🐉 龙哥读论文知识星球来了!视频加密、隐私保护、编码优化……想第一时间获取这些领域的最新论文解读吗?星球每日更新海量AI前沿论文、资讯、招聘、开源代码,帮你节省90%的文献调研时间!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
视频隐私保护是个老话题,但如何在保证背景信息完整的同时,对敏感区域进行“像素级”的精准加密,一直是技术难点。这篇来自南京信息工程大学的论文,巧妙地将前沿的提示分割技术与H.265编码标准深度融合,把加密精度从“马赛克块”级别提升到了“像素块”级别,并成功解决了加密扩散的顽疾。对于关注视频安全、编码优化的同学来说,这是一次非常扎实且有启发性的技术演进,值得细品!
原论文信息如下:
论文标题:
A H.265/HEVC Fine-Grained ROI Video Encryption Algorithm Based on Coding Unit and Prompt Segmentation
发表日期:
2026年04月
发表单位:
南京大学信息工程大学(工程研究中心数字取证教育部),广州大学
原文链接:
https://arxiv.org/pdf/2604.08047v1.pdf
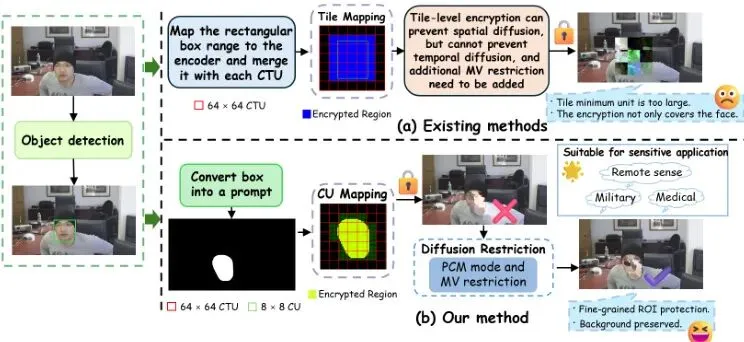
大家在视频通话或者看监控录像时,有没有想过一个问题:画面里你的脸或者车牌号这些敏感信息,能不能只给它们打上“马赛克”,而让背景的街道、房间摆设都清晰可见呢?这其实就是ROI视频加密(Region of Interest, 感兴趣区域)要干的事。ROI就是你不想让别人看清楚的那部分画面。听起来很美,但现实很骨感。目前主流的方法,比如基于H.265/HEVC这个视频编码标准的加密,存在一个大问题:加密精度太“糙”了。看上图左边。传统方法用Tile(可以理解成视频画面被切成的“大砖块”)作为最小加密单元。一旦检测到人脸(绿色框),它就把整个包含人脸的Tile(红色框)都加密了。看见没?脖子以下、肩膀旁边那些本来清晰可见的背景(比如衣服、桌面),也被无辜地“马赛克”了。这种“宁可错杀一千,不可放过一个”的粗糙策略,在普通视频通话里也许能忍。但换到一些敏感得要命的场景,就抓瞎了:想象一下,一位医生正在通过远程视频指导一场手术。为了保护病人隐私,需要加密病人的面部。但如果加密区域过大,不小心把手术器械、关键的组织部位也弄模糊了,医生还怎么精准指导?😱再比如军事侦察或遥感领域,需要加密我方车辆、人员,但同时必须100%保留周围的地形、建筑等环境信息用于分析。背景信息哪怕有一丁点失真,都可能影响决策。所以,“加密要准,背景要清”,成了高敏感领域视频隐私保护的头号难题。传统的Tile级加密,就像用一把大刷子涂鸦,很难满足这个精细活儿的要求。破局:当ROI加密遇上提示分割与最小CU
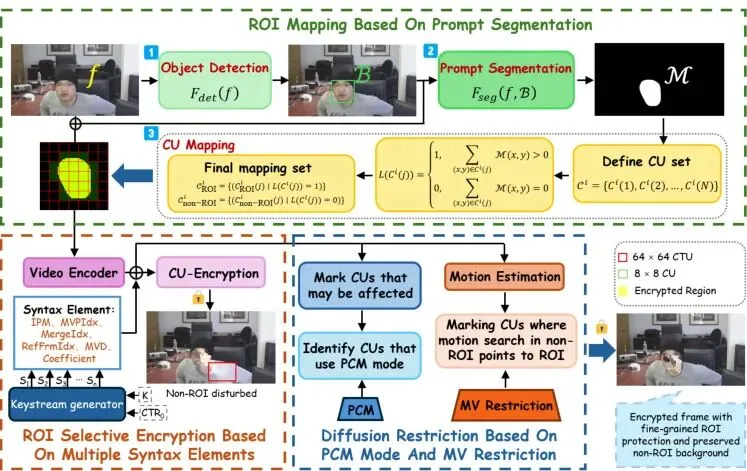
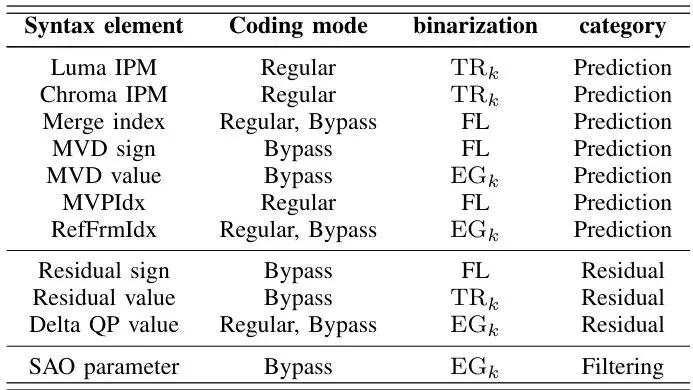
