南京农业大学| Adv sci: 基于预测性微生物功能谱的根腐病预测
题目:Forecasting Root Rot Disease through Predictive Microbial Functional Profiling
基于预测性微生物功能谱的根腐病预测
期刊:Advanced Science
IF 14.1√
https://doi.org/10.1002/advs.202522628
对根腐病等土传病害进行早期诊断是农业领域长期面临的一项挑战。尽管微生物功能基因被认为是土壤健康状态的有效指示因子,但其应用主要局限于当前或过去的土壤状况。本研究表明,微生物功能基因可以从描述性指标转变为可靠的预测性生物标志物。通过分析来自健康和患根腐病的药用植物根际土壤样本的199对宏基因组数据,我们鉴定出一组在进化上保守的核心功能基因,特别是那些控制生物膜形成、胁迫响应以及植物-微生物互作的基因,它们与根腐病密切相关。为弥合研究发现与田间应用之间的差距,我们开发了一个框架,该框架整合了针对这些关键基因的低成本qPCR检测方法,并将其丰度数据与机器学习模型相融合。该模型在独立的前期无症状土壤样本中预测病害发生的准确率超过80%,能够在植物出现明显感病症状之前很久就识别出风险。我们的研究结果表明,可以沿着一条切实可行的路径,从简单的微生物关联分析迈向主动预测工具。通过将微生物功能基因置于病害管理的核心位置,该框架为减轻土传风险、支持可持续农业实践提供了一种具针对性的策略。
