题目:Time cumulative effects and machine learning-driven forecasting of cyanobacterial blooms in data-sparse eutrophic lakes
期刊:Journal of Hydrology
作者:Kaili Zhang,Tianci Qi,Ming Shen,Yinguo Qiu,Zhigang Cao,Yaqin Jiao,Hongtao Duan
发表日期:2026年1月14日
DOI:10.1016/j.jhydrol.2026.134966
蓝藻有害藻华严重威胁全球湖泊淡水安全。及时预测其规模与空间分布对减轻生态风险至关重要。传统机理模型依赖大量数据输入、明确边界条件与密集计算,在大多数湖泊中难以应用。本研究提出一种机器学习框架,通过智能整合稀疏监测站点与卫星数据,并构建时间累积效应变量(定义为环境变量在过去多日的平均值或累计值),以克服上述限制。基于中国巢湖23年观测数据,本研究评估了四种算法——随机森林、XGBoost、人工神经网络与岭回归,用于1/3/7天提前期的蓝藻水华预测。随机森林通过对累积变量的策略性特征选择,在蓝藻水华百分比预测中取得最优的1天预测性能(均方根误差=4.18%,决定系数=0.81)。随机森林在时间模式识别中优于其他模型,并在所有预测时段保持稳健性能(均方根误差:4.18%–6.26%,决定系数:0.59–0.81)。在空间分布预测方面,随机森林模型通过对稀疏站点数据的动态插值,实现了优越的1天预测精度(均方根误差=5.05%,F1分数=0.84),优于3/7天预测。本方法计算高效,利用稀疏监测数据即可实现1–7天空间分布的可信预测,为全球数据稀缺的富营养化湖泊提供了可迁移的主动管理方案。
蓝藻有害藻华已成为全球内陆水体最严重的环境问题之一。随着气候变化与人类活动加剧,其发生范围与频率持续扩大,对水质、水生生态与公众健康构成严重威胁。