🐉 龙哥读论文知识星球来了!想了解如何像这篇论文一样,洞察编码标准的“隐藏”规律,设计出更安全的隐写术吗?星球每日更新视频编码、信息安全等领域的前沿论文、开源代码和行业动态,帮你快速抓住核心创新点,节省90%调研时间!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文从一个非常巧妙的视角切入——编码器自身的“修复”特性,解决了视频隐写术领域一个长期存在的痛点:抗隐写分析能力弱。它不仅提出了一个有效的解决方案,更重要的是,它揭示并量化了现有方法失效的根本原因(CBSSM度量),这种“发现问题-分析问题-解决问题”的完整逻辑链条,在工程和学术上都很有价值。对于从事多媒体安全、信息隐藏的同学来说,这是一篇兼具启发性和实用性的佳作。
原论文信息如下:
论文标题:
A Video Steganography for H.265/HEVC Based on Multiple CU Size and Block Structure Distortion
发表日期:
2026年03月
发表单位:
南京信息工程大学 数字取证教育部工程研究中心;广州大学 人工智能学院
原文链接:
https://arxiv.org/pdf/2603.22850v1.pdf
大家好,我是龙哥。今天咱们来聊点“隐秘”的话题——不是娱乐圈的八卦,而是正儿八经的视频隐写术。想象一下,你有一份绝密情报,想通过公开的网络发送给同伴。直接发明文文件?太危险。加密?虽然别人看不懂内容,但“加密文件”本身就像个穿着防弹衣的特工,非常扎眼。最高明的隐藏,是“大隐隐于市”。把信息藏在人人都看的视频里,像素和色彩没有丝毫变化,对手连“有隐藏信息”这件事本身都察觉不到。这就是隐写术的魅力。其中,基于H.265/HEVC视频压缩标准的隐写术是主流。但最近,南京信息工程大学和广州大学的团队发表了一篇论文,指出了一个致命的漏洞,并给出了一个堪称“隐形衣升级版”的新方案。隐写术的“阿喀琉斯之踵”:为何现有视频隐写容易被发现?
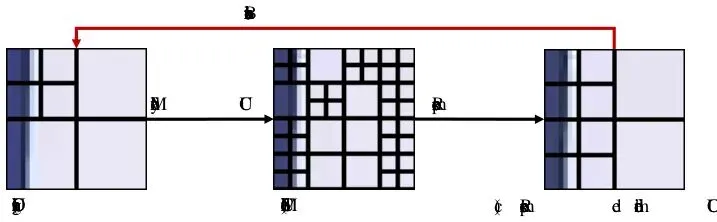