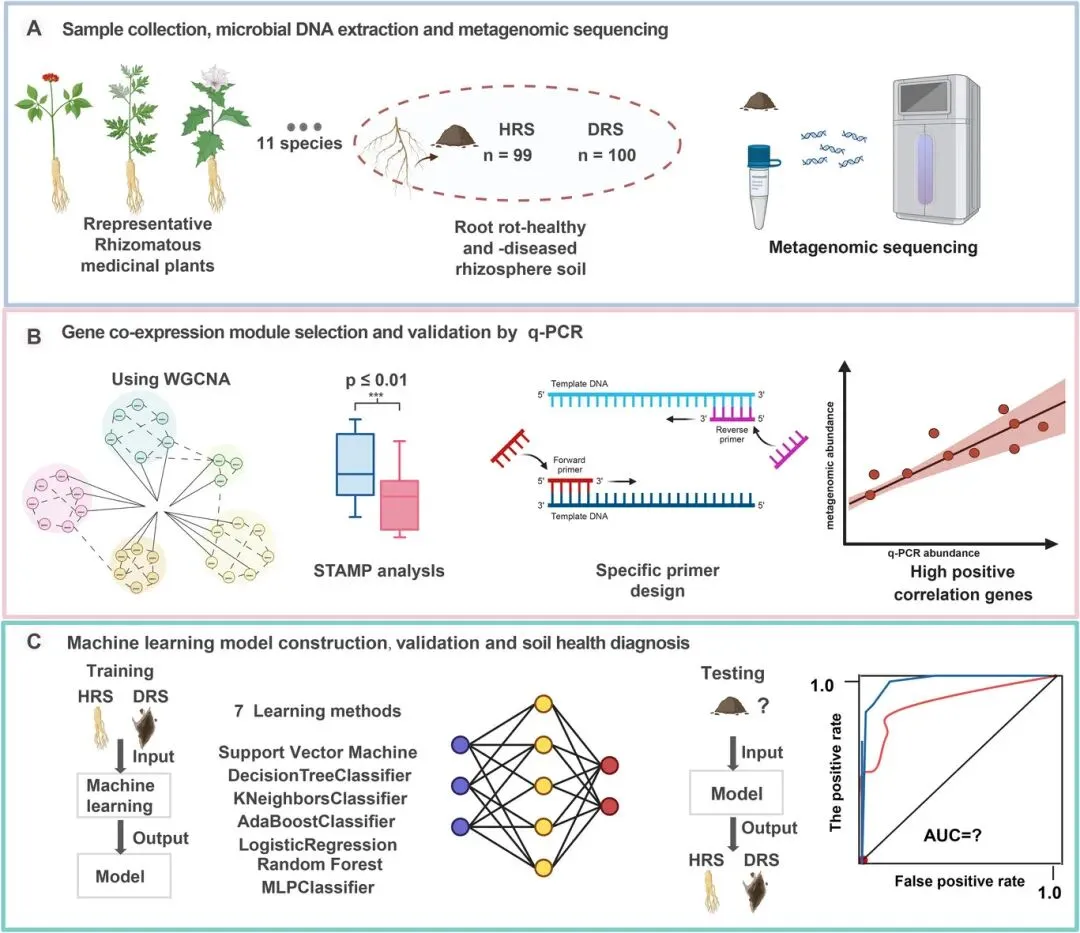
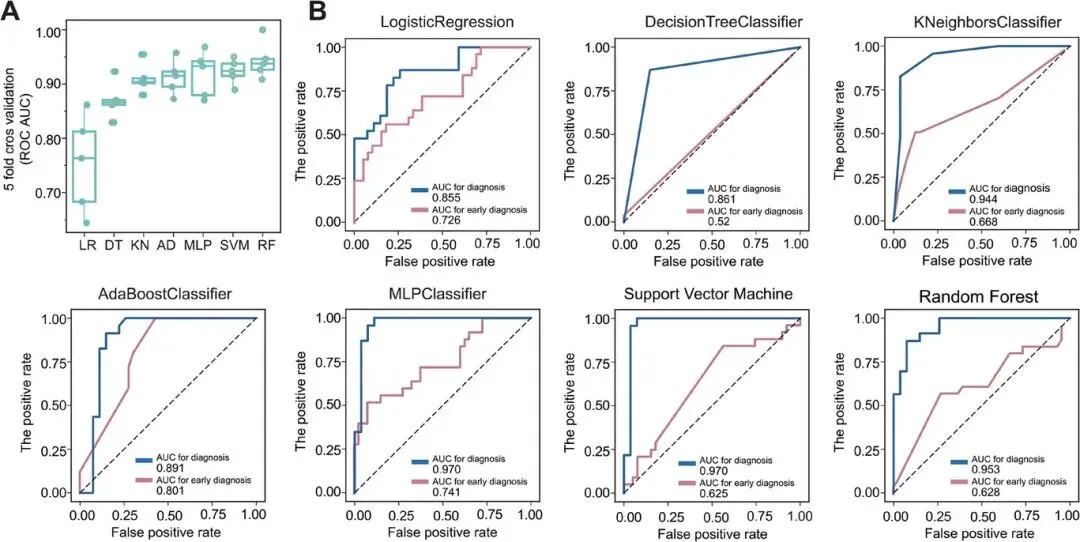
图1.本研究的工作流程。(A)样本采集与宏基因组分析:从配对的健康与患病植株根际土壤中采集样本(n = 199 对)。通过鸟枪法宏基因组测序分析微生物功能潜力。(B)关键功能基因的鉴定:采用加权基因共表达网络分析(WGCNA)构建 KEGG 同源(KO)基因的共表达模块。进一步应用显著时序表达分析(STEMP)识别与病害状态相关的关键差异丰度 KO 基因。引物设计与验证:针对筛选出的 KO 基因设计特异性 qPCR 引物,并通过实验验证各引物对的特异性和靶向效率。(C)基于机器学习的预测与验证:利用 qPCR 获得的关键 KO 基因丰度数据,训练七种机器学习模型(支持向量机、决策树分类器、K近邻分类器、AdaBoost 分类器、逻辑回归、随机森林和多层感知机分类器)。使用独立的验证集和一组额外的发病前土壤样本对表现最优的模型进行独立验证,以评估其在预测病害早期发生方面的准确性。
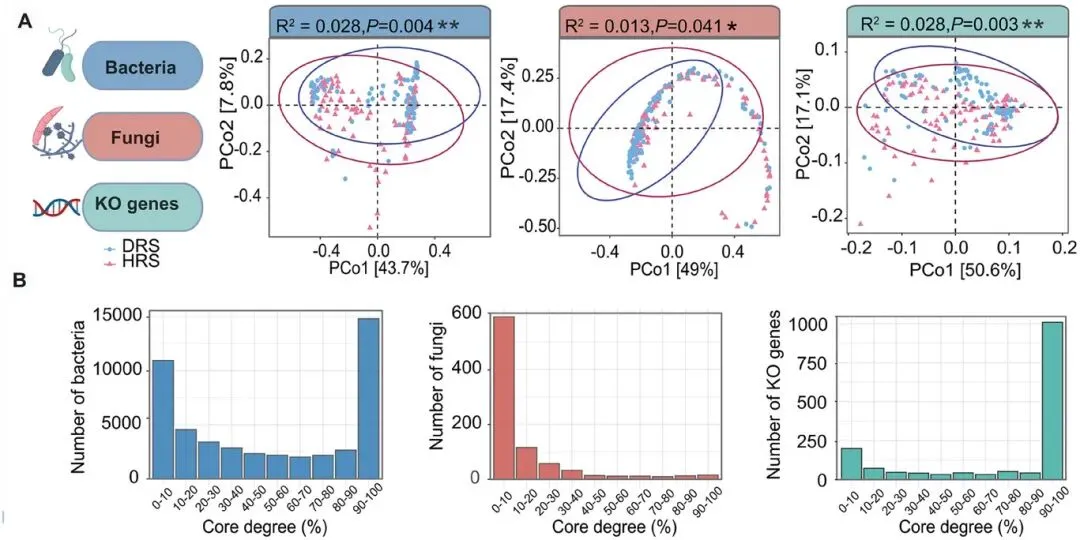