目前蓝藻水华预测主要依赖机理模型,虽能较好模拟其动态过程,但存在数据需求大、计算成本高、参数调整复杂等局限,难以适用于监测数据稀缺的湖泊。相比之下,机器学习方法具有处理非线性关系、适应性强、预测速度快等优势,逐渐成为水华预测的研究热点。
然而,机器学习预测仍面临两大挑战:一是如何有效构建预测变量。现有研究多使用环境变量的瞬时值,忽视了其对蓝藻生长的累积与滞后效应;二是如何实现高精度的空间分布预测。传统方法在平衡计算可行性与空间异质性表征方面存在不足,遥感方法易受云层干扰,气象再分析数据则空间分辨率较低。针对这些挑战,本研究以长期遭受蓝藻水华困扰的巢湖为案例,构建了一个融合时间累积效应与空间插值技术的机器学习预测框架,旨在实现蓝藻水华百分比与空间分布的多时段精准预测。
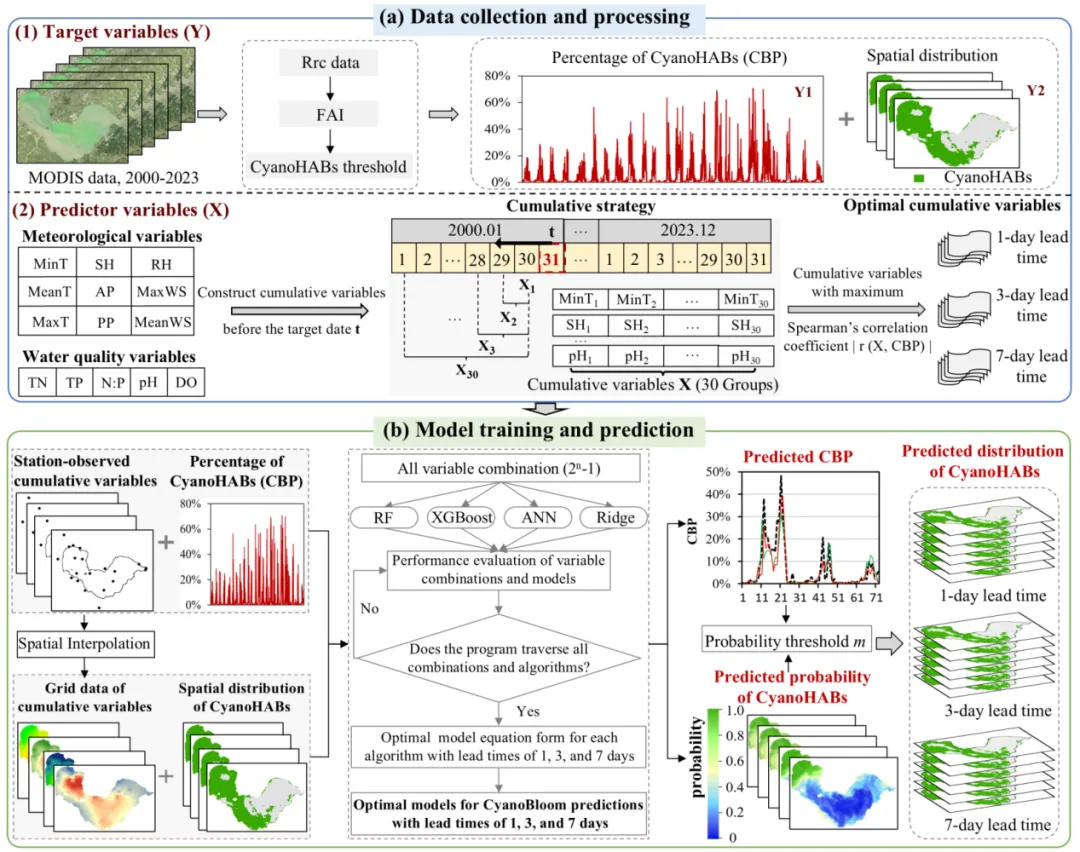