要理解这个漏洞,我们得先知道视频隐写术怎么“藏东西”。在H.265/HEVC这类现代视频编码标准中,视频被切分成一个个方块进行压缩,这个方块叫做编码单元。CU可以根据图像内容的复杂程度,选择是否继续分割成更小的子块。最终,一帧图像会被分割成一个由大大小小方块组成的“块结构”树。一种很聪明的隐写思路是:修改这个块结构来携带秘密信息。比如,规定“分割”代表比特1,“不分割”代表比特0。由于只是改变了方块的分割方式,没有动像素值,所以视觉上几乎看不出差别,码率(文件大小)增加也少。听起来很完美,对吧?但论文的作者们发现,这类方法有个致命的“阿喀琉斯之踵”。虽然人眼看不出来,但专业的隐写分析工具却能轻易地把它们揪出来。这是为什么?秘密就藏在编码器自身的“修复”特性里。洞察核心:H.265/HEVC编码中神秘的“块结构恢复现象”
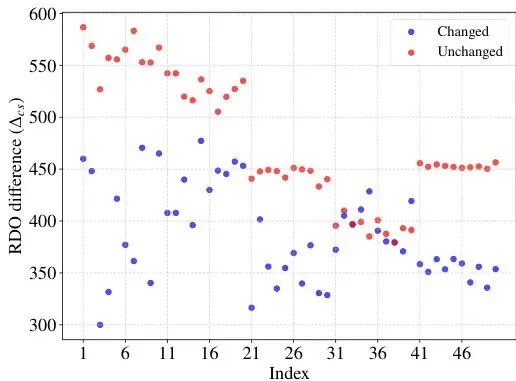
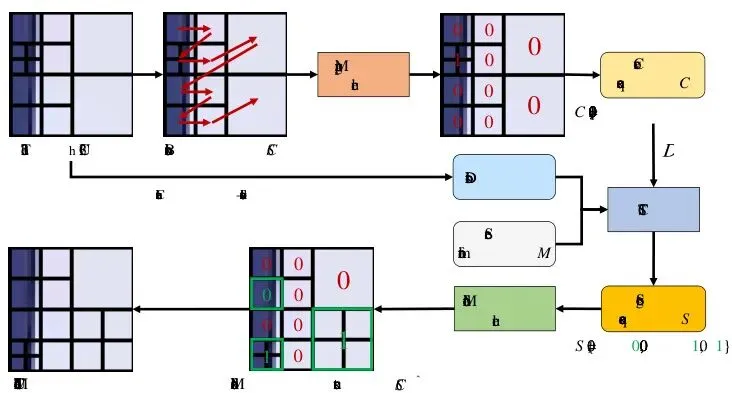
本论文的第一个重大贡献,就是发现并命名了一个关键现象:CU块结构恢复现象。简单说就是:无论你如何强行修改视频的CU分割结构,只要对这个修改后的视频进行“重新压缩”,它的块结构就会神奇地恢复成与原始视频非常接近的样子。图1:块结构恢复现象。(a) 一个32x32 CU的原始块结构。(b) 模拟隐写过程修改后的块结构。(c) 重新压缩后的修改块结构。看上面的图1,是不是很神奇?(b)图被改得面目全非,但一经过重新压缩(c图),就变得和原始(a图)几乎一样了。这就像你用笔在一张有折痕的纸上胡乱画线,然后用力抚平,纸张还是会大致按照原来的折痕折叠。为什么会这样?根源在于H.265/HEVC编码器的率失真优化。编码器在选择如何分割一个CU时,本质是在计算一个“成本”:分割得细,能更好地保留细节(失真小),但需要更多比特来描述(码率高);分割得粗,码率低但失真可能大。编码器会选择总成本最低的那个方案。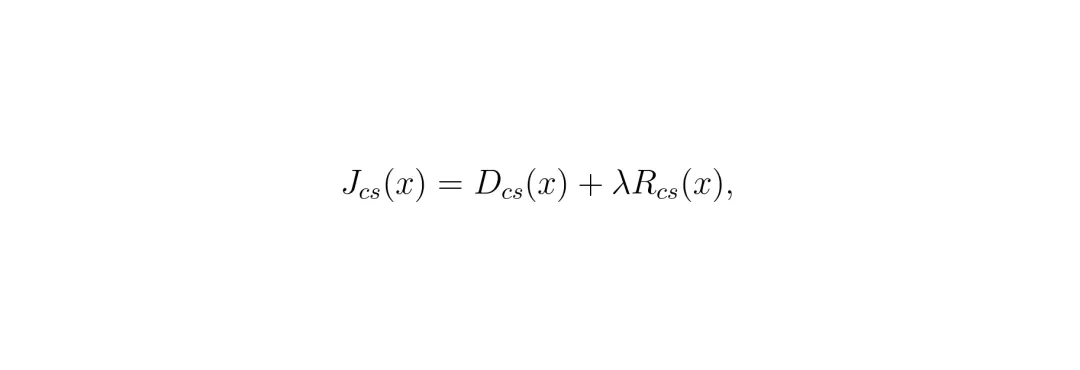 这个成本函数J_cs(x) = D_cs(x) + λ R_cs(x),其中D是失真,R是码率,λ是权衡系数。原始视频的块结构,是编码器为原始像素计算出的“最优解”。当你强行修改块结构(比如在平滑区域强行分割),你就引入了一个“次优解”。