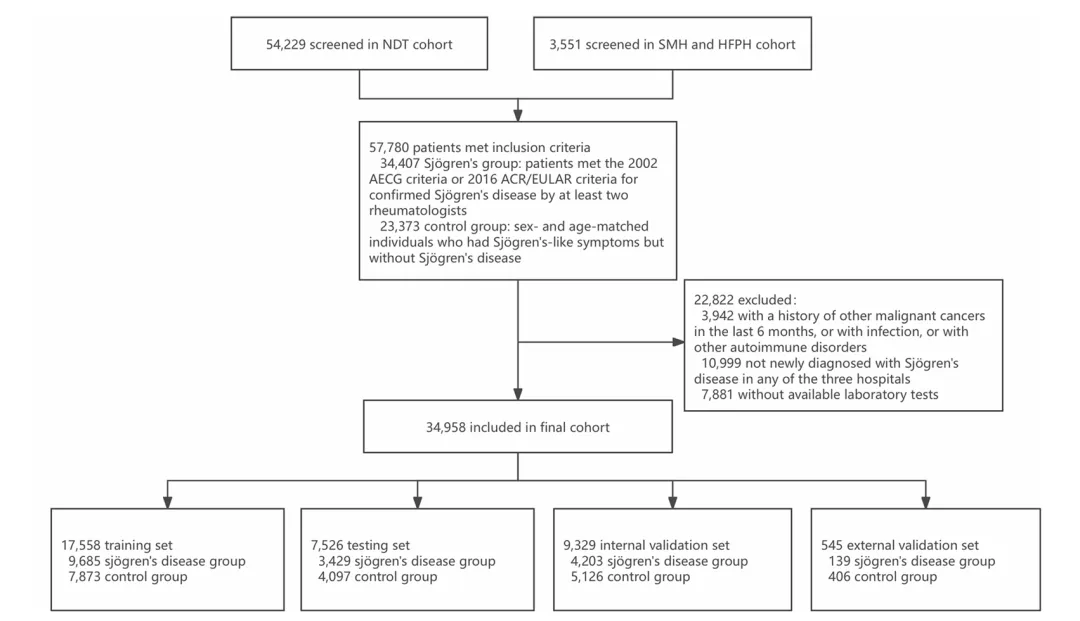
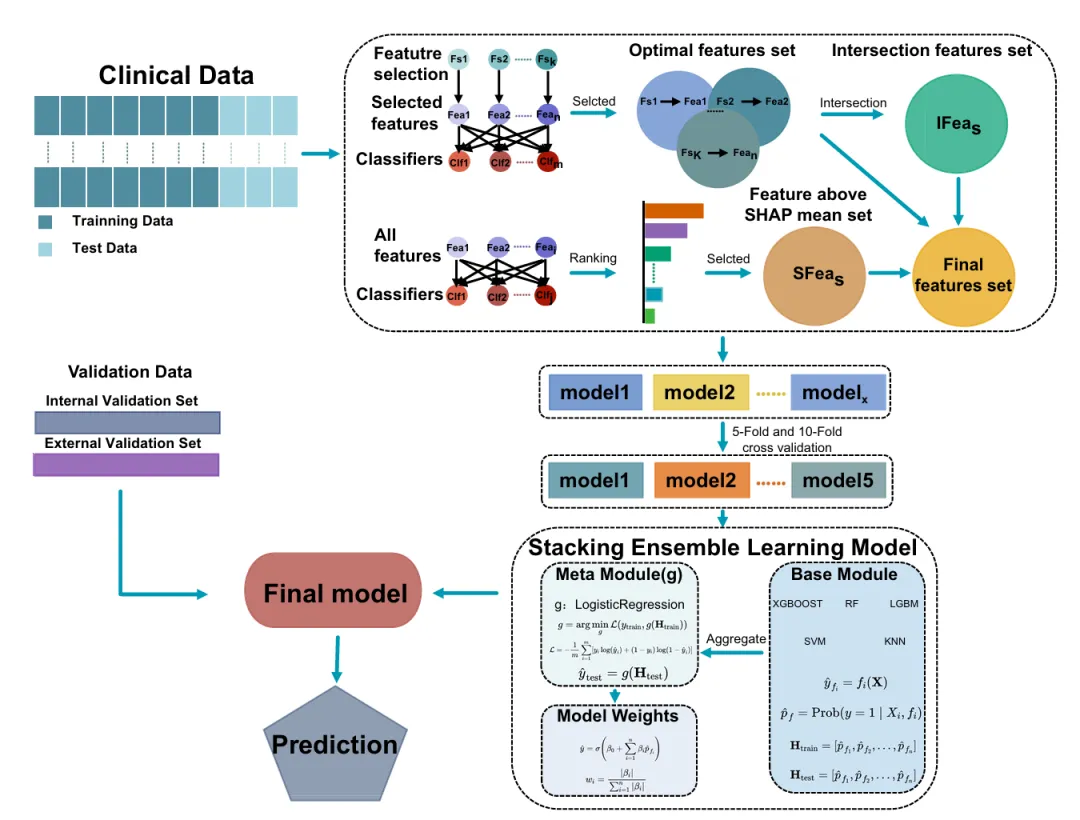
从123项常规血检中筛选出70个有效特征,经6种算法交集+7个基模型SHAP排序,最终确定16个核心特征,通过堆叠集成5个最优模型构建SMFIF(图2)。
特征选择至少用3种不同算法取交集;基模型需包含线性、树型、距离型等不同类型;元分类器优先使用逻辑回归。
