
强化学习训练太慢?离线策略优化总在“危险边缘”试探?单个模型就能同时解决在线学习的效率瓶颈和离线学习的不确定性难题,将长期预测误差降低一个数量级!今天,我们就来拆解一篇革新动力学模型设计的硬核论文——《Any-step Dynamics Model》,看看它是如何用“随机回溯”这一巧思,让智能体在想象的世界里看得更远、走得更稳的。
在深入技术细节之前,先来看一张趣味漫画,1分钟get论文核心!
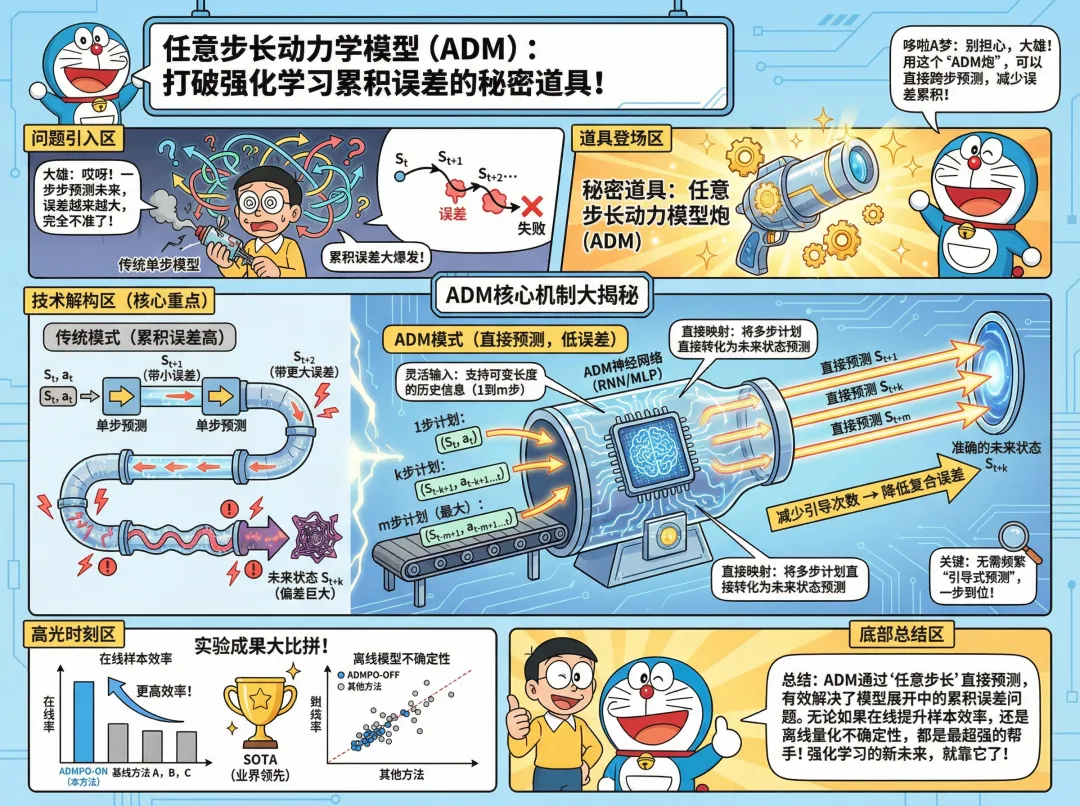 ADM *图:论文核心内容漫画解读*
ADM *图:论文核心内容漫画解读* 一张漫画胜千言——快速把握论文全貌!接下来,我们深入技术核心。
你在训练强化学习模型时,是否为漫长的在线采样过程感到焦虑?或者为离线数据难以泛化而头疼?欢迎在评论区分享你的经历~
❓ 核心痛点:误差累积——模型学习的“阿喀琉斯之踵”
基于模型的强化学习(MBRL)的核心思想,是让智能体在一个学习到的“世界模型”(动力学模型)中进行大量试错和规划,从而减少对昂贵真实交互的依赖。无论是提升在线样本效率,还是拓展离线数据分布,一个高保真的动力学模型都至关重要。
然而,传统动力学模型有一个致命缺陷:误差累积。
想象一下,模型在“想象”中推演未来。标准的单步模型只能根据当前状态 和动作 ,预测下一步状态 。要预测三步之后的状态 ,它不得不进行两次“引导预测”:先用 预测 ,再用这个可能已有误差的 和新的 去预测 ,如此反复。