南京信息工程大学的团队想了个妙招。他们问:既然Tile太大,那有没有更小的“积木块”可以用来加密呢?有!在H.265/HEVC编码标准里,有一个比Tile小得多的基本单位,叫做CU(Coding Unit, 编码单元)。它的尺寸可以小到只有8x8像素。如果用CU来当加密单元,那精度不就上来了吗?第一,如何把ROI精准地映射到CU上?你不能只靠一个矩形框(bounding box)去圈定人脸,那样还是会圈进很多背景。你需要一个像素级的“蒙版”(mask),精确标出哪些像素是人脸,哪些不是。第二,如何防止加密“污染”背景?H.265的视频压缩不是一张张独立图片,而是前后帧互相参考(预测)。如果你只加密了某个CU(比如人脸的一部分),在压缩时,相邻的、未加密的背景CU可能会参考这个已被加密的CU来预测自己,导致加密的“失真”像瘟疫一样扩散到背景区域。这就是加密扩散问题。Tile之所以能避免这个问题,是因为各个Tile之间是独立编码,互不参考的。一旦我们放弃Tile,改用CU,就必须直面这个挑战。1. 引入提示分割(Prompt Segmentation)技术,先检测物体(如人脸)框,再以此框为“提示”,让分割模型输出像素级蒙版,实现ROI的精准勾勒。2. 提出一套扩散隔离机制,巧妙利用H.265标准里的“PCM模式”和“运动矢量限制”,给背景CU穿上“防护服”,让它们不被ROI的加密所影响。最终目标,就是实现图1右边那种效果:加密区域严丝合缝地贴合人脸轮廓,而周围的背景(衣服、肩膀)干干净净,清晰如初。这就像是给视频里的敏感区域戴上了一个量身定制的“像素级模糊面具”。核心:三管齐下,实现精准加密与扩散隔离
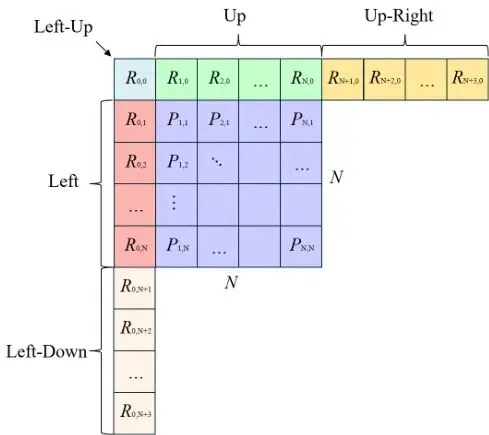
整个方案就像一个精密的流水线,分为三个核心模块,环环相扣。我们先来看它的整体框架图:目标是生成一个像素级蒙版,并把它映射到视频编码的最小单位CU上。1. 物体检测:用检测模型(比如YOLO)在当前视频帧里找到目标(如人脸),给出一个大致的外接矩形框B。2. 提示分割:把上一步得到的矩形框B作为“提示”(Prompt),输入给一个强大的分割模型(如SAM, Segment Anything Model)。这个模型会输出一个极其精细的像素级二值蒙版M,白色(1)代表ROI(人脸),黑色(0)代表背景。3. CU映射:H.265编码器会把画面分成一个个CTU(最大编码单元),CTU再递归分割成各种尺寸的CU。论文设计了一个简单的映射规则:遍历当前帧的所有CU,如果一个CU内部至少有一个像素在分割蒙版M中是白色(属于ROI),那么这个整个CU就被标记为“ROI-CU”,需要被加密。否则就是“非ROI-CU”。有了要加密的CU列表,下一步就是“怎么加密”。论文没有选择加密整个像素数据(那样太笨重,且不兼容编码器),而是选择加密H.265码流中的一些语法元素。语法元素是构成视频码流的基本数据单元,解码器靠它们来重建画面。加密不同的语法元素,会产生不同的视觉扰动效果。本论文瞄准了那些对视觉影响大、但本身数据量不大的语法元素进行联合加密,包括:· 预测相关:帧内预测模式(IPM)、运动矢量预测索引(MVPIdx)、合并索引(MergeIdx)、参考帧索引(RefFrmIdx)、运动矢量差值(MVD)的符号和数值。加密方法主要是异或(XOR)或者循环移位,密钥由AES-CTR算法生成。这样一来,ROI-CU在解码后就会呈现出严重的、无法识别的像素混乱,从而达到保护隐私的目的。这是整个方案的灵魂所在,解决了放弃Tile后最棘手的加密扩散问题。扩散主要发生在两种预测中:1. 帧内预测扩散隔离(用PCM模式):帧内预测是指利用同一帧内已重建的相邻块像素来预测当前块。