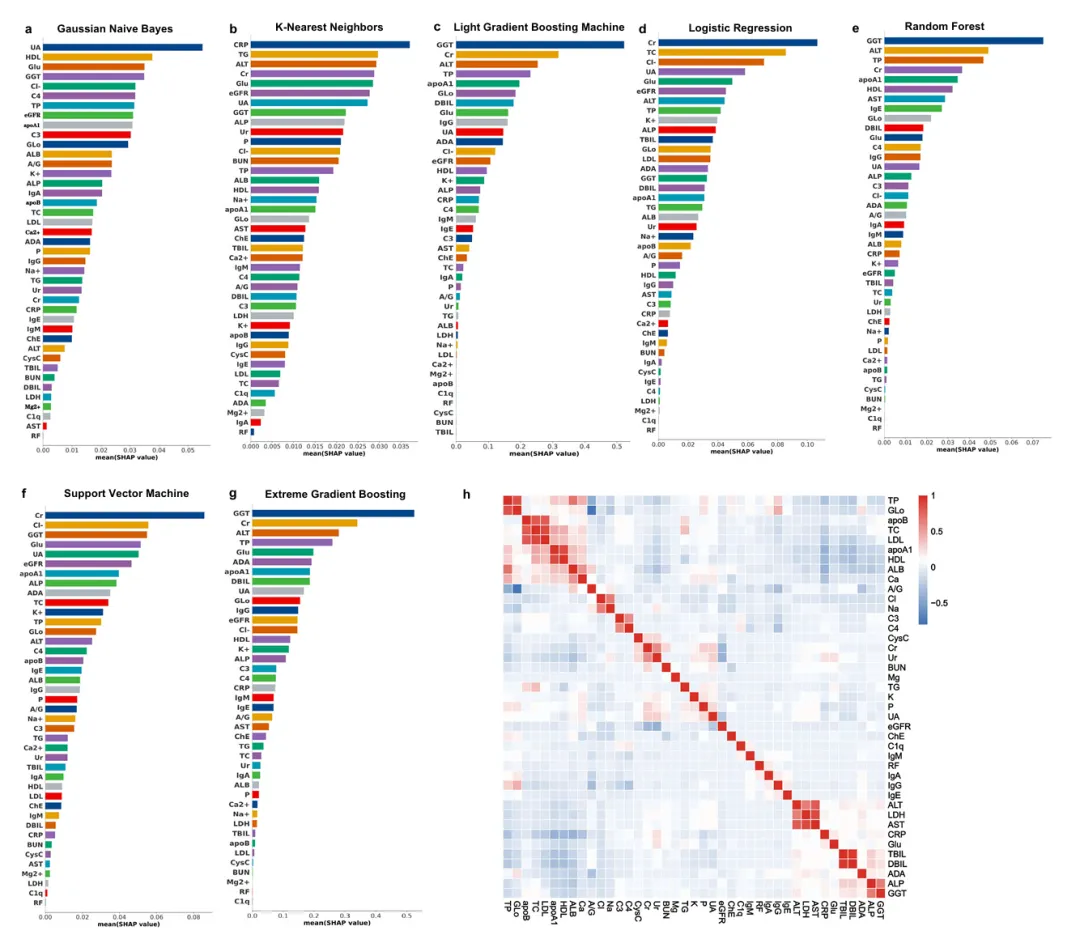
16个核心特征多为肌酐、尿酸、谷丙转氨酶等肝肾代谢指标。7个基模型的特征重要性排序总体趋势一致。个别特征存在中等程度共线性,因临床意义予以保留(图3)。
图3.基于SHAP值的特征重要性分析及特征间相关性热图
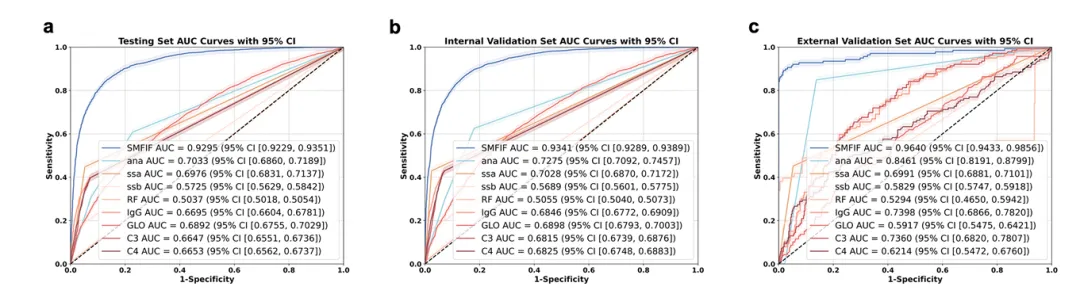
SMFIF模型性能显著优于8种临床常用传统标志物,其中抗SSA抗体AUC仅0.705、ANA为0.709、RF仅0.506(图4)。