本研究以巢湖为研究区,整合了2000–2023年共23年的多源数据。蓝藻水华数据基于Terra/MODIS卫星影像,采用已有算法提取了蓝藻水华百分比与空间分布数据集。环境变量包括气象数据(温度、风速、日照时数、相对湿度、降水、气压)与水质数据(总氮、总磷、氮磷比、pH、溶解氧),来源于中国气象局与安徽省巢湖管理局。
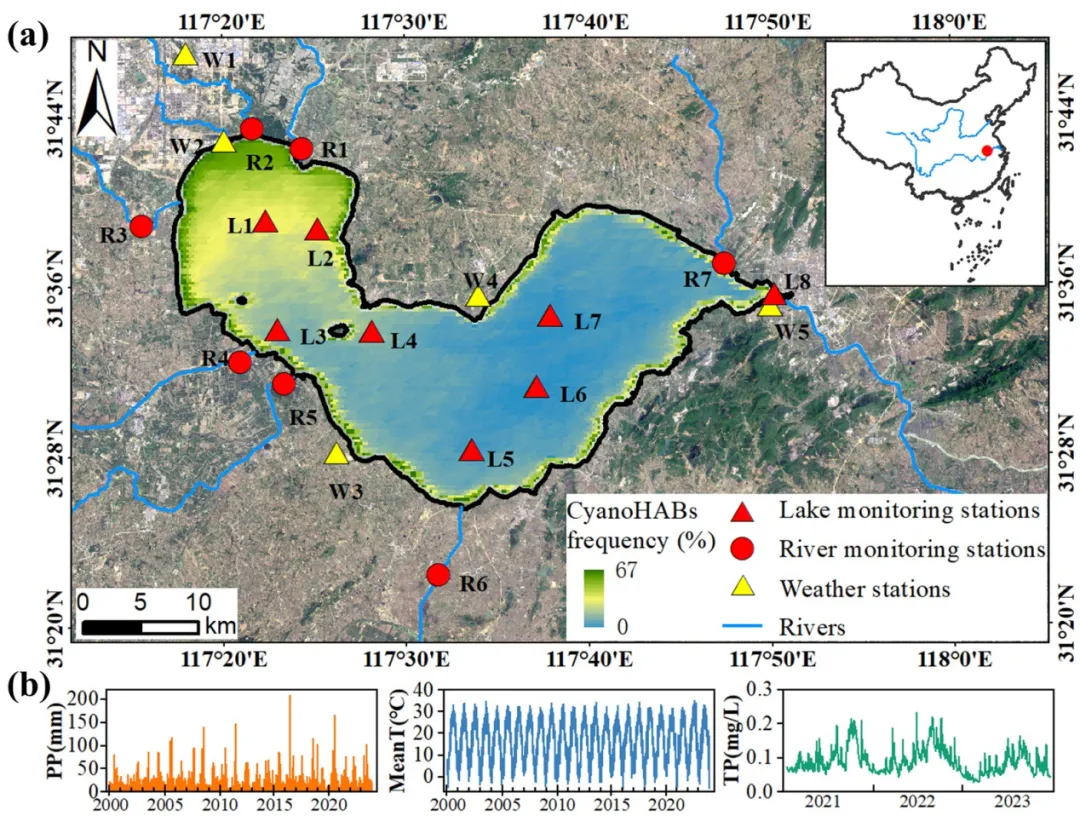
图1 巢湖及观测站点位置示意图;(b) 降水量、平均气温与总磷的年际变化趋势
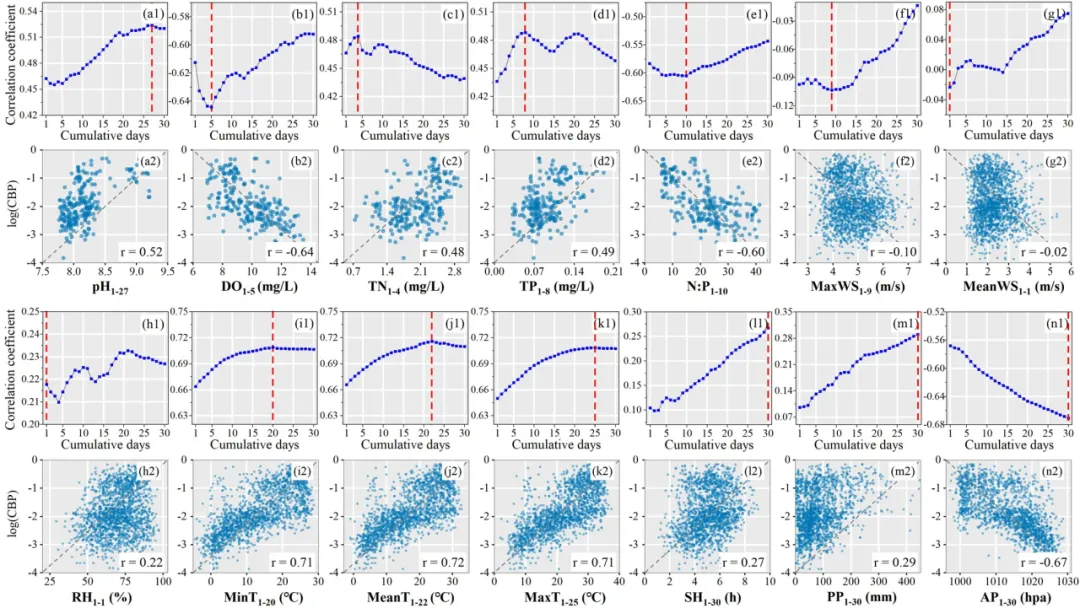
为捕捉环境因子的滞后效应,研究构建了时间累积变量:针对不同预测时段(1/3/7天),回溯最多30天的历史数据,计算各环境变量的累积均值(降水为累计值),并通过斯皮尔曼相关分析筛选与蓝藻水华百分比最相关的累积时间窗口作为模型输入。为实现空间预测,研究发展了TIN增强的反距离权重插值方法,将稀疏站点数据转换为连续空间场,有效提高了插值精度。
