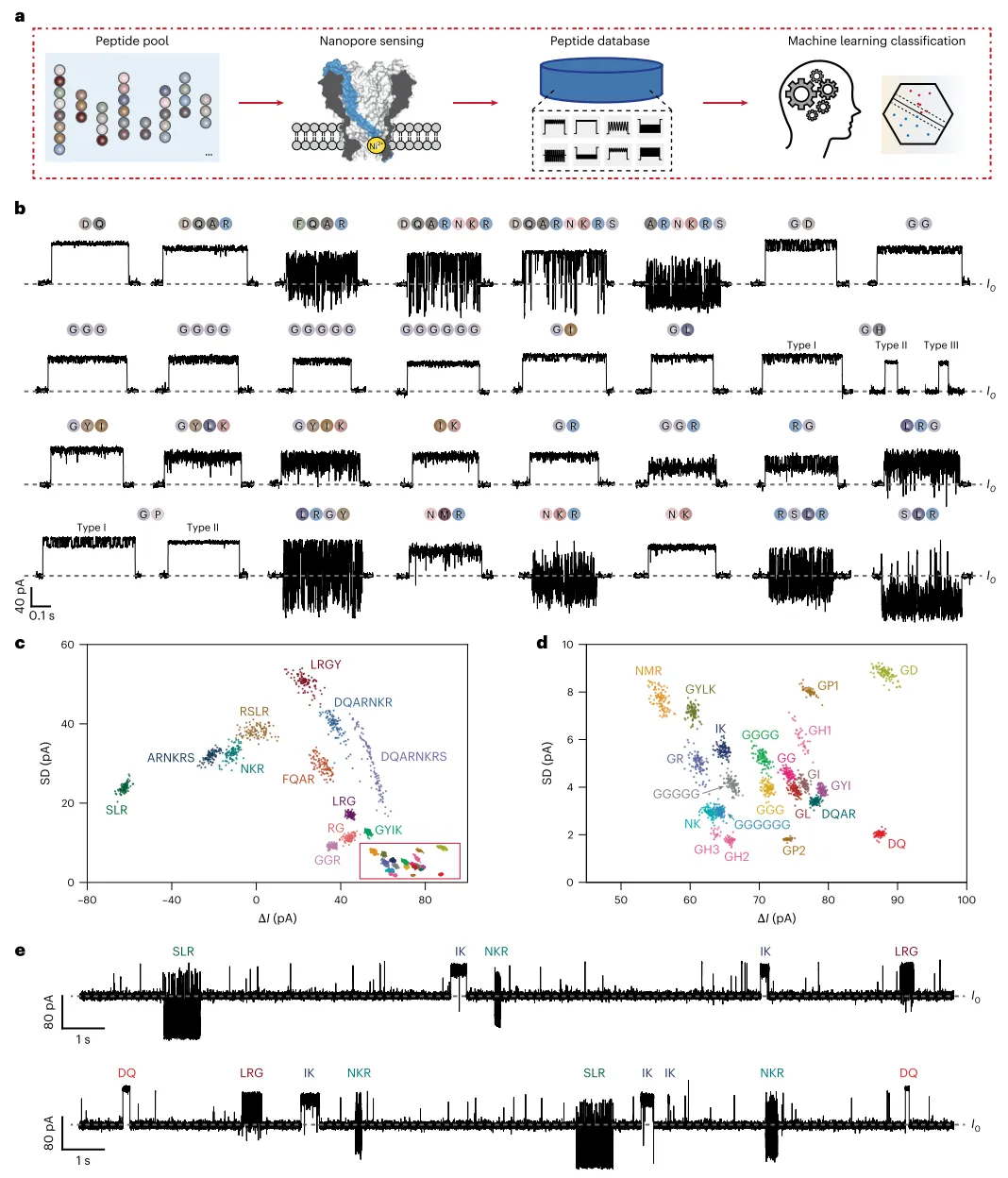
图1 | 纳米孔肽段传感。 a,工作流程。首先建立一个包含多种已知序列合成肽段的肽段池。使用MspA-NTA-Ni测量肽段池中的每种肽段,获取产生的纳米孔事件以构建数据库,并据此开发定制的机器学习算法用于进一步的肽段分类。b,使用MspA-NTA-Ni获取的代表性肽段事件。图中展示了30种不同类型肽段的结果。每种代表性事件上方标注了对应的肽段序列。大多数肽段仅报告单一类型的事件,这与可逆的孔-肽相互作用仅由肽段N末端与NTA-Ni适配体之间的配位相互作用引起这一事实一致。然而,GH和GP表现出多种事件类型,表明这些肽段的侧链基团可能产生其他孔-肽相互作用。c,使用b中肽段获取的结果生成的ΔI与SD事件散点图。每种肽段获取的100个事件用于生成该图,所有肽段均可清晰区分。d,c中红色方框标记区域的放大视图。e,同时传感DQ、IK、NKR、LRG和SLR期间获取的代表性痕迹。将全部五种肽段同时加入顺式腔室。测量过程中,DQ、LRG和SLR的终浓度为0.2 mM,NKR和IK的终浓度为0.3 mM。事件身份由训练好的二次SVM模型自动预测,并在相应事件上方标记。所有测量均使用MspA-NTA-Ni进行。I0代表MspA-NTA-Ni的开放孔电流。
为实现肽段谱图分析,研究采用四种生物活性肽——血管紧张素III(7氨基酸)、促胰液素(27氨基酸)、胰高血糖素(29氨基酸)和促肾上腺皮质激素(39氨基酸)进行验证。每种肽段经胰蛋白酶在相同条件下水解后,水解产物均产生特征性的纳米孔事件组合,形成独特的指纹图谱,可作为肽段识别的唯一标识(图2b-e)。这种不依赖数据库的肽段谱图分析方法,对于复杂肽段混合物和蛋白质水解产物的表征尤为有用。