重新压缩时,编码器会再次为(因量化而略有改变的)像素计算成本,只要原始最优解的成本优势足够大,它大概率会再次胜出,从而导致块结构“恢复”到原始状态。论文通过理论推导(基于RDO差异下界和Lipschitz假设)和大量实验证实了这一点。他们统计发现,超过85%的CU在重新压缩后,其块结构会保持不变。图4:平均RDO差异分布图。红点(块结构未变)对应的RDO差异显著大于蓝点(块结构改变)。那么,这和隐写术被发现有什么关系呢?关系大了!隐写分析者可以模拟“重新压缩”这个过程。如果一个视频的块结构在重新压缩前后变化巨大,那就强烈暗示它被“强行修改”过,从而暴露隐写行为。
这个成本函数J_cs(x) = D_cs(x) + λ R_cs(x),其中D是失真,R是码率,λ是权衡系数。原始视频的块结构,是编码器为原始像素计算出的“最优解”。当你强行修改块结构(比如在平滑区域强行分割),你就引入了一个“次优解”。重新压缩时,编码器会再次为(因量化而略有改变的)像素计算成本,只要原始最优解的成本优势足够大,它大概率会再次胜出,从而导致块结构“恢复”到原始状态。论文通过理论推导(基于RDO差异下界和Lipschitz假设)和大量实验证实了这一点。他们统计发现,超过85%的CU在重新压缩后,其块结构会保持不变。图4:平均RDO差异分布图。红点(块结构未变)对应的RDO差异显著大于蓝点(块结构改变)。那么,这和隐写术被发现有什么关系呢?关系大了!隐写分析者可以模拟“重新压缩”这个过程。如果一个视频的块结构在重新压缩前后变化巨大,那就强烈暗示它被“强行修改”过,从而暴露隐写行为。量化破绽:CU块结构稳定性度量(CBSSM)的提出
光有定性观察还不够,得有定量的“尺子”来测量这种破绽。为此,论文提出了CU块结构稳定性度量,它的英文全称是 CU Block Structure Stability Metric (CBSSM)。块数量不变度量:衡量重新压缩前后,各种尺寸的CU块在数量上是否保持一致。如果隐写粗暴地改变了很多块的分割,这个值就会下降。
块结构不变度量:衡量重新压缩前后,每个具体位置的CU块结构是否保持一致。即便块数量没变,但内部结构被改乱了,这个值也会下降。
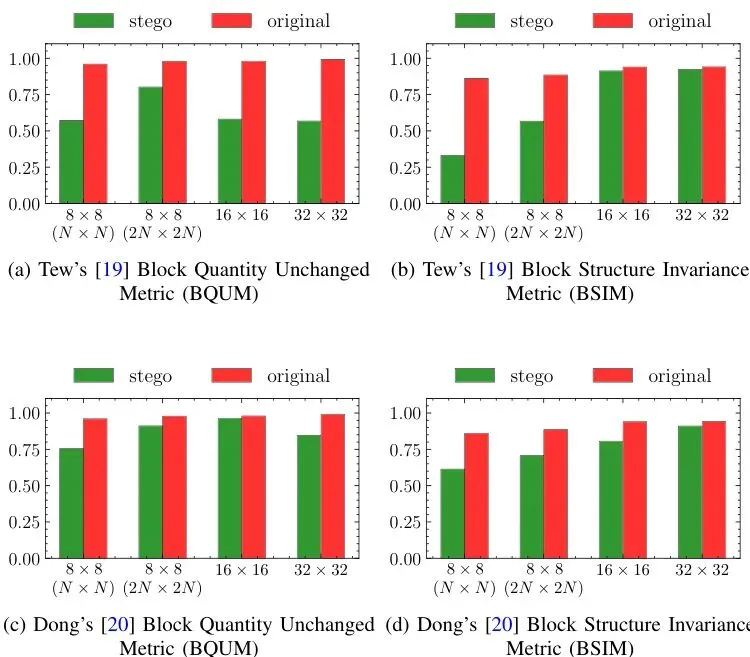