看图3,当前CU(蓝色)预测时,会参考上方、左方等多个方向(红色箭头)的像素。如果相邻的参考像素恰好来自一个已被加密的ROI-CU(像素是混乱的),那么用这些混乱像素预测出来的当前CU(即使是背景CU)也会变得混乱。这就是帧内预测导致的扩散。论文的解决方案非常巧妙:它给那些紧挨着ROI边界的背景CU,强制启用一种叫做PCM(Pulse Code Modulation, 脉冲编码调制)的编码模式。PCM模式是H.265标准里的一个“异类”。当CU采用PCM模式时,它完全绕过预测、变换、量化所有这些可能引入依赖的步骤,直接对原始像素值进行(近乎)无损编码。相当于给这些边界上的背景CU建起了一堵“绝缘墙”。它们不参考任何邻居(包括混乱的ROI邻居),只忠实记录自己的原始样子。这样,ROI的加密失真就无法通过帧内预测渗透过来了。2. 帧间预测扩散隔离(用MV限制):帧间预测是指利用其他帧(参考帧)的像素来预测当前帧。一个背景CU在预测时,它的运动矢量(MV)可能会指向参考帧中的一个ROI区域。如果那个ROI区域在参考帧中已被加密,那么当前背景CU的预测值就会出错,导致扩散。论文的对策是:在运动估计过程中,对背景CU施加一个限制——禁止它的运动矢量指向参考帧中的任何ROI-CU。如果算出来的最佳运动矢量指向了ROI,那就退而求其次,找一个指向非ROI区域的次优运动矢量。这就好比导航时,系统会自动规避“施工(加密)路段”,为你规划一条只经过“畅通(非加密)路段”的路线,保证你到达目的地的信息是干净、准确的。通过“PCM模式”和“MV限制”这一内一外两重保险,论文成功地将加密失真牢牢锁死在ROI-CU内部,实现了真正的精准隔离。验证:精度与效果双提升,理论分析解疑惑
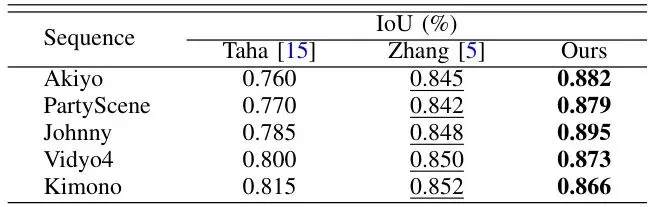
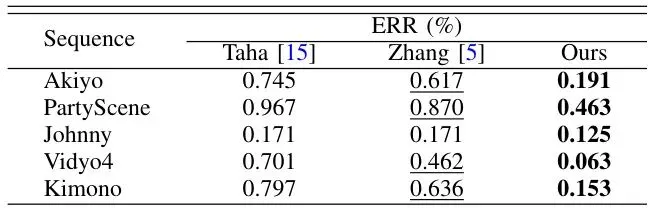
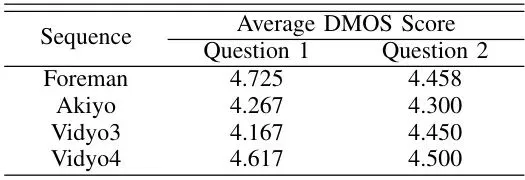
论文通过详尽的实验和理论推导,证明了本方法的优越性。我们挑几个重点看看。先看一个直观的消融实验,证明扩散隔离机制的有效性:中间那列,没有扩散隔离。可以看到人脸(ROI)被加密成乱码的同时,人脸周围的头发、肩膀、衣服(背景)也出现了大面积的、有规律的块状或条状失真,这就是加密扩散。而最右边,采用了扩散隔离后,背景干净如初,只有人脸区域被精准扰乱。第二列(Taha)和第三列(Zhang)是两种现有的Tile级加密方法。明显看出,它们为了覆盖整个人脸,把大量的背景区域(脖子、衣领、头发边缘)也加密了,画面损失很大。而第四列本文的方法,加密区域与人脸轮廓高度吻合,背景保留完整。· 交并比(IoU):衡量算法找到的加密区域与真实ROI区域的重合程度。越高说明定位越准。可以看到,本文方法在多个视频序列上的IoU都显著高于两个Tile级对比方法。因为Tile会包含多余背景,所以IoU低;而CU级映射更贴合真实轮廓,所以IoU高。· 错误率(ERR):衡量加密区域超出真实ROI区域的比例(即“错杀”的背景比例)。越低越好。同样,本文方法的ERR远低于对比方法,说明其“误伤”的背景区域要少得多。· 主观评分(DMOS):邀请观察者对加密后视频的背景质量进行打分。分数越高,表示背景失真越少,视觉体验越好。