图2 | 纳米孔肽段谱图分析。 a,纳米孔肽段谱图分析的工作流程。多肽首先通过内肽酶水解进行片段化。随后,产生的片段被MspA-NTA-Ni传感以产生相应的原始数据。提取所有原始数据的事件特征,并据此生成肽段谱图分析结果。b-e,代表性肽段的纳米孔谱图分析。四种生物活性肽,包括血管紧张素III(7氨基酸)(b)、促胰液素(27氨基酸)(c)、胰高血糖素(29氨基酸)(d)和促肾上腺皮质激素(39氨基酸)(e),分别用胰蛋白酶处理相同时间。每个水解产物报告了特征性的纳米孔事件组合,产生了用于肽段识别的独特指纹图谱。
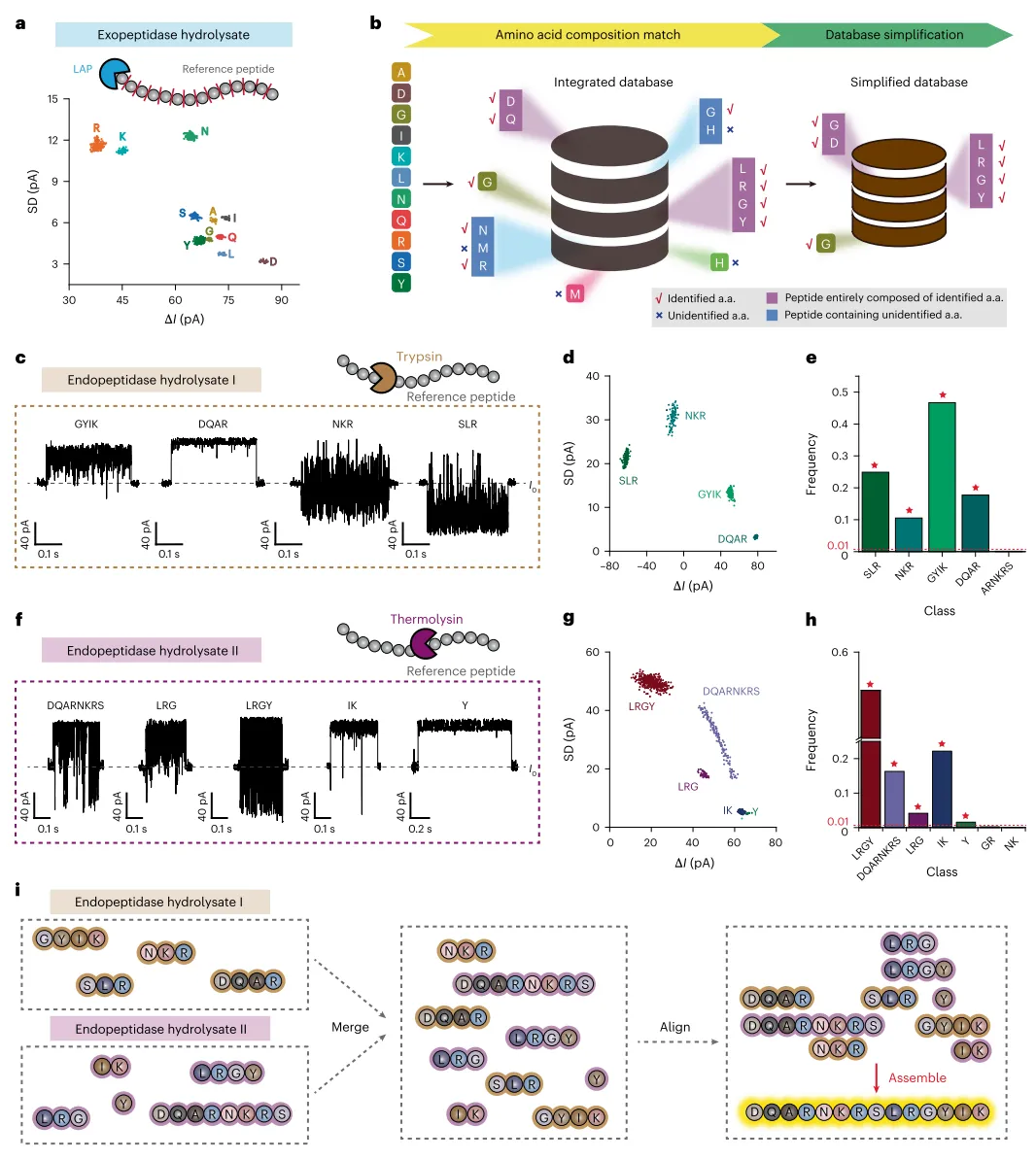
在肽段序列组装方面,研究团队以一条合成的十四肽DQARNKRSLRGYIK为参考肽段进行概念验证。首先使用亮氨酸氨基肽酶进行外肽酶水解,产生了对应R、K、N、S、A、I、Y、G、Q、L、D的11个完全分离的事件群,揭示了参考肽段的氨基酸组成(图3a)。根据此结果简化数据库后,分别用胰蛋白酶和嗜热菌蛋白酶对参考肽段进行内肽酶水解。胰蛋白酶水解产物中鉴定出SLR、NKR、GYIK和DQAR四个肽段(图3c-e);嗜热菌蛋白酶水解产物中鉴定出DQARNKRS、LRGY、LRG和IK四个肽段以及游离酪氨酸(图3f-h)。根据片段重叠,参考肽段序列被确定为DQARNKRSLRGYIK,与实际序列完全一致(图3i)。相比之下,液相色谱-串联质谱法对该肽段的分析表现出有限的骨架裂解,片段离子缺失或强度极低。