一个正常的、未被隐写的视频,重新压缩后其CBSSM值会很高(接近1)。而一旦用现有方法嵌入信息,CBSSM值就会显著降低,如下图实验所示:图5:使用CBSSM特征检测两种现有隐写算法。绿条(隐写后)的BQUM和BSIM值相比红条(原始/重新压缩)大幅下降,说明它们极易被检测。看,这就是现有方法的死穴!CBSSM就像一面“照妖镜”,让它们无所遁形。那么,如何打造一件能通过这面镜子检查的“隐形衣”呢?论文给出了一个精妙的三合一方案。巧妙隐身:基于多CU尺寸和三级失真的新隐写方案
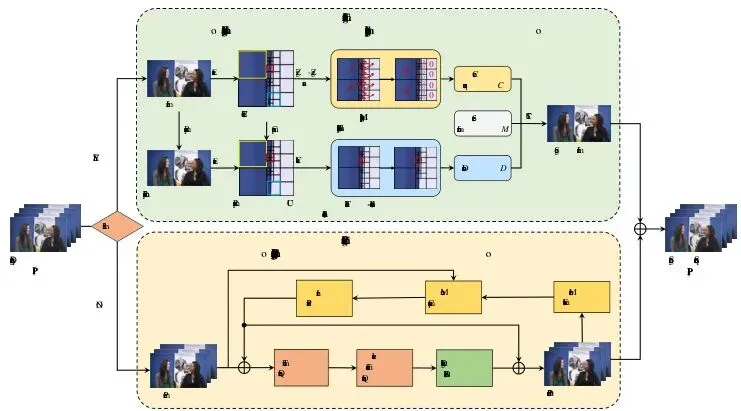
新方案的核心思想很清晰:既然“块结构恢复”是导致被检测的原因,那我们就反其道而行之——第一,尽量少改块结构;第二,要改就改那些“本来就会变”的地方。为了让修改幅度最小,新方法首先设计了一个基于多CU尺寸的映射规则。它将I帧中所有(除了64x64,因为太大容易引起注意)的CU块,按照其尺寸映射成一个二进制序列:- 32x32, 16x16, “8x8不分割” 的块 -> 映射为比特 ‘0’
- “8x8分割成4个4x4” 的块 -> 映射为比特 ‘1’关键的限制来了:在后续修改这个二进制序列来嵌入秘密信息时,只允许每个CU的修改深度不超过1。这意味着,一个32x32的块最多只能被分割成4个16x16,而不会被暴力地一路分割到4x4。这样就最大限度地保留了原始块结构的“骨架”。光“少改”还不够,还得“改对地方”。为此,论文提出了一个基于块结构的三级失真函数。它的工作原理是这样的:在嵌入信息前,先对原始I帧做一次“模拟”的重新压缩,然后对比每个CU在重新压缩前后的块结构变化程度。根据变化大小,将所有CU分为三类,并赋予不同的“失真代价”:情况1:稳如泰山。重新压缩后块结构完全没变(MDD=0)。这种CU是“顽固派”,你强行修改它,它以后也会恢复原样,从而留下把柄。因此,给它分配很高的失真代价,让隐写算法尽量别碰它。
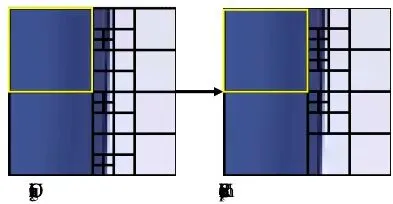
图6:情况1的示例CTU(黄色标记)。重新压缩后结构完全不变。情况2:小有变动。重新压缩后块结构有轻微变化(MDD=1)。这种CU是“摇摆派”,可以修改,分配中等失真代价。
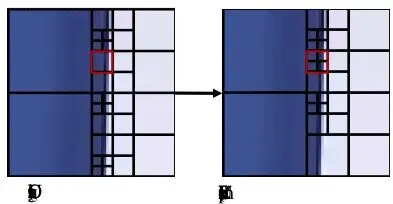
