| Annual Meeting of the Association for Computational Linguistics,简称ACL,是自然语言处理与计算语言学领域最具影响力的顶级学术会议,被中国计算机学会(CCF)推荐为A类会议。ACL聚焦于计算语言学及自然语言处理的前沿理论与技术,涵盖的核心研究领域包括但不限于语言模型与表示学习、机器翻译与多语言处理、信息抽取与文本挖掘、问答系统与对话交互、情感分析与观点挖掘、篇章与语义分析、语音与多模态语言理解、伦理与偏见检测,以及面向自然语言处理的机器学习方法等与人类语言计算密切相关的各个方向。NUAA NLP LAB 5篇文章被ACL 2026录用,涉及神经语言解码、不确定性量化、KV缓存压缩与内存管理、细粒度实体分类、思维链压缩与高效推理。 |
录用论文信息
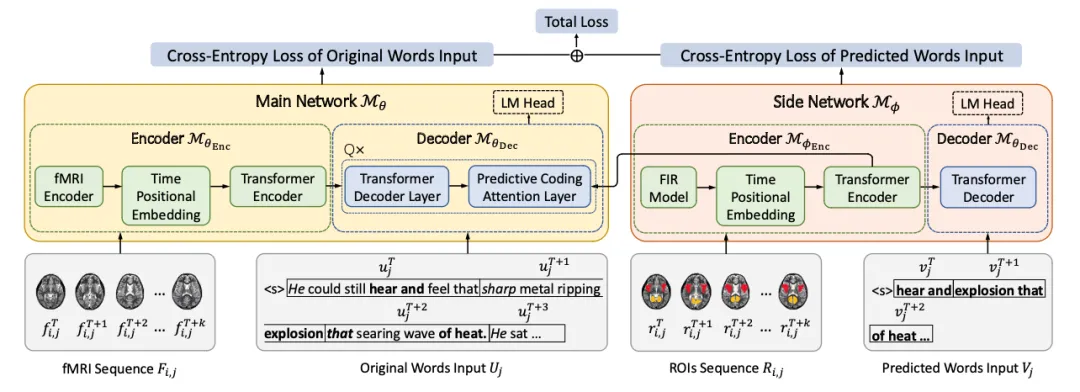
Language Reconstruction with Brain Predictive Coding from fMRI Data
作者:殷聪驰,叶子逸,李丕绩*
类型:Main Conference
作者单位:南京航空航天大学,复旦大学
摘要:近年来,许多研究表明,可以从脑信号中解码对语音的感知,并随后将其重建为连续的语言。然而,关于如何更有效地利用脑信号中蕴含的语义信息来指导语言重建,目前仍缺乏神经学基础。预测编码理论指出,人类大脑天生就会不断地预测跨越多个时间尺度的未来词汇。这意味着脑信号的解码可能与可预测的未来具有潜在的关联。
为了在语言重建的背景下探索预测编码理论,本文提出了PredFT(结合预测编码的fMRI到文本解码,fMRI-to-Text decoding withPredictive coding)。PredFT由一个主网络和一个侧网络组成。侧网络通过自注意力模块从相关的感兴趣区域(ROIs)中获取大脑预测表征。随后,该表征被融合到主网络中,用于进行连续的语言解码。在两个自然语言理解fMRI数据集上的实验表明,PredFT在多项评估指标上均优于现有的解码模型。