图3 | 通过水解进行纳米孔肽段测序。 a,DQARNKRSLRGYIK的外肽酶水解产物(n=888)获取的事件ΔI与SD散点图。使用LAP进行外肽酶处理。所有事件均由先前训练的机器学习分类器识别。识别出对应于R、K、N、S、A、I、Y、G、Q、L和D的11个事件群。b,数据库简化。包含30种肽段和24种氨基酸纳米孔事件的集成数据库,根据a中展示的氨基酸组成结果进一步简化。为简化后续肽段识别,所有未鉴定出的氨基酸及相关肽段均从数据库中排除。c,f,展示内肽酶水解产物I(c,胰蛋白酶)和内肽酶水解产物II(f,嗜热菌蛋白酶)的代表性事件。胰蛋白酶在精氨酸和赖氨酸的羧基侧切割(除非其后是脯氨酸),而嗜热菌蛋白酶在大疏水残基的N末端侧水解肽键。d,g,内肽酶水解产物I(d,n=807)和内肽酶水解产物II(g,n=970)结果的事件ΔI与SD散点图。所有事件均由源自简化肽段数据库的二次SVM模型识别。d中识别出对应于SLR、NKR、GYIK和DQAR的事件群。g中识别出对应于LRGY、LRG、DQARNKRS、IK和Y的事件群。e,h,内肽酶水解产物I(e)和内肽酶水解产物II(h)结果的事件出现频率。所有鉴定出的肽段均用红星标记。i,肽段的序列重建。仅保留出现频率>1%的预测结果用于序列组装。根据上述结果,原始肽段序列确定为DQARNKRSLRGYIK。
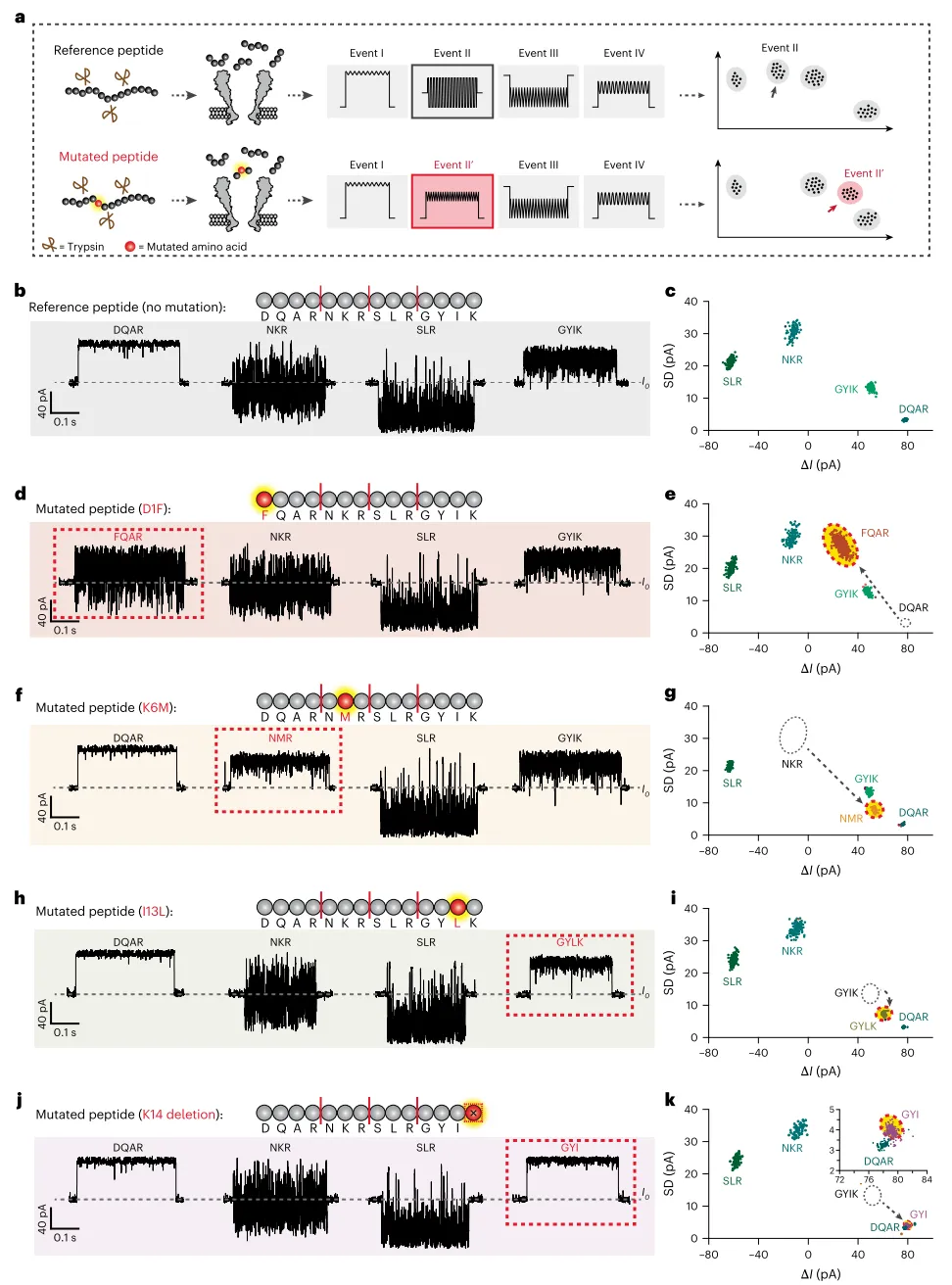
该技术能够识别单氨基酸水平的突变。以参考肽段为基础,合成了四种含单氨基酸改变的变体肽段:DIF(第1位天冬氨酸替换为苯丙氨酸)、K6M(第6位赖氨酸替换为甲硫氨酸)、I13L(第13位异亮氨酸替换为亮氨酸)和K14缺失肽段。经胰蛋白酶水解后,每种变体肽段均产生与参考肽段不同的肽段数据簇——缺失原有数据簇并出现新数据簇(图4d,k)。值得注意的是,I13L变体(异亮氨酸被亮氨酸取代)能够被明确区分,而质谱法难以解析这对同量异位氨基酸。