图7:情况2的示例CTU(红色标记)。重新压缩后结构有轻微变化。情况3:剧烈变动。重新压缩后块结构发生显著改变(MDD>1)。这种CU本身就处在“地震带”上,其块结构非常不稳定。在这里进行隐写操作,就像是“顺水推舟”,即使不改,它自己下次压缩时也可能大变样。因此,给它分配很低的失真代价,鼓励隐写算法优先在这里“施工”。
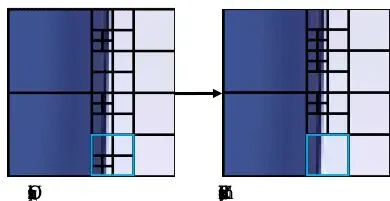
图8:情况3的示例CTU(蓝色标记)。重新压缩后结构发生剧烈变化。最后,将映射得到的二进制序列、秘密信息、以及计算好的三级失真代价,一同输入STC算法。STC的全称是Syndrome-Trellis Codes,它是一种经典的失真最小化嵌入编码。简单理解,STC就像一个“智能调度员”,它会在满足信息嵌入量的前提下,优先选择失真代价低的CU进行修改,从而在整体上实现最隐蔽的嵌入。全面胜出:新方法在视觉、码率、容量和安全性上的卓越表现
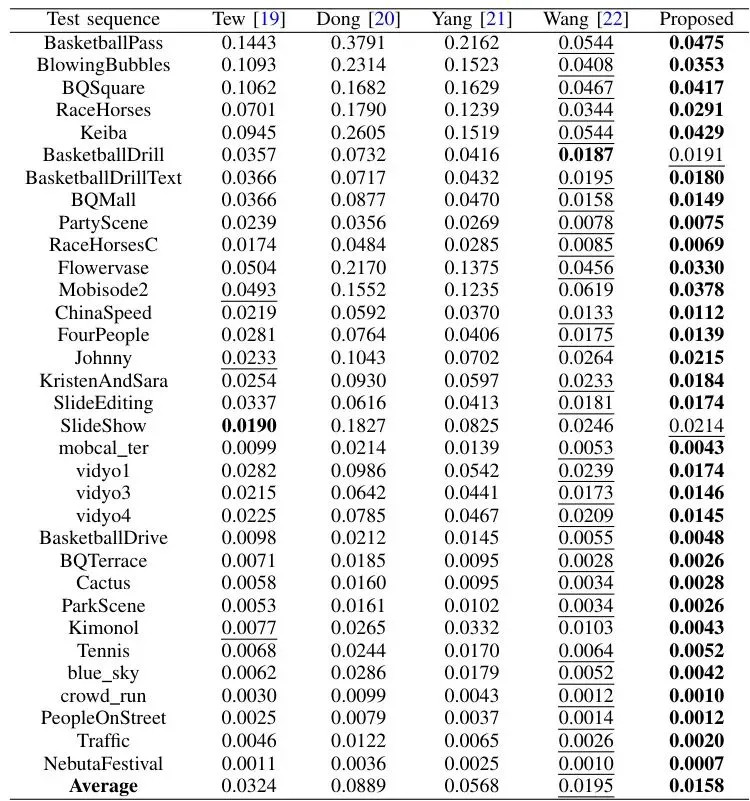
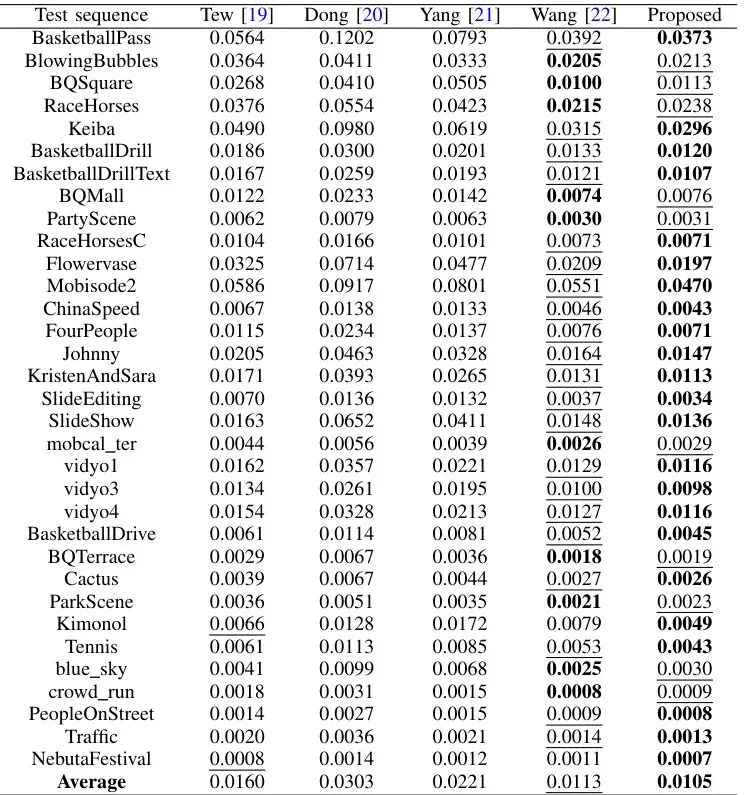
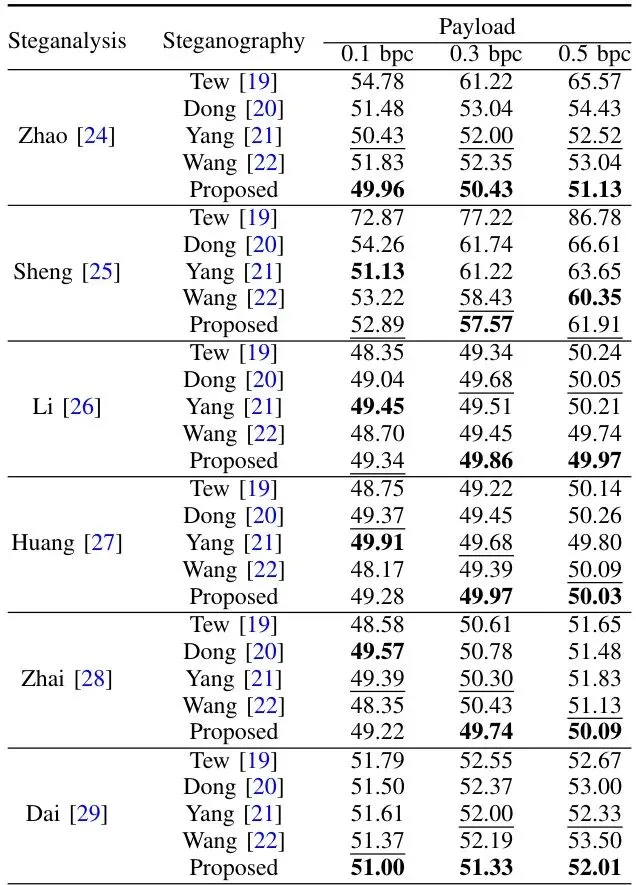
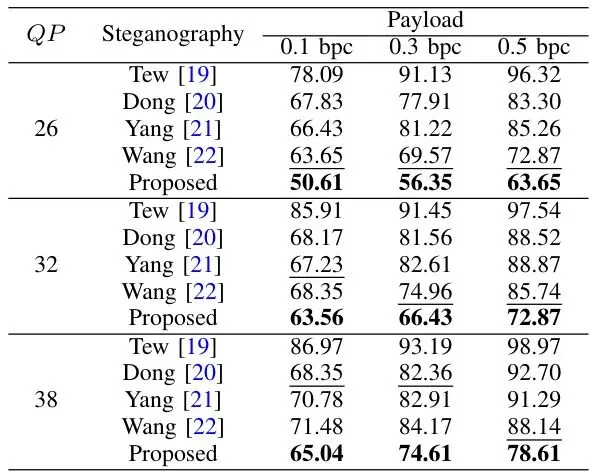
理论很美好,实战怎么样?论文在33个标准测试视频上,与4种最先进的基于块结构的隐写算法进行了全面对比。实验设置如下:结果可谓“全面胜出”。新方法不仅在核心目标——抗隐写分析上大幅领先,在传统的视觉质量、码率控制和嵌入容量指标上,也表现优异或相当。∆PSNR (值越小越好) 衡量由隐写引起的画质下降程度;BIR (值越小越好) 衡量由隐写引起的码率(文件大小)增加比例。表II:五种算法的平均∆PSNR (dB·10⁻¹,↓值越小越好)表III:五种算法的平均BIR (10⁻¹,↓值越小越好)可以看到,新方法(Proposed)在绝大部分情况下,∆PSNR和BIR都是最低的,意味着它引起的画质下降和文件大小增加是最轻微的。 表IV:五种算法的平均容量 (bits,↑值越大越好)在嵌入容量上,新方法显著超越了Tew和Yang的方法,与表现最好的Wang方法处于同一水平。