大模型后训练通常有两种明显不同的路线。监督微调拿着固定答案逐 token 教模型,信号密集,却容易遇到训练数据与模型真实输出不一致的问题;RLVR 让模型在自己的回答上学习,更贴近测试时的行为,但最后往往只有一个结果奖励,很难判断中间哪一步出了问题。
On-Policy Distillation(OPD)把两者接在了一起:学生模型先生成自己的答案,教师再对这条学生轨迹逐 token 给出分布监督。直觉上,这种密集反馈应该广泛改写模型参数。作者比较多组语言模型和视觉语言模型的训练前后权重后,却看到相反结果:OPD 的监督覆盖整条序列,最终变化却集中在一个很小、具有固定几何结构的子网络中。
Motivation
OPD 的特殊之处,不在于用了教师模型,而在于教师监督落在谁生成的轨迹上。
离线蒸馏直接学习教师给出的完整答案。学生可能从来不会生成这样的过程,却要强行拟合教师轨迹,参数需要在较大的空间内重新调整。RLVR 使用学生当前策略生成的答案,数据分布是 on-policy 的,但奖励往往只告诉模型最终答对还是答错。
OPD 仍然沿着学生自己的生成路径前进,只是把稀疏结果奖励换成了教师逐 token 提供的概率分布。它在训练目标上介于蒸馏与强化学习之间,由此留下一个没有被回答的问题:决定参数更新形态的,究竟是监督信号是否密集,还是训练数据是否来自模型自己?
作者没有继续比较几个 benchmark 分数,而是直接查看训练前后的权重差值,分析更新发生在哪些坐标、哪些模块、哪些奇异方向,以及这些变化能否独立支撑能力提升。
现象剖析:密监督,稀更新
结果显示,OPD 对模型的整体改动很小。
六组 OPD 模型的相对权重变化仅为 0.036%–0.142%。在 (10^{-5}) 的可见更新阈值下,66.72%–89.50% 的参数坐标几乎没有发生可观察变化。作为对照,传统离线蒸馏的相对更新达到 11.936%,未变化坐标只有 3.06%。
这里的“稀疏”指最终 checkpoint 中可见的参数差值,并不等于训练过程中的梯度本身始终稀疏。大量参数可能接收过梯度,只是最终没有留下超过阈值的净变化。
这些更新也不是只出现在某几层。它们分散在整个 Transformer 深度中,只是每一层内部真正变化的坐标不多。能量通常更多落在 FFN:多组模型中,FFN 承担了约 65%–86% 的更新能量;部分 Qwen3 实验里,Attention 的占比也会明显上升。OPD 因而不是简单修改某一层,也不能概括成只更新 FFN,而是在全网中写入一条稀疏、模块偏置明显的参数路径。
核心解读:更新写向哪里
只知道“改得少”还不够,论文继续分析这些参数变化在权重空间里的形状。
从矩阵秩来看,OPD 更新并不是严格低秩。多数更新矩阵在数值上仍是满秩的,说明很多奇异方向都存在微小变化;但能量又高度集中在前面少数奇异值上。可以把它理解成:许多方向都被轻轻碰了一下,真正承担主要变化的只有少数方向。