本文方法的DMOS分数在多个序列中达到或接近满分(5分),意味着观察者几乎感觉不到背景有失真,而对比方法的背景质量得分则低很多。论文不仅做了实验,还从理论上分析了为什么CU级加密在控制扩散上天然优于Tile级。核心在于一个参数:γ(伽马)。γ 代表ROI边界长度与其面积的比值。Tile是大的方形块,所以边界相对较短(γ_Tile 小);而CU级加密区域更不规则,更贴合物体轮廓,因此边界更长(γ_CU 大)。论文通过建模推导(这里省略复杂公式),得出结论:在采取相同的扩散隔离措施后,加密引起的总失真会随着预测的传递而累积。而累积的总失真上限与 (1 - λ·γ) 成反比。其中 λ 是预测依赖强度。由于 γ_CU > γ_Tile,所以分母 (1 - λ·γ_CU) < (1 - λ·γ_Tile)。这意味着,CU级加密方案最终的累积失真上限,要低于Tile级方案。从理论上证明了本文方案在控制扩散方面的优越性。上表也从实验上佐证了这一点,CU级加密区域(Ω_CU)的平均残差能量显著低于Tile级区域(Ω_Tile),说明其引起的编码失真更小、更集中。展望:更优扰动与更强隔离是未来方向
这篇论文无疑将ROI视频加密的精度提升到了一个新的高度。但它也打开了新的研究大门:1. 更“聪明”的扰动:目前的加密是在语法元素上做异或或移位,产生的视觉扰动是随机的噪声块。未来是否可以设计更符合人类视觉特性的扰动?比如,将人脸替换为统一化的卡通头像或马赛克图案,在保护隐私的同时,提供更好的视觉连贯性和用户体验。2. 更强的隔离与效率平衡:本文使用的PCM模式虽然隔离效果好,但它是一种低压缩效率的编码方式,可能会增加最终的视频码率(文件大小)。未来的研究需要探索在保证隔离效果的前提下,对压缩效率影响更小的机制。无论如何,这篇论文为我们展示了将前沿AI视觉技术(提示分割)与经典视频编码标准(H.265/HEVC)深度融合来解决实际工程难题的成功范例,思路清晰,效果扎实,值得深入思考和借鉴。龙迷三问
这篇论文到底解决了什么问题?解决了传统视频ROI(感兴趣区域)加密方法精度低、会误伤背景区域的问题。特别是在医疗、军事等敏感场景,需要在完美加密ROI(如人脸)的同时,100%保留背景信息的完整性,传统基于“Tile”(大砖块)的加密方法做不到,而本文提出的基于“CU”(最小编码单元)和“提示分割”的方法做到了。
文中的PCM模式是什么?怎么起到隔离作用的?PCM(脉冲编码调制)是H.265/HEVC标准中一种特殊的编码模式。当视频块采用PCM模式时,编码器会“偷懒”,不做复杂的预测、变换和量化,而是直接把原始像素数据(或轻微压缩后)写入码流。论文利用了这个特性:给那些紧挨着加密区域的背景块强制使用PCM模式。这样一来,这些背景块在编码时就完全不依赖其周围已被加密的混乱像素,像戴上了“耳塞”和“眼罩”,从而实现了加密失真无法通过帧内预测扩散过来的效果。
“提示分割”和普通分割有什么区别?“提示分割”(Prompt Segmentation)是近年来非常火的一种分割范式,代表模型是SAM(Segment Anything Model)。它与传统需要针对特定类别训练的分割模型不同,其最大特点是可以通过“提示”来指导分割。这个提示可以是一个点、一个框、一段文本等。本文先用人脸检测框得到一个矩形“提示”,然后输入给提示分割模型,模型就能输出这个框内目标的精细像素级蒙版。这比只用检测框更精准,也比训练一个专用的人脸分割器更灵活、更通用。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将提示分割技术引入ROI获取,并与H.265编码的CU深度绑定,实现了加密粒度的跃升;同时,创造性利用标准内PCM模式解决CU级加密的扩散难题,思路巧妙且合理。扣一星在于核心组件(提示分割、PCM模式)并非首创,但组合创新和应用场景创新非常突出。实验合理度:★★★★☆