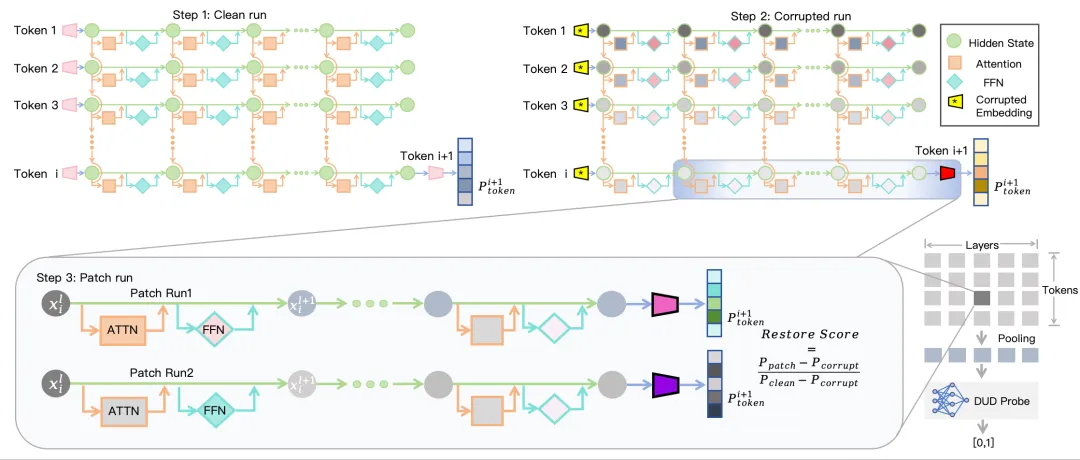
DUD: Decoupled Update Dynamics for Reliable Uncertainty Quantification in Large Language Models
作者:卜宜昕,夏润泽,邹冠云,纪宇鹏,刘浩东,李丕绩*
类型:Main Conference
作者单位:南京航空航天大学
摘要:近期,大语言模型(LLMs)在高风险场景下的可靠部署对不确定性量化(UQ)提出了更高要求。然而,传统基于输出概率的方法往往无法真实反映模型的内部认知状态,而现有的机制可解释性方法虽利用隐藏状态动态,却将前馈网络(FFN)与注意力机制(Attention)的贡献混合聚合,掩盖了两者之间细粒度的机制冲突信号。
为解决上述问题,我们提出了解耦更新动态(DUD)框架,这是一种将不确定性量化从被动估计转变为主动机制诊断的新方法。DUD通过噪声诱导的因果干预,显式解耦FFN(参数记忆)与注意力机制(上下文路由)的因果贡献,分别量化各模块在噪声扰动状态下的独立恢复能力,并构建双流动态特征向量,作为模型内部脆弱性的代理指标。实验发现,生成错误并非均匀分布,而是呈现出特定的时空脆弱模式:早期层注意力模块的路由不稳定性与深层FFN的参数记忆崩溃,共同构成不确定性的核心来源。
实验结果表明,DUD-Probe在三种主流开源大语言模型(LLaMA-3.1-8B、Qwen2.5-7B、Gemma-2-9B)和四个知识密集型基准数据集上均取得了最优的不确定性估计性能(AUROC最高达0.949),显著优于语义熵等基于logits的方法及聚合式机制探针。消融实验验证了FFN与注意力双流解耦的必要性,跨数据集迁移实验也证明DUD-Probe具备强大的域外泛化能力,性能衰减不超过5%,远低于基线方法的15%~20%。
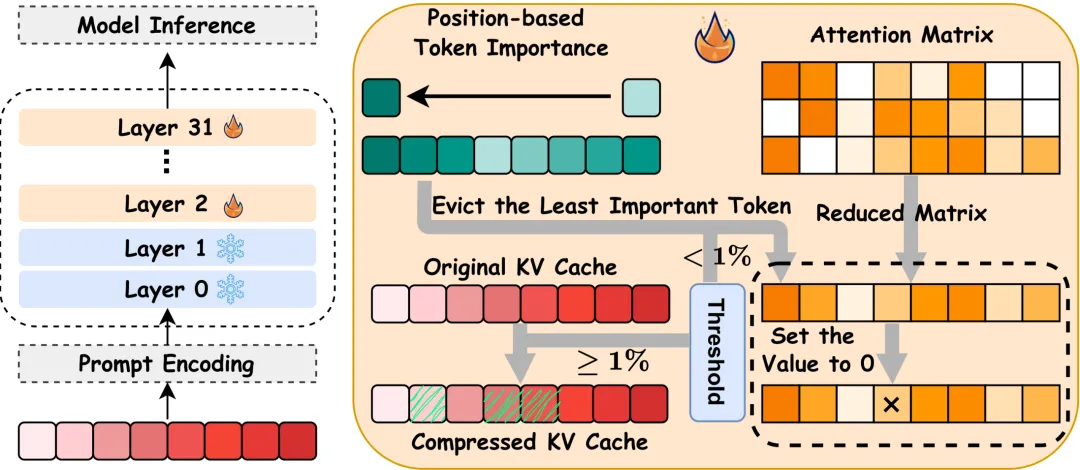
Towards Threshold-Free KV Cache Pruning
作者:倪宣凡,徐立岩,吕晨阳,王龙跃,于墨,刘乐茂,孟凡东,周杰,李丕绩*
类型:Findings
