南京大学王利民团队 | 光流稳住运动,扩散模型守住细节:MoG运动感知插帧方法
- 2026-05-31 12:25:17
南京大学王利民团队 | 光流稳住运动,扩散模型守住细节:MoG运动感知插帧方法

张国珍、朱宇涵:南京大学软件新技术国家重点实验室 崔玉涛、赵晓彤、马凯:腾讯 PCG 王利民:南京大学、上海人工智能实验室 
手机拍体育、舞台或孩子跑动,原始素材往往只有30帧;想做流畅一点的回放,或者把普通片源提升帧率到更高刷新率,背后都要靠插帧--在相邻两幅画面之间再算出若干中间帧。老电影修复、监控补帧、剪辑里做慢动作,其实也是同一类问题:时间轴上「缺了几格」,算法得猜出来,还不能让人一眼看出假。 做插帧,行业里长期有两条路。一条路是光流:先估计像素怎么动,再按运动场去「搬运」图像。优点是轨迹清楚时,整体很顺;缺点是人物交错、头发飘、衣服褶子一大,光流就容易估不准,画面里便出现糊块、重影、拉丝。另一条路是这两年很热的大视频生成模型:用扩散模型从噪声里画」出中间帧,复杂纹理有时更耐看;可它未必严格照着首尾两帧走,常见的是运动发飘、物体对不齐--毕竟预训练阶段并没有专门把「两帧之间的对应关系」教到很细。 两条路各有利弊,实际业务里却常常希望又顺又真:运动别乱跳,边缘别糊成一片,同时别跟输入的首尾帧「打架」。这项工作想解决的就是这个折中难题:在真实拍摄和动画素材两类场景里,把光流提供的运动线索和扩散模型的生成能力接到一起,让插帧结果更稳、更干净,也方便后续做提升帧率、慢放等应用。 

论文里把方法叫作 MoG (Motion-aware Generative frame interpolation),可以直译成 「运动感知的生成式插帧」。实现上并没有从零搭一个新网络,而是站在现成的视频扩散插帧模型肩膀上:真实场景用DynamiCrafter,动画场景用ToonCrafter。团队额外接了一条光流插帧支路,专门估计「从首帧到中间帧、从尾帧到中间帧」的中间光流,相当于给扩散模型递一张运动草图;草图哪里画得准,生成就跟着走;哪里画歪了,就靠扩散那半边自己收一收。 具体怎么接进去,文中有张总览图(Fig.2)。大意是:光流对齐后的信息不只塞在一个地方,而是同时在潜空间和网络中间特征两层往里送,让模型从「底图」到「细节」都能感到运动约束。设计上刻意把引导主要放在编码器一侧,解码器那边少绑手脚,这样光流带偏了的时候,后半段还有机会把纹理拉回来。训练时也没有大动干戈:主要微调空间卷积一类层,时间相关的模块尽量冻住,免得把大模型原来学会的时序本领冲掉。和再挂一个笨重的ControlNet式分支相比,这种改法更轻,也更利于保住预训练权重里的生成质感。 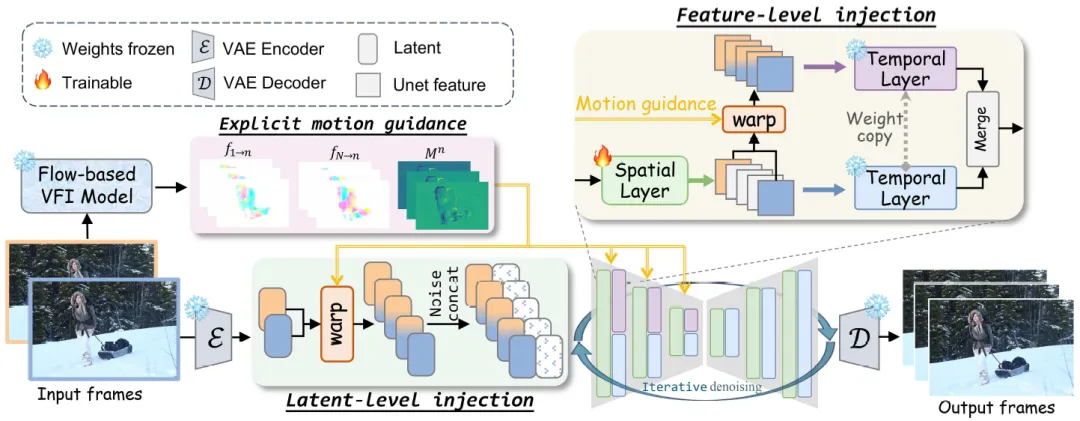
若用审稿人爱看的三点来概括,可以是: (一)潜变量+特征双层注入,光流信息走得进、散得开; (二)编码器注入配合选择性微调,纠错有空间、老本行尽量不丢; (三)在常用LDM结构里就能落地,工程上相对好跟现有管线对接。 