这意味着在获得极高安全性的同时,并没有牺牲携带信息的能力。这是本论文的核心战场。作者用三种隐写分析工具进行测试:两种通用的帧内/帧间分析器,以及他们自己提出的CBSSM分析器。检测准确率越接近50%(随机猜测水平),说明隐写术越安全。表V:五种算法对帧内和帧间隐写分析的检测准确率 (→50% 越好)表VI:五种算法对CBSSM隐写分析的检测准确率 (→50% 越好)1. 对抗通用分析器:新方法的检测准确率在所有对比算法中最接近50%,尤其在低嵌入率(0.1 bpc)时优势明显。 2. 对抗CBSSM分析器(照妖镜):这才是真正的“杀手锏”测试。其他所有方法在CBSSM下的检测准确率都远高于50%(容易被抓),而新方法的准确率几乎完美地保持在50%左右!这直接证明了新方案有效克服了“块结构恢复”导致的漏洞,穿过了自己设计的“照妖镜”。论文还通过消融实验,证明了三级失真函数的关键作用。没有它,方案的抗检测能力会明显下降。
表IV:五种算法的平均容量 (bits,↑值越大越好)在嵌入容量上,新方法显著超越了Tew和Yang的方法,与表现最好的Wang方法处于同一水平。这意味着在获得极高安全性的同时,并没有牺牲携带信息的能力。这是本论文的核心战场。作者用三种隐写分析工具进行测试:两种通用的帧内/帧间分析器,以及他们自己提出的CBSSM分析器。检测准确率越接近50%(随机猜测水平),说明隐写术越安全。表V:五种算法对帧内和帧间隐写分析的检测准确率 (→50% 越好)表VI:五种算法对CBSSM隐写分析的检测准确率 (→50% 越好)1. 对抗通用分析器:新方法的检测准确率在所有对比算法中最接近50%,尤其在低嵌入率(0.1 bpc)时优势明显。 2. 对抗CBSSM分析器(照妖镜):这才是真正的“杀手锏”测试。其他所有方法在CBSSM下的检测准确率都远高于50%(容易被抓),而新方法的准确率几乎完美地保持在50%左右!这直接证明了新方案有效克服了“块结构恢复”导致的漏洞,穿过了自己设计的“照妖镜”。论文还通过消融实验,证明了三级失真函数的关键作用。没有它,方案的抗检测能力会明显下降。未来展望:从“隐藏信息”到“对抗检测”的持续进化