摘要:大语言模型(LLMs)的长上下文推理能力取得显著突破,但键值(KV)缓存的显存占用随序列长度线性增长,成为制约模型高效部署的核心瓶颈。现有 KV 缓存剪枝方法高度依赖人工预设的领域专属阈值,在开放域、混合长度输入场景下性能波动剧烈,泛化性与实用性严重受限。为解决这一问题,我们提出ReFreeKV,一种全新的无阈值 KV 缓存优化框架,将重要性评估、动态驱逐与缓存预算分配统一至端到端的自适应流程。ReFreeKV 摒弃手动调参,通过位置感知初始排序、基于 Frobenius 范数的通用评估指标(Uni-Metric)与固定全局阈值(T=1%),实现跨任务、跨模型的稳定剪枝。同时,设计低开销并行算子与分层保留策略,确保推理效率与性能平衡。实验结果表明,在 Llama3、Mistral、Qwen2.5 等主流模型及 13 个数据集上,ReFreeKV 平均仅需63.7%缓存即可维持全缓存性能,显著优于 H2O、StreamingLLM、SnapKV 等基线方法。
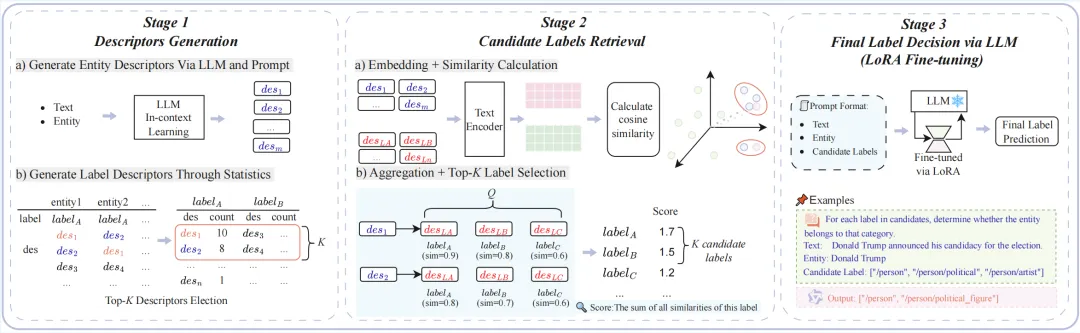
Leveraging Label Semantics and Entity Description Generation for LLM-based Fine-grained Entity Typing
作者:马莹莹,戴洪良*,张霞,李丕绩
类型:Findings
作者单位:南京航空航天大学
摘要:近期,大语言模型(LLMs)在细粒度实体分类任务中展现了强大潜力,但直接应用仍面临两大瓶颈:面对数十上百个类型标签时,LLMs的决策准确性会大幅下降;同时,可用于训练的远程监督数据噪声严重,干扰模型学习。
针对“标签太多、数据太吵”的难题,我们提出了一个创新性的解决方案:DR-FET。该方法的核心思想是引入自然语言描述符作为实体与类型标签之间的“语义桥梁”,将推理过程分解为三步:1)为实体和所有类型生成描述性短语;2)利用语义检索快速找出最相关的一小部分(如Top-10)候选类型,大幅缩减标签空间;3)在候选集约束下,由LLM完成精准的类型选择。