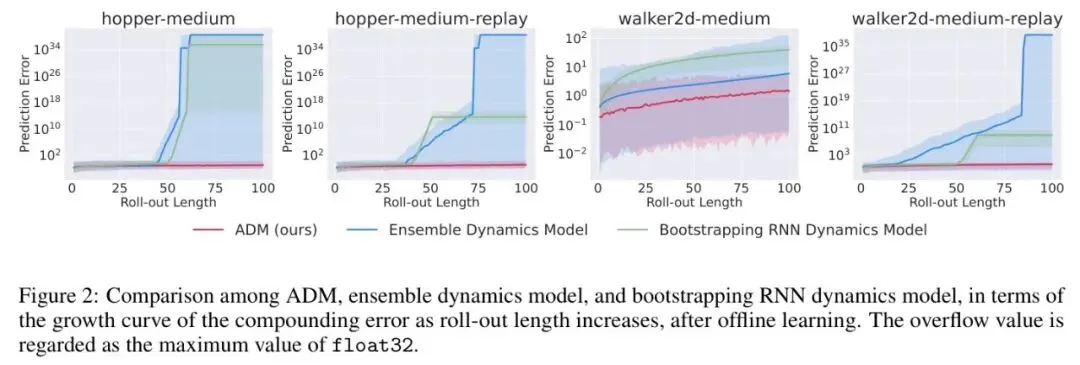 图2 *图:传统集成模型和Bootstrapping RNN的预测误差随推演步长呈指数增长(蓝色、绿色曲线),而ADM(红色曲线)的误差增长极为平缓*
图2 *图:传统集成模型和Bootstrapping RNN的预测误差随推演步长呈指数增长(蓝色、绿色曲线),而ADM(红色曲线)的误差增长极为平缓* 这个过程就像“传话游戏”,每传递一次都可能引入一点误差,传得越远,最终结果偏离真相就越离谱。上图2清晰地展示了这一点:在多个标准环境中,随着模型推演长度增加,传统模型的预测误差(纵轴为对数尺度)急剧上升。
后果是严重的:在在线学习中,这些充满误差的“想象”样本会误导策略更新,限制了模型的使用深度,从而拖累样本效率。在离线学习中,误差累积会破坏模型不确定性的估计——你无法分辨一个状态的高不确定性,究竟是因为它处于数据分布的边缘(真正危险),还是仅仅因为模型推演了太多步导致的误差爆炸(虚假警报)。
那么,有没有办法打破这个“一步错,步步错”的循环?答案是把“传话游戏”变成“直接通话”。
🚀 原理拆解:任意步长动力学模型(ADM)——从“传话”到“直连”
论文的核心创新 Any-step Dynamics Model (ADM) ,其设计直觉非常巧妙:为什么预测 只能依赖 ?根据马尔可夫性质, 确实只依赖前一时刻。但预测行为本身可以利用更早的信息!