这个区别直接影响 LoRA 类方法的判断。低秩适配可以覆盖 OPD 更新中的主要能量,却不一定精确还原完整 checkpoint 差值。把 OPD 简单称为“低秩更新”并不准确,更合适的描述是:数值满秩,但有效能量集中。
更新方向同样有明显偏好。OPD 很少沿着原模型权重中能量最大的主奇异方向移动。占据源权重前 10% 的主坐标,只覆盖约 4.39%–5.46% 的可见 OPD 更新,低于随机情况下应有的 10%;源权重绝对值最低的 10% 坐标,却覆盖了 24.99%–48.57% 的更新。
也就是说,OPD 更倾向于在原模型较弱、较空的区域写入新能力,而不是直接改写已经承载主要能力的方向。论文没有直接证明这种结构一定减少遗忘,但它解释了为何 OPD 能以很小的参数位移改变推理行为。
背后的原因可能来自 on-policy 数据。学生学习的是自己已经会生成的前缀,教师只需在熟悉的行为区域内逐步校正;离线蒸馏则要求学生追随外部轨迹,往往需要更广泛地重写参数。监督有多密,并没有消除 on-policy 训练留下的稀疏几何特征。
图表深度解读
图1:OPD 更新的四个特征
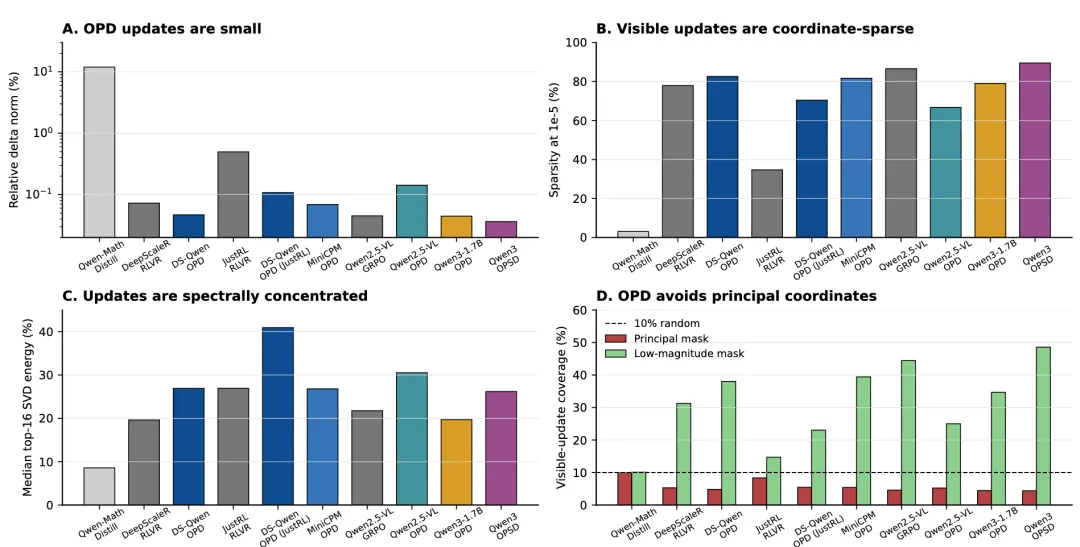
画面描述:四组柱状图分别比较参数变化规模、坐标稀疏度、奇异值能量集中程度,以及更新在源权重主坐标和低幅值坐标中的分布。
深度解读:四张图合在一起,才能完整描述 OPD。它不是单纯“更新量小”,而是同时具备小范数、高坐标稀疏、频谱集中和偏离源模型主方向四个特点。离线蒸馏在这些指标上明显不同,RLVR 反而与 OPD 更接近,说明 on-policy 数据分布对参数结构的影响可能大于监督信号的密度。
表4:OPD 与 RLVR 是否修改同一批参数

画面描述:表中比较 OPD、RLVR 以及不同教师训练出的 OPD 模型之间,可见参数更新掩码的覆盖程度。
深度解读:这些掩码的重合并非由稀疏比例偶然造成。DS-Qwen 中,RLVR 与 OPD 的相互覆盖达到随机基线的 3.04 倍;Qwen2.5-VL 中也达到 2.21 倍。更换教师以后,两次 OPD 仍会重复触碰大量相同坐标。这暗示模型内部可能存在一组更容易被后训练调用的能力子网络,教师和目标不同会改变具体更新,却不会完全改变模型允许能力写入的位置。
图3:稀疏结构是否真的有用
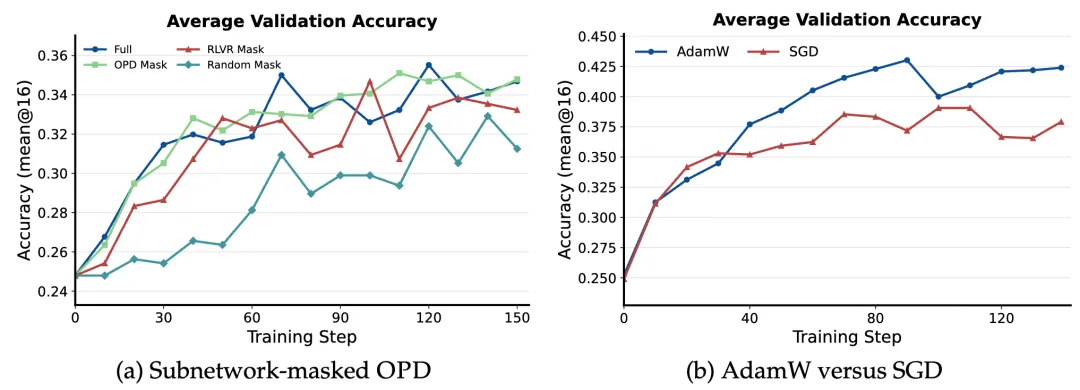
画面描述:左图比较完整 OPD、OPD 参数掩码、RLVR 掩码和随机掩码训练;右图比较 AdamW 与 SGD。
深度解读:只训练完整 OPD 识别出的约 17.5% 坐标,峰值准确率达到 35.10%,几乎追平完整训练的 35.52%;同密度随机掩码只有 32.92%。这证明稀疏结构不只是训练后的统计现象,坐标位置本身具有功能意义。右图同时给出限制:参数结果稀疏,不代表优化过程可以直接使用更简单的 SGD。
实验结果说明了什么?