实验分几块。训练数据是团队按与基线可比的方式自建的,分辨率512x320,每条样本16帧,采样间隔等细节与DynamiCrafter/ToonCrafter 原文设置对齐,避免「换了数据偷偷占便宜」的质疑。评测除了自建的VFIBench(含实拍与动画各一百段量级),也在公开的Davis-7上跑了一轮,和光流类、生成类若干代表方法并排比。 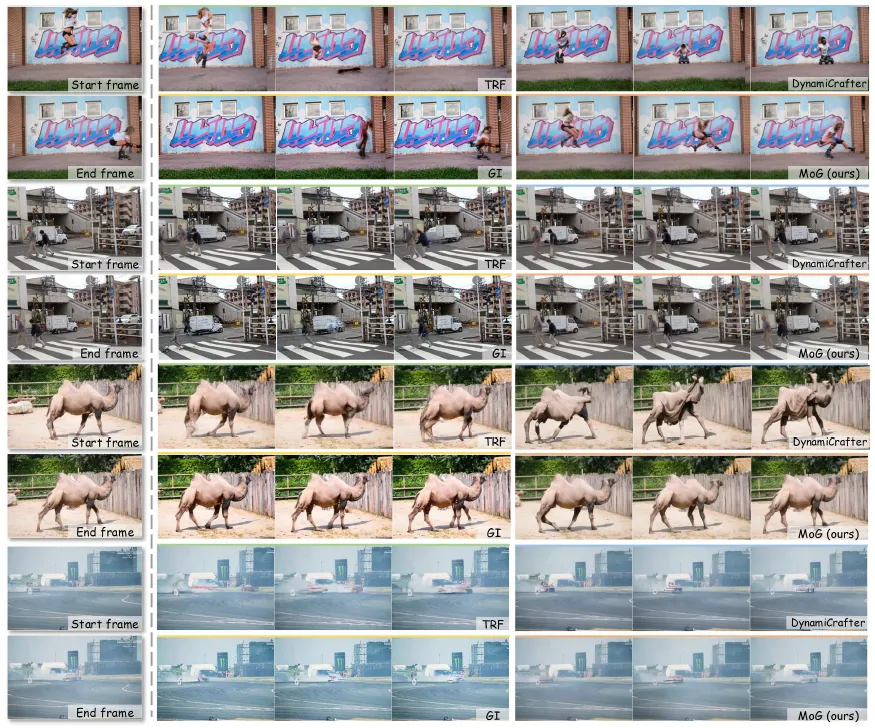
肉眼看图(Fig.1、Fig.4),MoG的中间帧在运动连贯性和纹理忠实度上往往更耐看:少那种整块涂抹的感觉,也少突然「换脸式」的跳变。数字指标上,PSNR、SSIM、LPIPS、FID,FVD 以及VBench里抽出来的一组子项都做了汇报;生成式方法那一栏里,MoG整体是往上走的。另有一组实验把「首尾之间要插帧的步数」拉长缩短--相当于模拟不同提升帧率倍数下任务难度变化--曲线在Fig.5,可以看到难度上去之后,优势并没有立刻塌掉。 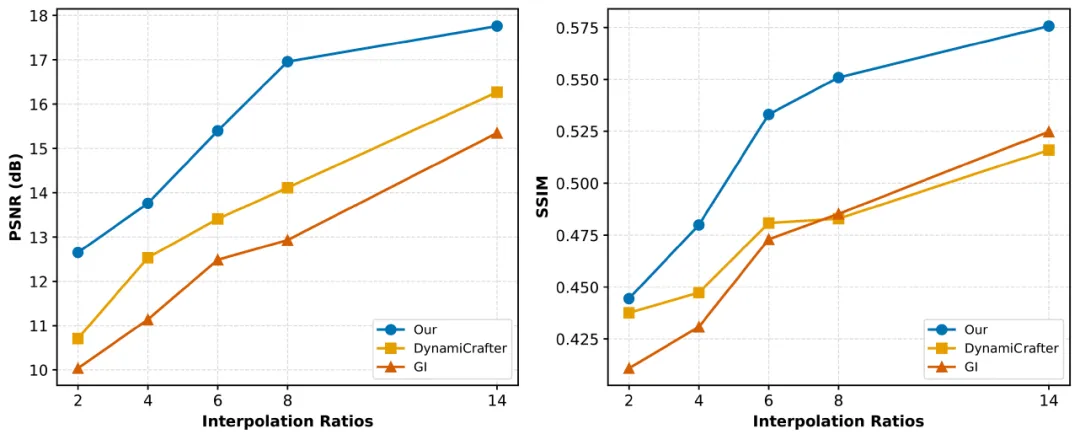
此外做了小规模用户主观打分: 请参与者从运动是否自然、时间是否连贯、是否像原图、总体观感等维度挑选更喜欢的结果,MoG的得票明显集中。推理耗时也和当下主流生成式插帧方案在同量级,没有为了画质把延迟抬到不可用。 代码和更多视频对比见 https://mcg-nju.g1thub.1o/MoG_Web/ 
相关阅读 SCIS专题 | 多模态大模型 (2025) 上海交通大学邓志杰团队 | 基于控制网无需训练的文本驱动长视频编辑 上海人工智能实验室乔宇团队 | VideoChat: 基于视频指令数据微调的聊天机器人 中国科学院计算所山世光团队 | 用于视觉标记化的一致多模态预训练 华中科技大学桑农团队 | UniAnimate: 可控视频生成新SOTA,给定参考人物图像即可定制高质量跳舞视频 