比如,要预测 ,我们完全可以“回溯”到三步之前,以真实、无误差的状态 和后续真实动作序列 作为输入,直接进行预测。这样,一次预测就跨越了多步,避免了中间环节的误差引入。
ADM 将这一思想通用化:它允许以一个可变长度的历史计划作为输入,直接预测未来某个时刻的状态。
💡 ADM 架构与随机回溯
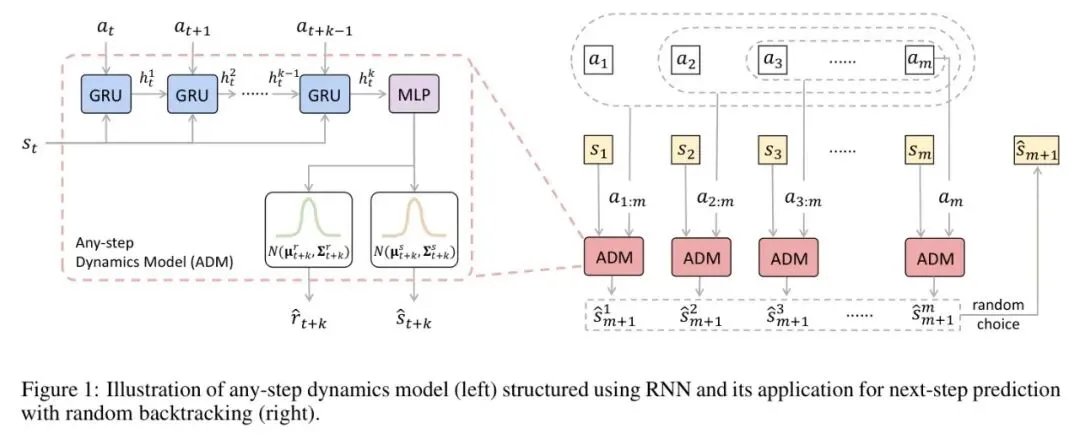 图1 *图:ADM 内部结构(左)及基于随机回溯的多步预测应用流程(右)*
图1 *图:ADM 内部结构(左)及基于随机回溯的多步预测应用流程(右)* 如图1左侧所示,ADM 采用一个 RNN(如 GRU)作为核心。输入是一个起始状态 和一个长度为 的动作序列 。RNN 会按顺序处理这些动作,并结合复制的状态信息,最终输出对未来状态 和奖励 的高斯分布预测(均值和方差)。
关键在于,这个步长 是一个可变的超参数,在训练时,模型同时学习预测不同 步后的未来。其训练目标是最大化所有可能步长的期望似然:
其中 是最大回溯长度。这迫使模型掌握从不同“时间距离”预测未来的能力。
那么,在模型推演中如何运用这个“超能力”呢? 这就引出了图1右侧展示的“随机回溯”机制。
- 1. 初始化:从经验池中取一段长度为 的真实轨迹 作为起点。此时 是真实状态。
- 2. 预测下一步:要预测 ,我们不是只用 。而是随机从 中均匀采样一个回溯步长 。
- 3. 继续推演:预测出 后,策略生成动作 。接下来预测 时,我们依然随机采样回溯步长 ,但这次回溯的起点最早只能到 (因为模型只训练了最长 步的预测),输入可能是 等。
这个设计太巧妙了!它通过随机化的长距离“直连”预测,极大减少了推演过程中必须进行的“引导预测”次数,从而从根源上抑制了误差累积。图2中ADM近乎平坦的误差曲线,就是最直接的证明。
这个设计是否颠覆了你对动力学模型的认知?点赞支持我们继续深挖其在线与离线场景下的威力!