参数分析覆盖十组训练前后模型,包括六组 OPD、三组 RLVR 参考和一组传统蒸馏对照,涉及语言模型、视觉语言模型、大模型向小模型蒸馏、能力合并和带特权信息的自蒸馏。
最关键的验证不是“OPD 参数很稀疏”,而是只开放这些参数重新训练时,能力确实可以恢复。RLVR 掩码也能取得 34.69% 的峰值,进一步支持二者共享部分后训练子网络;它仍低于 OPD 掩码,说明两种训练方式触碰的区域有交集,但并不相同。
优化器实验又避免了一个过度推论。RLVR 研究曾发现 SGD 可以接近甚至优于 AdamW,并产生更稀疏的更新。OPD 中,AdamW 的最终准确率为 42.40%,SGD 只有 37.92%。教师逐 token 提供的密集分布保留了明显的坐标梯度尺度差异,AdamW 的自适应缩放仍然有用。
论文当前的证据主要来自最终 checkpoint。它没有完整追踪训练过程中参数如何进入又离开稀疏子网;干预实验集中在 DS-Qwen 和 Qwen2.5-VL 的数学推理设置,模型规模、Agent、具身任务和其他领域尚未覆盖。(10^{-5}) 阈值与 bfloat16 checkpoint 也意味着,这里的稀疏是数值意义上的可见稀疏,不是严格的零参数证明。
为什么这篇工作值得关注?
OPD 正在成为 SFT、RLVR 之外的重要后训练路线,但过去更多关注它能否提升能力,很少有人追问能力究竟被写进了模型哪里。
这组结果给参数高效训练提供了更具体的线索。更新支持稀疏,说明未来不一定需要开放全部参数;能量集中支持低秩近似;偏离主方向则提示正交适配可能更契合 OPD。与此同时,不同模型的 FFN 与 Attention 能量比例并不相同,统一分配 LoRA rank 或稀疏预算未必合理。
更重要的判断来自 OPD 的位置变化。它在目标函数上像“密集蒸馏”,在参数空间里却更像“稀疏的 on-policy 编辑”。决定后训练更新形状的,可能不只是奖励稀疏还是标签密集,而是模型是否沿着自己的行为分布学习。
研究脉络:从离线模仿到参数几何
1. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
2011|AISTATS
DAgger 让学习器在自己的状态分布上收集监督,奠定了交互式、on-policy 模仿学习的基本思路。
2. Distilling the Knowledge in a Neural Network
2015|NIPS Deep Learning Workshop
知识蒸馏用教师分布监督学生,但训练数据通常来自固定样本或教师轨迹。
3. On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes
2024|ICLR
将教师反馈施加到学生自己生成的前缀上,形成现代语言模型 OPD 的基本训练方式。
4. The Path Not Taken: RLVR Provably Learns Off the Principals
2025|研究论文
从几何角度发现 RLVR 避开源权重主方向,为分析 on-policy 后训练的参数路径提供依据。
5. Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
2026|NeurIPS
发现 RLVR 主要修改小规模子网络,并证明仅训练这些坐标即可恢复完整效果。
6. Dense Supervision, Sparse Updates: On the Sparsity and Geometry of On-Policy Distillation
2026|南京大学
把同样的参数分析扩展到密集教师监督,证明 OPD 仍保留小规模、稀疏、偏离主方向的 on-policy 更新结构。
总结一下
这项研究没有提出新的 OPD 损失函数,而是解释了 OPD 在模型内部留下了什么。
教师对整条学生轨迹提供密集监督,却没有广泛重写模型。变化集中在一组跨层分布、以 FFN 为主、避开源权重主方向的坐标中;只训练这组坐标,几乎可以恢复完整 OPD 的推理性能。
它给出的结论并不是“OPD 只需要少量参数”这么简单。更准确的说法是:学生沿着自己的行为分布学习时,即使教师逐 token 纠错,新能力仍可能以局部参数编辑的方式写入模型。这为 OPD 专用的稀疏适配、低秩设计和优化器研究提供了可操作的起点。
- • 论文题目:Dense Supervision, Sparse Updates: On the Sparsity and Geometry of On-Policy Distillation
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