图4 | 使用纳米孔肽段测序识别突变。 a,突变识别的工作流程。b,d,f,h,j,四种含单氨基酸改变的肽段及其水解示意图,包括DIF(d)、K6M(f)、I13L(h)和K14缺失(j)。所有肽段(b,d,f,h,j)均在相同条件下水解。肽段序列上的红线代表胰蛋白酶切割位点。突变位点被高亮显示。突变肽段的事件用红色虚线框标记。c,e,g,i,k,DIF(e,n=1126)、K6M(g,n=693)、I13L(i,n=856)和K14缺失(k,n=537)水解产物结果的事件ΔI与SD散点图。所有事件均通过机器学习识别并用彩色点标记。每个图中,对应于突变肽段片段和未突变对应片段的事件群分别用红色和灰色圆圈标出。
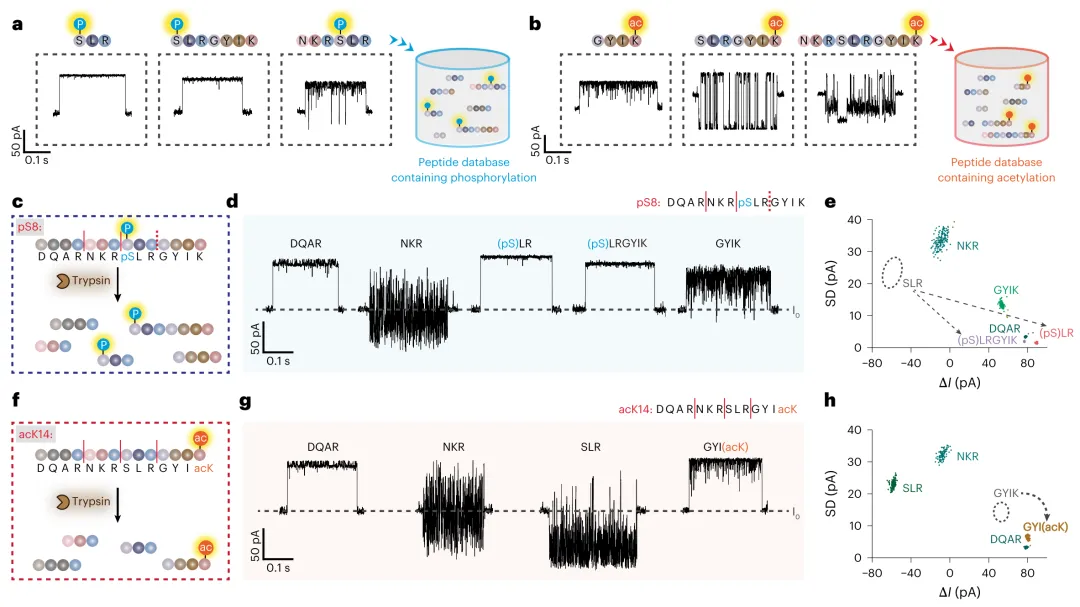
对于翻译后修饰的识别,研究合成了含磷酸化修饰的pS8肽段和含乙酰化修饰的acK14肽段。经胰蛋白酶水解后,pS8水解产物中鉴定出DQAR、NKR、(ps)LR、(ps)LRGYIK和GYIK,并检测到部分裂解片段(ps)LRGYIK,提示磷酸基团可能阻碍胰蛋白酶接近裂解位点(图5d,e)。acK14水解产物中则鉴定出DQAR、NKR、SLR和GYI(ack)四个肽段(图5g,h)。与参考肽段相比,修饰位点被清晰定位。