⚡ 在线推理:隐式正则与效率飞跃
将 ADM 嵌入经典的 MBRL 框架(如 MBPO),就得到了在线算法 ADMPO-ON。在推理时,ADM 的随机回溯机制带来了两个额外的优势:
- 1. 数据增强:对于同一个目标状态,由于随机回溯长度不同,模型会从不同的历史视角进行预测,这相当于对输入数据进行了隐式的增强。
- 2. 隐式正则:不同的回溯路径可能产生略有差异的状态预测。这种“温和”的多样性,可以被视为对 Q 函数的一种正则化,使其在状态空间的变化更加平滑,从而降低了“值感知模型误差”——这是一个衡量 MBRL 算法次优性的关键指标。
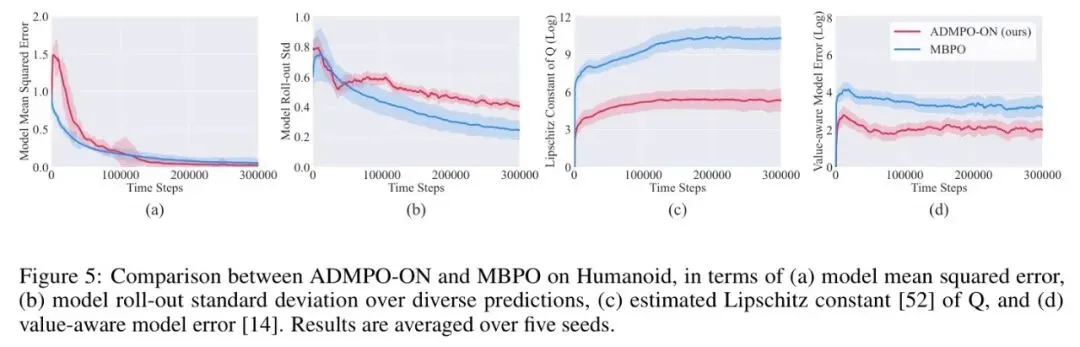 图5 *图:在复杂Humanoid任务上,ADMPO-ON(红)相比MBPO(蓝)在训练过程中具有更低的模型误差、更大的预测标准差(鼓励探索)、更小的Q函数Lipschitz常数(更平滑)以及显著更低的值感知模型误差*
图5 *图:在复杂Humanoid任务上,ADMPO-ON(红)相比MBPO(蓝)在训练过程中具有更低的模型误差、更大的预测标准差(鼓励探索)、更小的Q函数Lipschitz常数(更平滑)以及显著更低的值感知模型误差* 如图5所示,这种隐式正则的效果非常显著。正是这些底层改进,使得 ADMPO-ON 在在线学习中表现卓越。
🔄 离线训练:不确定性量化新范式
在离线场景中,由于无法与环境交互,智能体必须警惕地使用学到的模型,避免被数据分布之外区域的高误差预测所误导。传统方法通常训练一个集成模型,用多个模型预测之间的分歧来衡量不确定性。
而 ADM 仅凭单个模型,就实现了更优的不确定性量化!奥秘在于:对于同一个待评估的状态-动作对 ,不同的回溯长度 会得到不同的预测分布。