这篇论文标志着视频隐写术研究范式的一次重要转变:从单纯追求“如何把信息藏进去”,升级到“如何藏得让最先进的检测器也找不出来”。它通过深入理解编码器自身的工作原理(块结构恢复),来指导设计更安全的隐写方案,这种思路非常有启发性。当然,这场“猫鼠游戏”永远不会结束。未来的挑战可能包括:1. 更智能的检测器:针对新方法的特点,设计新的分析特征。 2. 面向新一代编码标准:如H.266/VVC,其编码工具更复杂,块结构划分方式更多样(如几何划分),这既带来了新的隐藏机会,也提出了新的安全挑战。 3. 实际部署考量:本方法需要“重新压缩”来计算失真,增加了计算开销。如何平衡安全性与实时性,是实用化需要解决的问题。龙迷三问
什么是视频隐写术?和加密有什么区别?加密是把信息变成乱码,别人知道你在传秘密但看不懂内容。隐写术是直接把秘密信息藏在普通的多媒体文件(如图片、视频)里,让别人根本察觉不到有秘密信息的存在,从而实现“隐蔽通信”。一个改内容,一个藏存在。
论文里的CU具体指什么?CU是Coding Unit的缩写,中文叫编码单元。它是H.265/HEVC等现代视频编码标准中的基本处理单位。编码器会把一帧图像划分成许多个CU,然后对每个CU独立进行预测、变换、量化等压缩操作。CU的大小可以是64x64, 32x32, 16x16, 8x8等。
STC算法是干什么的?STC是一种编码技术,用于实现“失真最小化嵌入”。你可以把它想象成一个非常聪明的“替换工”。给出一串原始的载体比特(比如视频块结构映射的0/1序列)、要隐藏的秘密信息、以及每个载体比特修改的“代价”(即失真函数),STC能计算出一个修改方案,用最小的总代价(对原始载体改动最轻微)来携带秘密信息。它是现代自适应隐写术的核心组件之一。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
从“块结构恢复”现象的发现、理论解释,到CBSSM度量提出,再到基于此设计三级失真函数,整个逻辑链条清晰完整,洞察深刻,创新性突出。实验合理度:★★★★☆
在大量标准测试序列、多种量化参数和嵌入率下,与当前最先进的4种方法进行全方位对比,实验设计全面。用自己提出的CBSSM作为“终极测试”也很有说服力。学术研究价值:★★★★★
价值很高。它不仅提出了一个更好的方法,更重要的是为整个基于块结构的视频隐写领域指出了一个明确的安全漏洞来源和设计原则,具有重要的理论指导意义。稳定性:★★★★☆