图5 | 含翻译后修饰肽段的分析。 a,(ps)LR、(ps)LRGYIK和NKR(ps)LR的代表性事件。b,GYI(ack)、SLRGYI(ack)和NKRSLRGYI(ack)的代表性事件。a和b中肽段的事件特征被添加到现有肽段数据库中,以创建包含翻译后修饰的更大肽段数据库。c,pS8肽段(DQARNKR(ps)LRGYIK)的胰蛋白酶水解。实线红线代表完全切割位点,虚线红线代表不完全切割位点。d,pS8水解产物获取的代表性事件。e,pS8水解产物结果(n=701)的事件ΔI与SD散点图。对应于未修饰肽段对应物(SLR)的事件群用灰色圆圈指示。f,DQARNKRSLRGYI(ack)(acK14)的胰蛋白酶水解。g,acK14水解产物获取的代表性事件。h,acK14水解产物结果(n=783)的事件ΔI与SD散点图。对应于未修饰肽段对应物(GYIK)的事件群用灰色圆圈指示。d、e、g和h中的所有事件均通过机器学习识别。识别出的事件用相应颜色的点标记。
对于生物活性肽的直接识别,研究检测了阿斯巴甜、环(His-Pro)、RGD、还原型谷胱甘肽、氧化型谷胱甘肽、亮氨酸脑啡肽、血管紧张素III、生长抑素-14、促胰液素、胰高血糖素和促肾上腺皮质激素。值得注意的是,环(His-Pro)虽无游离N末端,仍可通过侧链给体原子与NTA-Ni适配体相互作用;而含二硫键环化的生长抑素-14保持可及的N末端,同样可被检测。在同时添加七种生物活性肽的混合实验中,袋装树模型实现了97.8%的验证准确率。两种RGD异构体(GDR和DRG)亦被明确区分。
研究最终构建了一个涵盖73种分析物的综合数据库,包括初始30种肽段、6种含翻译后修饰的肽段、20种氨基酸、4种含翻译后修饰的氨基酸、11种生物活性肽和2种RGD异构肽段。重新训练的二次支持向量机模型实现了97.4%的分类准确率(图6)。两种公共新抗原BRAF V600E和KRAS G12D及其野生型对应肽段同样能够被有效检测和明确区分。