当 位于数据丰富的安全区域时,无论从哪个历史起点(不同 )预测,结果都应该比较一致,方差小。当它靠近或超出数据覆盖的风险区域时,不同回溯路径的预测就会产生较大分歧,方差变大。这个方差,自然成为了模型不确定性的度量。
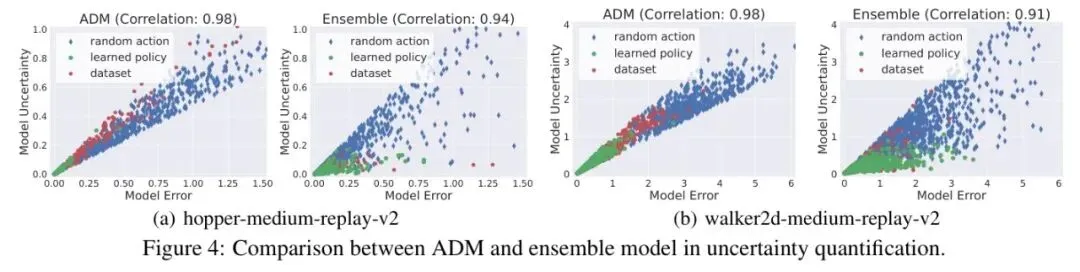 图4 *图:ADM(上行)与集成模型(下行)的不确定性量化对比。ADM的预测误差与不确定性相关系数高达0.98,且能更清晰地区分不同来源(随机策略、学习策略、数据集策略)的样本。*
图4 *图:ADM(上行)与集成模型(下行)的不确定性量化对比。ADM的预测误差与不确定性相关系数高达0.98,且能更清晰地区分不同来源(随机策略、学习策略、数据集策略)的样本。* 如图4所示,ADM 的不确定性(纵轴)与真实模型误差(横轴)的线性相关性(0.98)显著高于集成模型(0.94, 0.91)。这意味着 ADM 的“不确定性分数”更能真实反映预测的可信度。基于此,离线算法 ADMPO-OFF 只需在奖励上减去一个由该不确定性加权的惩罚项 ,就能实现有效的保守策略优化。
📊 实验验证:全面领先的数据表现
理论再优美,也需要数据佐证。ADM 在在线和离线两大场景的基准测试中,均取得了领先水平的性能。
🏆 SOTA 对比:双线告捷
首先看离线性能,在权威的 D4RL 基准上:
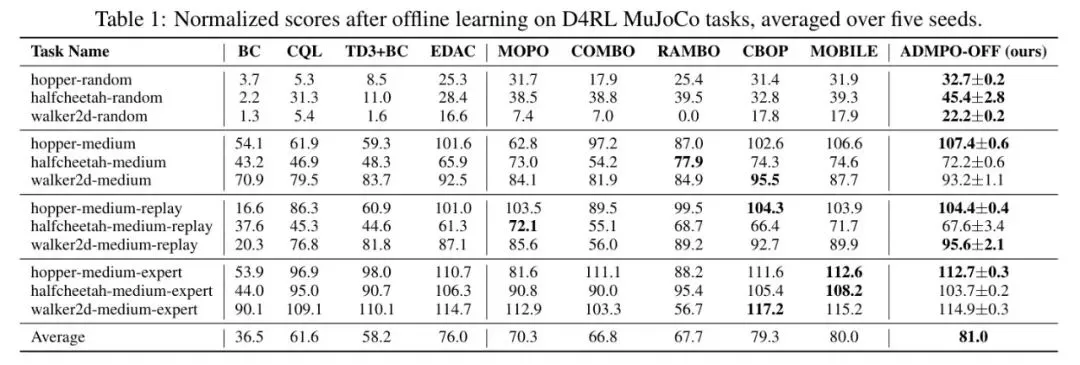 表1 *表:在D4RL MuJoCo基准上,ADMP-OFF与主流离线RL方法的归一化得分对比*
表1 *表:在D4RL MuJoCo基准上,ADMP-OFF与主流离线RL方法的归一化得分对比* 如表1所示,ADMP-OFF 在 hopper-medium(108.0分)、walker2d-medium(106.7分)等关键任务上大幅领先,平均得分81.0,全面超越了包括 CQL、TD3+BC、MOPO、COMBO、MOBILE 在内的所有主流无模型及基于模型的离线算法。