图2.微生物群落与功能基因谱区分健康(n = 100)与患病(n = 99)根际样本。(A)基于Bray-Curtis距离的主坐标分析(PCoA)显示,在细菌、真菌及KO基因谱中,健康与患病样本之间存在显著分离。图中标明了各主成分的解释方差百分比(R²)及ANOVA分析的p值。(B)条形图展示了细菌物种、真菌物种及KO基因的核心度(coreness),这些核心度分布在十个核心度区间内,核心度定义为各特征在所有样本中出现的频率。
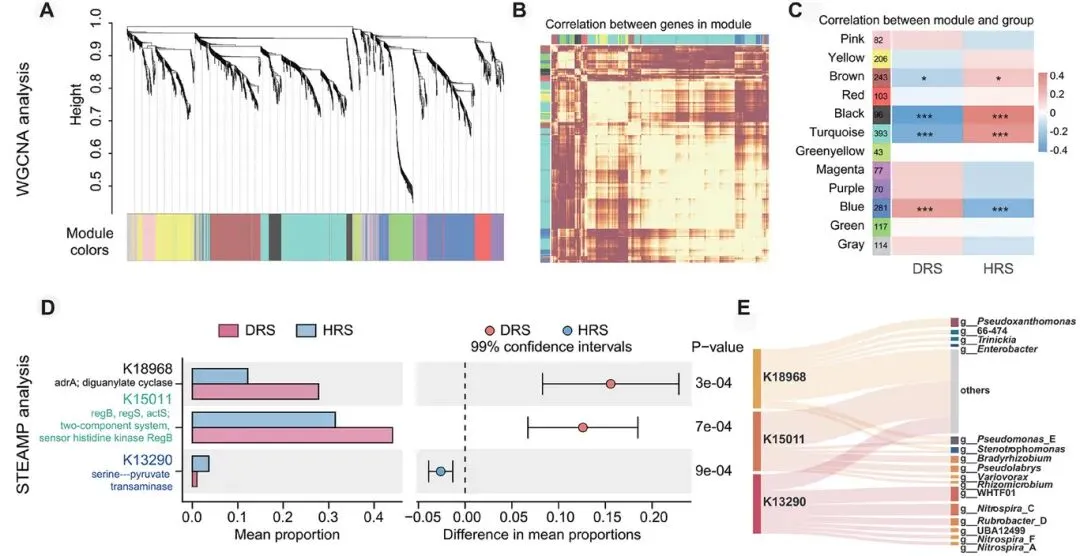
图3.利用加权基因共表达网络分析(WGCNA)及进一步的显著时序表达分析(STEMP)鉴定与根际健康状态相关的功能基因模块和关键生物标志物。(A)基于欧氏距离的KO基因聚类树状图。上半部分显示基因的层次聚类结果;下方的彩色条带表示模块分配,不同颜色对应不同共表达模块,灰色表示未分配到任何模块的基因。(B)模块特征基因邻接热图,描绘模块内共表达强度。红色越深表示拓扑重叠程度越高,模块内基因间的共表达关系越强。(C)基因模块与植物健康状态之间的模块-性状相关性。红色表示正相关,蓝色表示负相关。数值表示相关系数,括号内为相应的p值。(D)对来自三个病害相关模块的770个KO基因进行STEMP分析。左侧条形图展示了健康组(n = 100)与患病组(n = 99)中三个显著差异表达的KO基因的相对丰度;右侧图显示了它们的差异丰度的95%置信区间(经Bonferroni校正后,所有p < 0.001)。(E)通过元链接方法追溯KO基因(K13290、K18968和K15011)所属的属分类水平。