方法基于H.265/HEVC编码标准的内在机制,只要标准一致,其“块结构恢复”现象和所提方法的有效性就是稳定的。但依赖于编码器实现细节(如RDO计算)可能带来微小波动。适应性以及泛化能力:★★★☆☆
方法专门针对H.265/HEVC的块结构设计,不能直接用于其他编码标准(如AV1, H.264)。但在H.265/HEVC生态内,对不同内容、分辨率、码率的视频适应性较好。硬件需求及成本:★★★☆☆
需要完整的编码/解码流程,尤其是额外的“重新压缩”步骤来计算失真,计算开销高于一些简单的隐写方法。不适合超低功耗或实时性要求极高的场景。复现难度:★★★★☆
论文描述详细,方法核心步骤清晰。虽然未提供开源代码,但基于公开的HM参考软件和清晰的算法流程,对于该领域的研究者来说复现难度中等。产品化成熟度:★★☆☆☆
目前主要处于学术研究阶段。要产品化需解决几个问题:1) 非盲提取需要原始块结构信息或重新编码,增加了通信或计算负担;2) 计算复杂度;3) 需要对H.265编码器有深入的控制和集成能力。可能的问题:本文方法在安全性上提升显著,但作为非盲隐写,其提取端需要辅助信息或重新编码,在实际秘密通信场景中可能引入额外的脆弱性或复杂度。此外,其安全性增益部分依赖于“模拟重压缩”的准确性,若与实际传输中的转码过程有差异,效果可能打折扣。Zhang, X., Jiang, W., Peng, F., Huang, W., Li, Z., & Fu, Z. (2026). A Video Steganography for H.265/HEVC Based on Multiple CU Size and Block Structure Distortion. arXiv preprint arXiv:2603.22850.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的“阅读原文”,查看更多原论文细节哦!

想和龙哥及更多视频编码、隐写术领域的小伙伴深入交流吗?
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 视频通信+南京+南信大+龙哥),根据格式备注,可更快被通过且邀请进群。