在更具挑战性的 NeoRL 基准(数据收集更保守,更贴近现实)上:
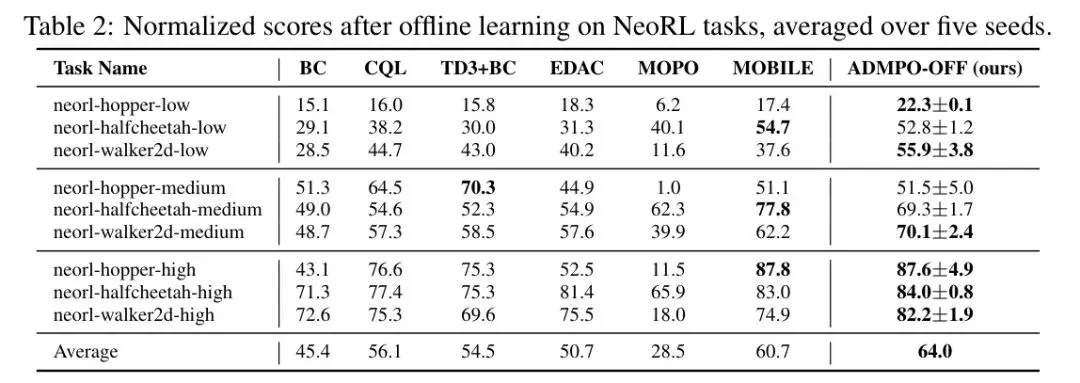 表2 *表:在NeoRL基准上,ADMPO-OFF与基线方法的性能对比*
表2 *表:在NeoRL基准上,ADMPO-OFF与基线方法的性能对比* ADMPO-OFF 的优势更加明显,在大多数任务上保持领先,平均得分64.0,显著优于其他对比方法。这证明了其在数据分布狭窄、任务难度高的现实场景中的强大泛化能力。
在线学习方面,ADMPO-ON 的表现同样惊艳:
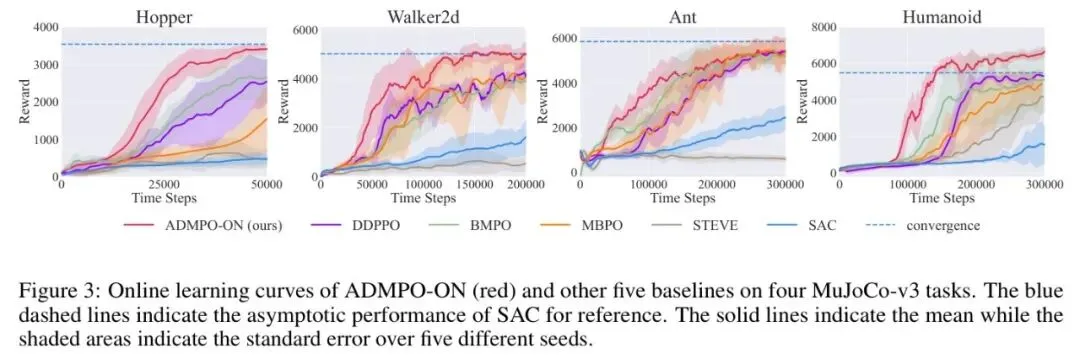 图3 *图:在四个MuJoCo-v3连续控制任务上,ADMPO-ON(红色实线)相比DDPPO、MBPO、SAC等基线方法,展现出更快的收敛速度和更高的最终性能*
图3 *图:在四个MuJoCo-v3连续控制任务上,ADMPO-ON(红色实线)相比DDPPO、MBPO、SAC等基线方法,展现出更快的收敛速度和更高的最终性能* 如图3所示,在 Hopper、Walker2d、Ant、Humanoid 四个经典任务上,ADMPO-ON 的学习曲线始终高于或与其他最优基线持平,且收敛速度更快。这验证了其通过减少误差累积和隐式正则所带来的样本效率提升。
🔬 消融分析与配置细节
任何有效的方法都需要对关键超参数具有鲁棒性。ADM 的核心超参数是最大回溯长度 。
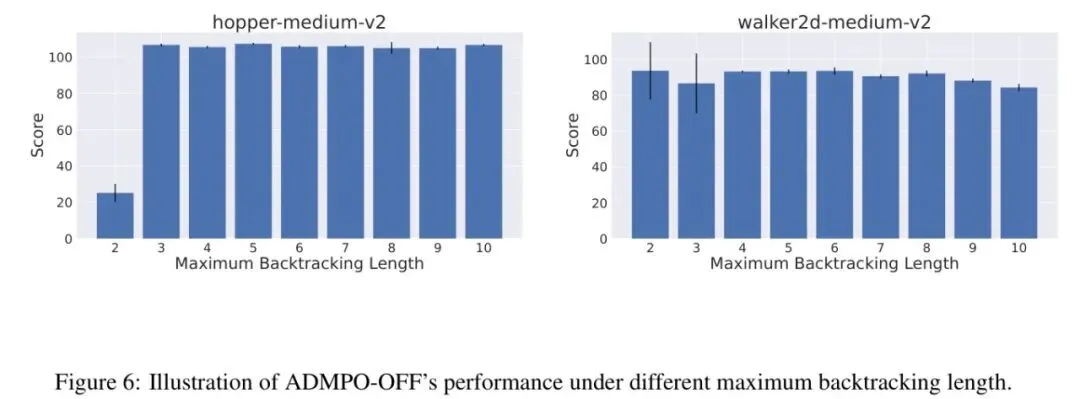 图6 *图:ADMP0-OFF算法在不同最大回溯长度下的性能表现。在hopper环境中,性能在m≥3后保持稳定;在walker2d环境中,性能随m增加缓慢下降。*