研究团队
#插帧,#提升帧率,#视频增强,#光流,#扩散模型,#视频生成,#计算机视觉,#人工智能
引用本文: Zhang G Z, Zhu Y H, Cui Y T, et al. Motion-aware generative frame interpolation. Sci China Inf Sci, 2026, 69(5): 150101, https://doi.org/10.1007/s11432-025-4920-3

研究意义
图1 同一段素材里,不同方法插帧后的观感差别一眼能看出来:有的中间帧边缘发虚,有的动作「拖尾」。 MoG 这边,运动相对利落,人物和背景的轮廓也更贴原片。(论文 Fig.1,节选)
本文工作
图2 方法管线一览:先由光流分支给出中间运动场,再把对齐后的表征送进扩散模型;注入点分两层,且偏编码器侧,给后面解码留余地(论文 Fig.2)
图3 复杂运动区域往往最考验插帧:单靠光流容易糊,单靠生成基线又可能跟输入帧对不齐。MoG 把两边的长处叠在一起,对比如图所示。(论文 Fig. 3)
实验结果
图4 实拍场景下与多种生成式插帧方法的并排对比;放大看衣褶、发丝、运动物体边缘,差别会更明显。(论文 Fig.4)
图5 插值步数变化(可理解为提升帧率任务里「中间要补多少格」)对难度的影响:步数越多越难,MoG 的PSNR/SSIM 等仍相对稳定。(论文 Fig.5)

本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 南京玄武丨省50万买116平东南向三室 双地铁
- 全国第一学科 + 14 所附属医院!南京医科大学升学就业全曝光,建议收藏!
- “南京审计大学金审学院”PPT模板来了!
- 南京市江宁区佳湖东路幼儿园2026年秋季招生公告
- 南京外国语学校2026年初中招生简章
- 南京师范大学附属中学雨花台学校2026年初一新生入学公告
- 关于南京市紫金新消费与现代服务产业股权投资合伙企业(有限合伙)托管银行遴选结果的公示
- 【2026年招生|小班】南京市江宁区机关幼儿园2026年小班秋季招生公告
- 【南京】南京市国土资源信息中心2026年公开招聘工作人员公告(6月2日截止)
- 谢素原院士领衔!南京大学宋凤麒/张敏昊团队:原子制造 | Nature Materials