更为巧妙的是,同样的“描述-检索”机制被复用于训练阶段,从海量噪声数据中自动筛选出语义一致、高置信度的样本,从而构建出高质量训练集,极大提升了LLM微调的效果。实验表明,该方法在两个标准数据集(OntoNotes和BBN)上超越了现有所有基线,显著提高了分类精度。这项工作为解决大标签空间下的复杂分类任务,以及利用大模型从噪声数据中“去伪存真”,提供了一个新颖且有效的范式。
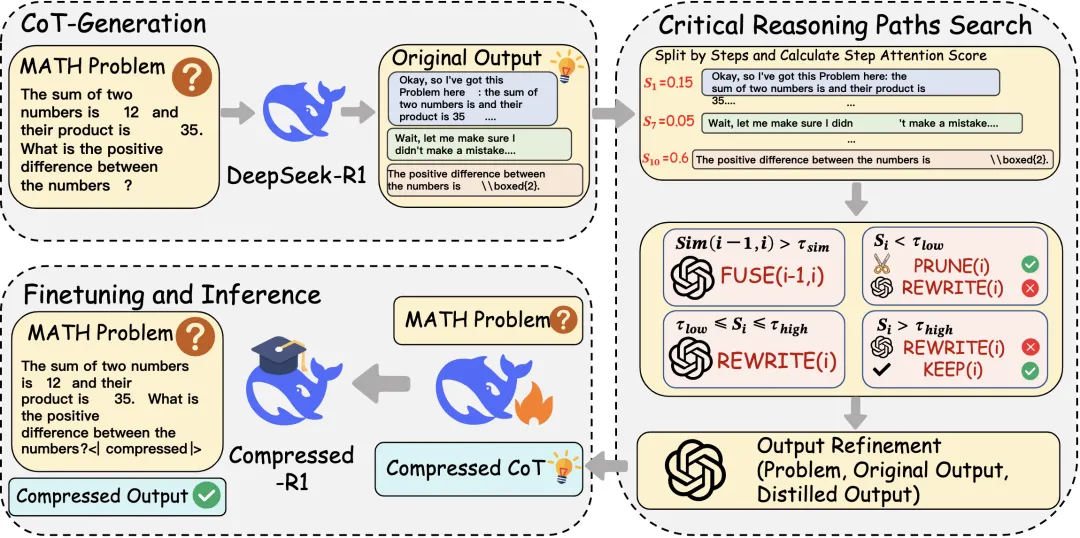
CRISP: Compressing Redundancy in Chain-of-Thought via Intrinsic Saliency Pruning
作者:蓝杨松,戴洪良,李丕绩*
类型:Findings
作者单位:南京航空航天大学
摘要:最近,推理型大语言模型在数学与复杂决策任务上展现出了强大的能力,但其依赖长链式思维的推理方式也带来了显著的计算开销与推理延迟,成为实际部署中的关键瓶颈。现有CoT压缩方法大多依赖外部压缩器或启发式裁剪策略,往往难以对齐模型自身的内部推理动态,易删除关键中间步骤,破坏推理链的逻辑连贯性。为了解决这一问题,我们提出了 CRISP(Compressing Redundancy in Chain-of-Thought via Intrinsic Saliency Pruning),一种基于模型内在显著性信号的链式思维压缩框架。CRISP 的核心发现是:推理终止标记 </think> 在生成最终答案时充当了一个“信息锚点”,其注意力模式能够有效区分推理过程中真正关键的步骤与冗余内容。基于这一发现,CRISP设计了KEEP、PRUNE、REWRITE、FUSE四种原子操作,在兼顾答案保真度与序列长度的奖励机制引导下,对原始推理链进行搜索式压缩;同时,结合生成式精修模块进一步恢复压缩后推理链的语义连贯性与逻辑完整性。实验结果表明,CRISP在不同规模的推理模型和多个数学基准上均取得了优异的效率—性能平衡,能够在基本不损失推理准确率的同时,将推理 token 数量降低约 50%–60%,显著缓解了长推理带来的效率瓶颈,为高效推理模型的训练与部署提供了新的思路。