图6 | 数据库扩展。 a,技术概览。MspA-NTA-Ni普遍兼容氨基酸、肽段、含翻译后修饰的氨基酸、含翻译后修饰的肽段以及多种生物活性肽,包括环肽、阿斯巴甜和GSSG。它们的纳米孔事件特征被收集并输入机器学习程序,用于下游传感和测序应用。b,先前训练的二次SVM模型生成的混淆矩阵结果。该模型共包含73个分析物类别,包括氨基酸和肽段。实现了97.4%的验证准确率。鉴于MspA-NTA-Ni的高分辨率,该模型可以进一步扩展或针对特定应用模块化建立,同时仍保持令人满意的准确率。
综上,MspA-NTA-Ni纳米孔实现了对氨基酸和肽段的同步传感,覆盖1至39个氨基酸长度范围,无需标记,适用于具有未封闭N末端的线性肽段以及具有配位侧链或可及N末端的环状肽段。该技术可直接鉴定肽段,也可通过水解产生片段进行谱图分析,以不依赖数据库的方式表征复杂肽段混合物。进一步整合多种内肽酶的组合可促进更精细的谱图分析。肽段序列组装概念验证成功实现了单氨基酸分辨率下突变、缺失和翻译后修饰的精准定位。尽管序列组装依赖数据库,但机器学习模型对数据库规模的准确性分析表明MspA-NTA-Ni具有同时识别更多种类肽段的高容量。未来整合先进的序列重建算法将促进日益复杂数据集的处理,而在孔道上方直接偶联肽段将进一步实现实时单分子肽段水解和片段鉴定。

「BioMed科技」关注生物医药×化学材料交叉前沿研究进展!交流、合作,请添加杨主编微信!来源:BioMed科技声明:仅代表作者个人观点,作者水平有限,如有不科学之处,请在下方留言指正!