实验设计全面,涵盖了视觉对比、客观指标(IoU, ERR)、主观质量评分(DMOS)以及理论分析。对比方法选择了有代表性的近期Tile级工作,消融实验清晰地证明了各模块的必要性。理论推导为实验现象提供了有力支撑。学术研究价值:★★★★★
为视频隐私保护领域开辟了一条从“粗糙Tile”到“精细CU”的新技术路径。其“AI精准感知+编码层深度操控”的范式,对视频编码与安全、计算机视觉的交叉研究有很高的启发价值。提出的扩散隔离机制具有普适性,可被后续研究借鉴。稳定性:★★★☆☆
依赖于外部目标检测和提示分割模型的精度。如果检测框不准或分割蒙版有误,会直接影响加密区域的准确性。在复杂背景、遮挡或快速运动场景下可能存在风险。加密算法本身基于标准语法元素,稳定性较好。适应性以及泛化能力:★★★★☆
方法框架具有较好的泛化性。通过更换检测和分割模型,可以保护任意类别的ROI(人脸、车牌、特定物品等)。但整体方案深度耦合H.265/HEVC标准,迁移到其他编码标准(如AV1, VVC)需要做相应的适配工作。硬件需求及成本:★★★☆☆
增加了目标检测和提示分割的AI计算开销,在编码前需要额外处理时间,可能影响实时性。编码器端因使用PCM模式和MV限制,计算复杂度也有小幅增加。不适合算力极其受限的端侧设备实时应用。复现难度:★★☆☆☆
需要集成目标检测、提示分割模型,并深度修改H.265/HEVC编码器(开源如x265)以植入CU映射、多语法元素加密、PCM强制启用和MV限制逻辑。涉及计算机视觉和视频编码两个复杂领域,工程实现门槛较高。产品化成熟度:★★☆☆☆
目前更偏向于学术原型验证。要产品化,需优化AI模型的效率与精度平衡,解决实时处理延迟,并严格测试在各种复杂场景下的鲁棒性。在云转码、专业级监控系统等对精度要求极高、对延迟不敏感的场景中有应用潜力。可能的问题:方法性能高度依赖于前置AI模块的准确性;强制PCM模式可能带来码率上升;整体系统延迟增加,实时应用需优化;实验主要在标准测试序列上进行,缺乏极端真实场景的鲁棒性验证。
[1] Xiang Zhang, Haoyan Lu, Ziqiang Li, et al. A H.265/HEVC Fine-Grained ROI Video Encryption Algorithm Based on Coding Unit and Prompt Segmentation. arXiv preprint arXiv:2604.08047v1, 2026.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想和更多对视频编码、隐私保护感兴趣的小伙伴交流吗?
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 视频加密+南京+南信大+龙迷),根据格式备注,可更快被通过且邀请进群。