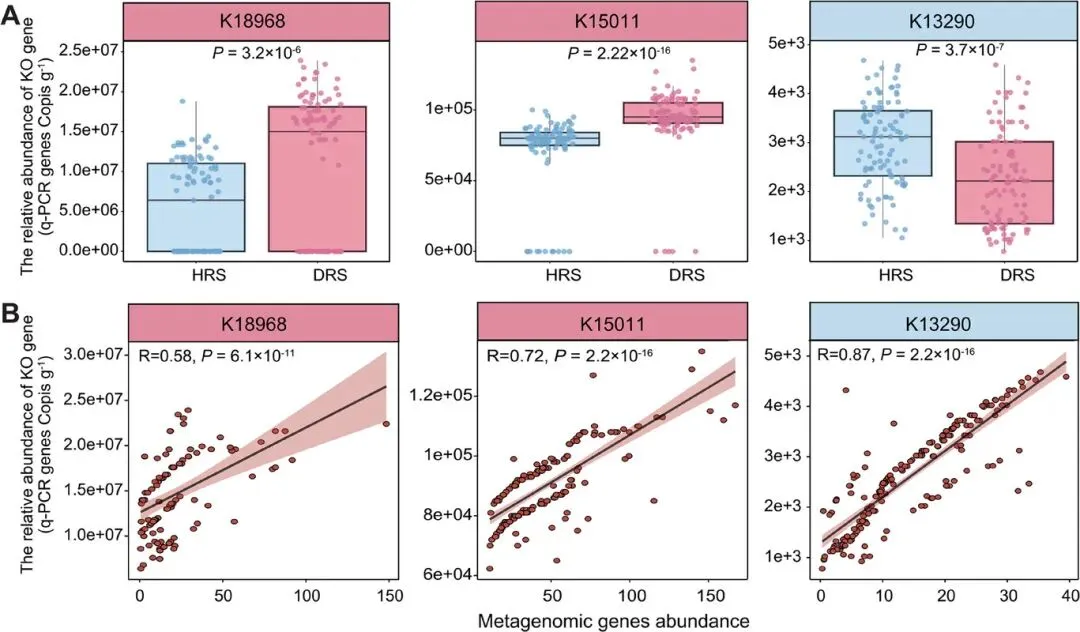
图4.通过qPCR验证关键微生物基因生物标志物及其与宏基因组谱的相关性。(A)箱线图展示通过qPCR测定的三个KO基因(K18968、K15011、K13290)在健康根际土壤(HRS,n = 100)和患病根际土壤(DRS,n = 99)样本中的相对丰度。统计显著性由Wilcoxon秩和检验确定。(B)宏基因组测序与qPCR获得的基因丰度值之间的Spearman相关性分析(n = 199)。
图5.用于预测根腐病的机器学习模型性能评估。(A)在保留测试集上的模型比较。基于qPCR数据(n = 199个样本,按7:3划分)训练的七种机器学习模型的受试者工作特征(ROC)曲线。(B)在独立验证集上的ROC对比分析。展示表现最优模型应用于两个独立验证集时的ROC曲线:疾病诊断验证的保留测试集(n = 60,实线)和早期预测评估的发病前土壤集(n = 64,虚线)。
论文DOI
10.1002/advs.202522628
声明:本文仅供科研分享,不做盈利使用,如有侵权,请联系后台处理。
本文含有部分AI翻译,文中难免有所疏漏和错误,恳请批评指正。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