图4.SMFIF模型与传统生物标志物诊断性能(AUC)比较
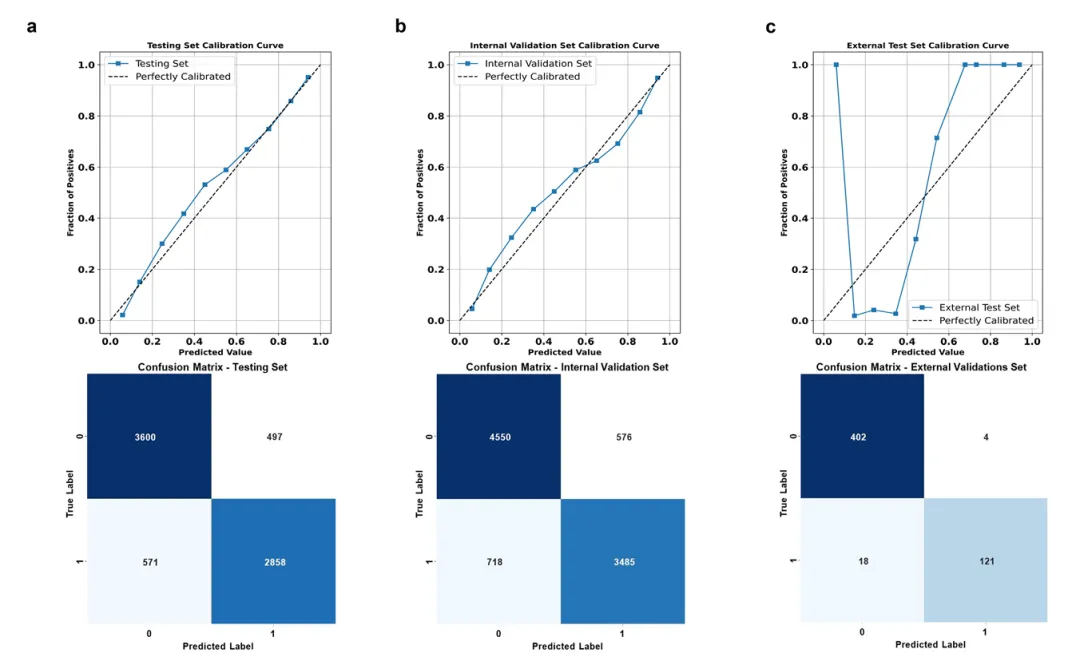
模型预测概率与实际发病概率高度一致。外部验证集仅4例假阳性、18例假阴性,误诊漏诊风险极低(图5)。
校准曲线必须添加y=x完美校准线作为参考;混淆矩阵标注具体人数而非比例;校准度差可用Platt缩放修正。
图5.SMFIF模型在各数据集中的校准曲线与混淆矩阵