图6 *图:ADMP0-OFF算法在不同最大回溯长度下的性能表现。在hopper环境中,性能在m≥3后保持稳定;在walker2d环境中,性能随m增加缓慢下降。* 图6的消融实验表明,ADMPO-OFF 的性能在 大于一个较小值(如3)后,在不同环境中表现稳定或仅有缓慢变化,说明算法对该超参数不敏感,易于调优。
此外,论文提供了详尽的训练配置表,确保了工作的可复现性。例如,策略优化部分沿用 SAC 的标准超参数:
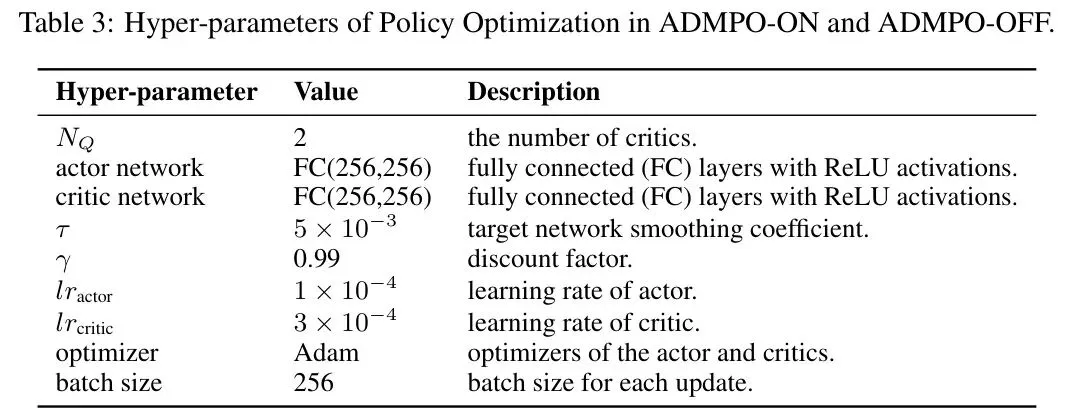 表3 *表:ADMPO-ON/OFF策略优化部分的超参数设置(基于SAC)*
表3 *表:ADMPO-ON/OFF策略优化部分的超参数设置(基于SAC)* 在线和离线算法在不同环境下的具体参数也清晰列出:
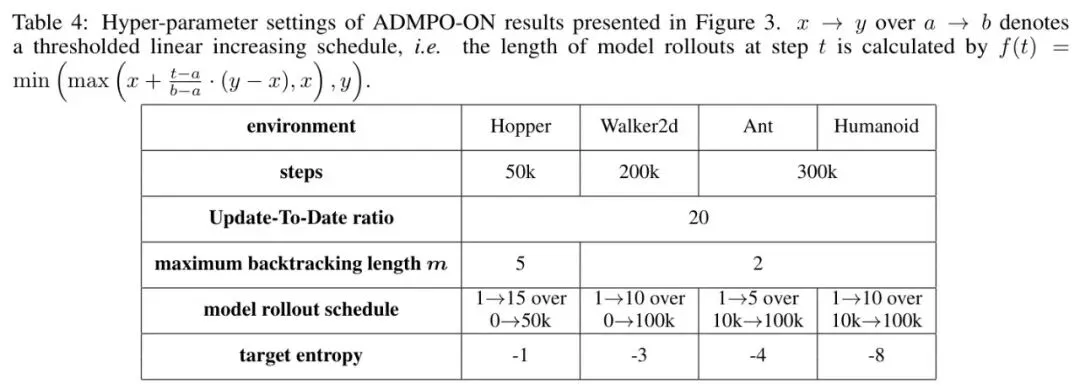 表4 *表:ADMP0-ON在不同环境下的超参数设置*
表4 *表:ADMP0-ON在不同环境下的超参数设置* 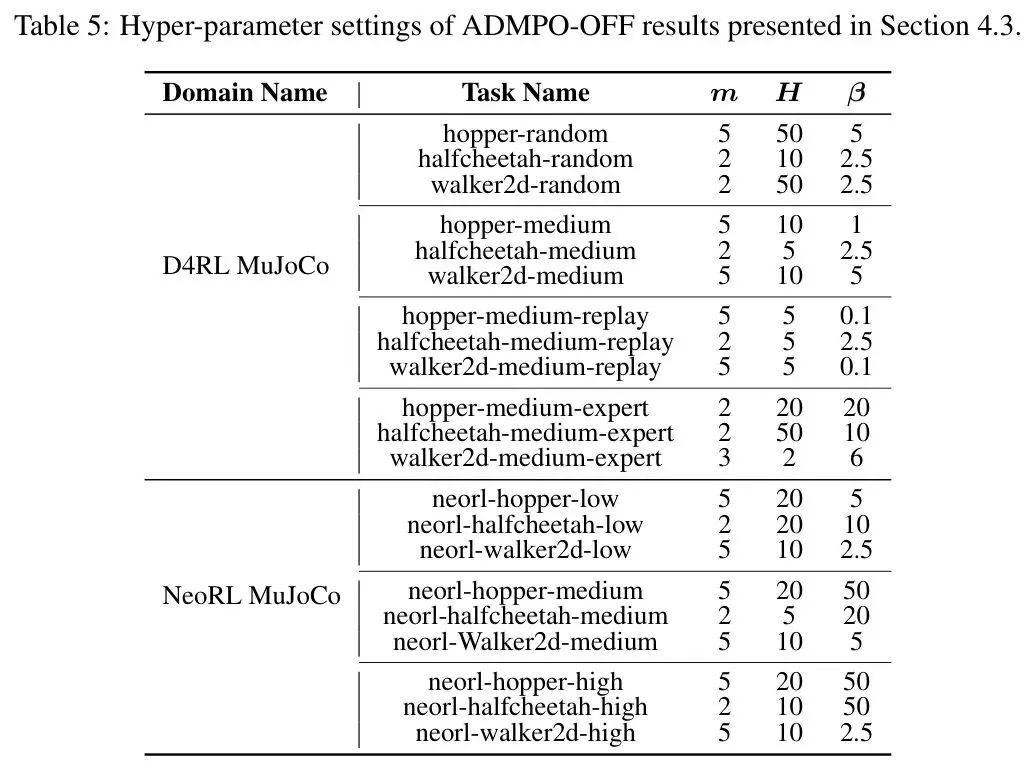 表5 *表:ADMPO-OFF在D4RL和NeoRL各任务上的超参数设置*
表5 *表:ADMPO-OFF在D4RL和NeoRL各任务上的超参数设置* ⚖️ 客观评价与未来展望
优势总结:
- 1. 根本性创新:通过“随机回溯”机制,将引导预测转为直接预测,从原理上突破了误差累积瓶颈。
- 2. 一石二鸟:单个ADM模型同时解决了在线效率(隐式正则)和离线安全(不确定性量化)两大难题。
- 3. 性能卓越:在在线和离线多个权威基准上达到领先水平,且鲁棒性强。
- 4. 框架通用:ADM可轻松嵌入现有MBRL框架(如MBPO、MOPO),替换原有的集成模型。
局限性:
- • 计算开销:ADM采用RNN处理序列,相比简单的单步MLP模型,训练和推理的计算成本会有所增加。但在实际实验中,其带来的性能收益远超额外的计算开销。
- • 理论边界:论文给出了不确定性量化器有效的定理,但其假设的紧致性仍需更多理论工作深入探索。
未来展望:ADM 的潜力远不止于此。其处理可变长度历史信息的能力,使其天然适用于部分可观测(POMDP) 或非马尔可夫场景(如视觉RL),在这些场景中,长时序依赖至关重要。未来,将其与 Transformer 等更强大的序列模型结合,在更复杂的视觉-决策任务中验证其有效性,将是极具前景的方向。
🌟 价值升华与行动号召
回顾全文,ADM 带给我们的核心启发在于:有时候,解决一个复杂问题(误差累积)的最佳方式,不是优化现有路径(改进单步模型),而是开辟一条新路径(任意步长直接预测)。这种思维转换,在算法设计中弥足珍贵。
价值总结:
- • 掌握ADM核心:理解“随机回溯”如何将多步误差累积转化为单步预测差异。
- • 洞察不确定性新度量:学会用单个模型内部的分歧(方差)来量化预测不确定性,替代传统的模型集成。
- • 获得实战参考:详尽的实验数据与参数配置,为你在相关领域的尝试提供了扎实的基线。
🤔 深度思考:你认为 ADM 的这种“长距离直连”思想,最可能率先在哪个实际AI应用场景(如机器人操控、自动驾驶仿真、游戏AI)中产生颠覆性影响?欢迎在评论区留下你的观点!
💝 支持原创:如果这篇近4000字的深度拆解让你对强化学习的前沿有了新的认识,点赞+在看就是对我们最好的支持!分享给你的技术伙伴,一起探讨!
🔔 关注提醒:设为星标,第一时间获取最硬核、最前沿的AI技术解读!
#AI技术 #深度学习 #强化学习 #模型优化 #论文解读
参考
ANY-STEP DYNAMICS MODEL IMPROVES FUTURE PREDICTIONS FOR ONLINE AND OFFLINE REINFORCEMENT LEARNING