研究选取了随机森林、XGBoost、人工神经网络三种机器学习算法与岭回归进行对比,通过穷举搜索进行变量选择,以决定系数与均方根误差作为模型性能评价指标,并进一步将最优模型用于蓝藻水华空间概率制图与二值化分布预测。
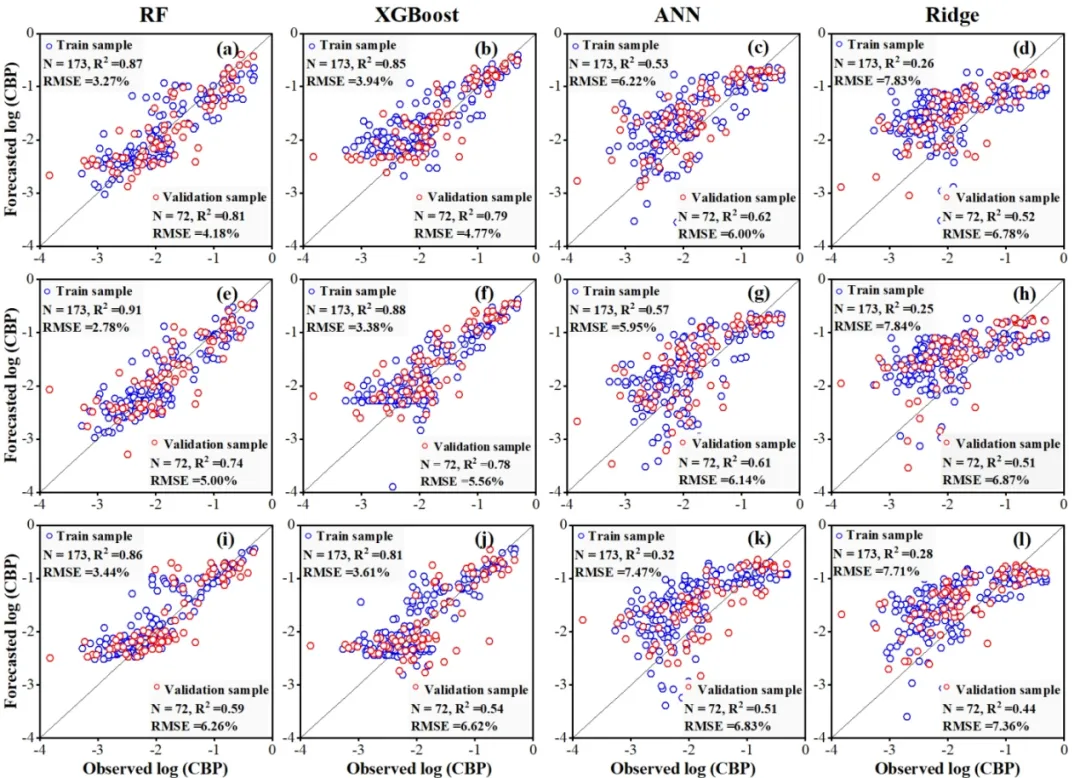
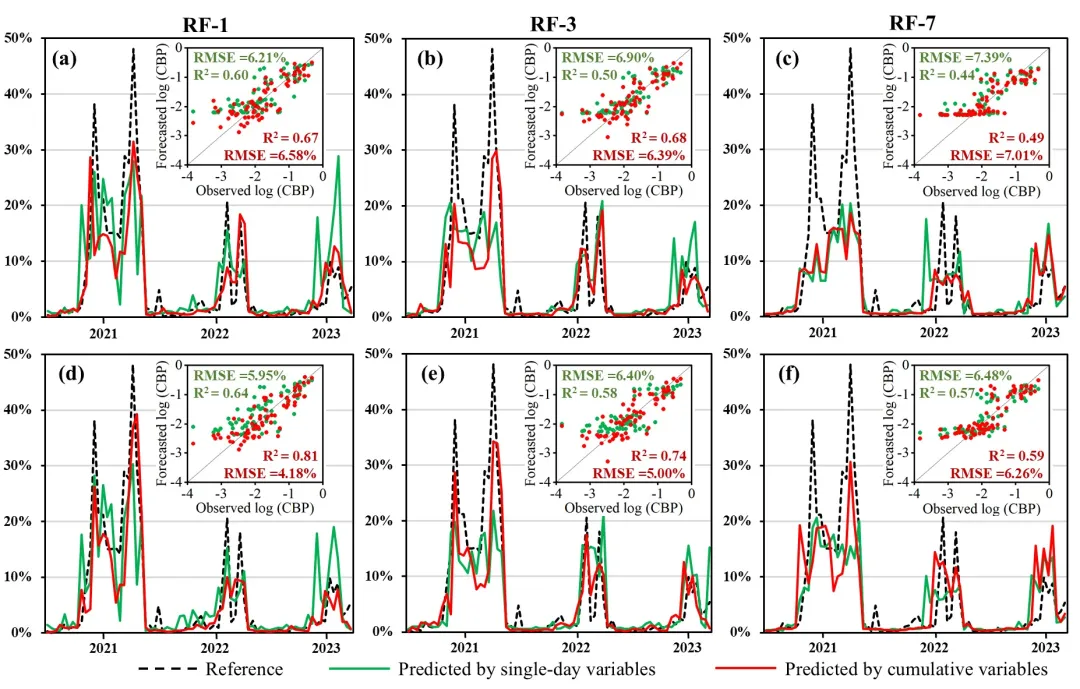
在蓝藻水华百分比预测方面,随机森林模型在1天预测中表现最优(决定系数=0.81,均方根误差=4.18%),其性能随预测时长增加而逐渐下降。与使用单日变量相比,引入时间累积变量使1天预测的决定系数提升26.56%,显著提高了预测精度。融合气象与水质数据的模型预测效果优于仅使用气象数据的基线模型,表明水质监测对预测具有增量价值。
图4 RF、XGBoost、ANN及岭回归模型在训练集与验证集上1天(a-d)、3天(e-h)及7天(i-l)预测精度对比
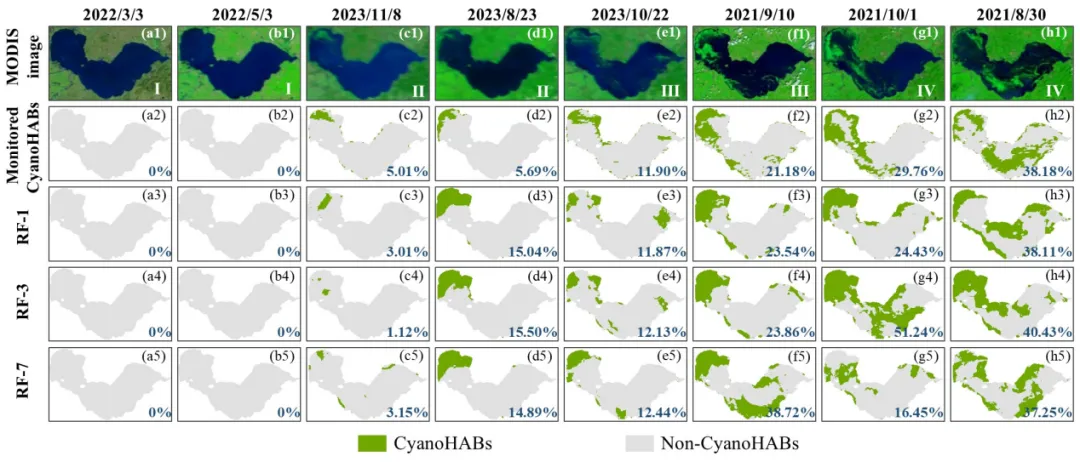
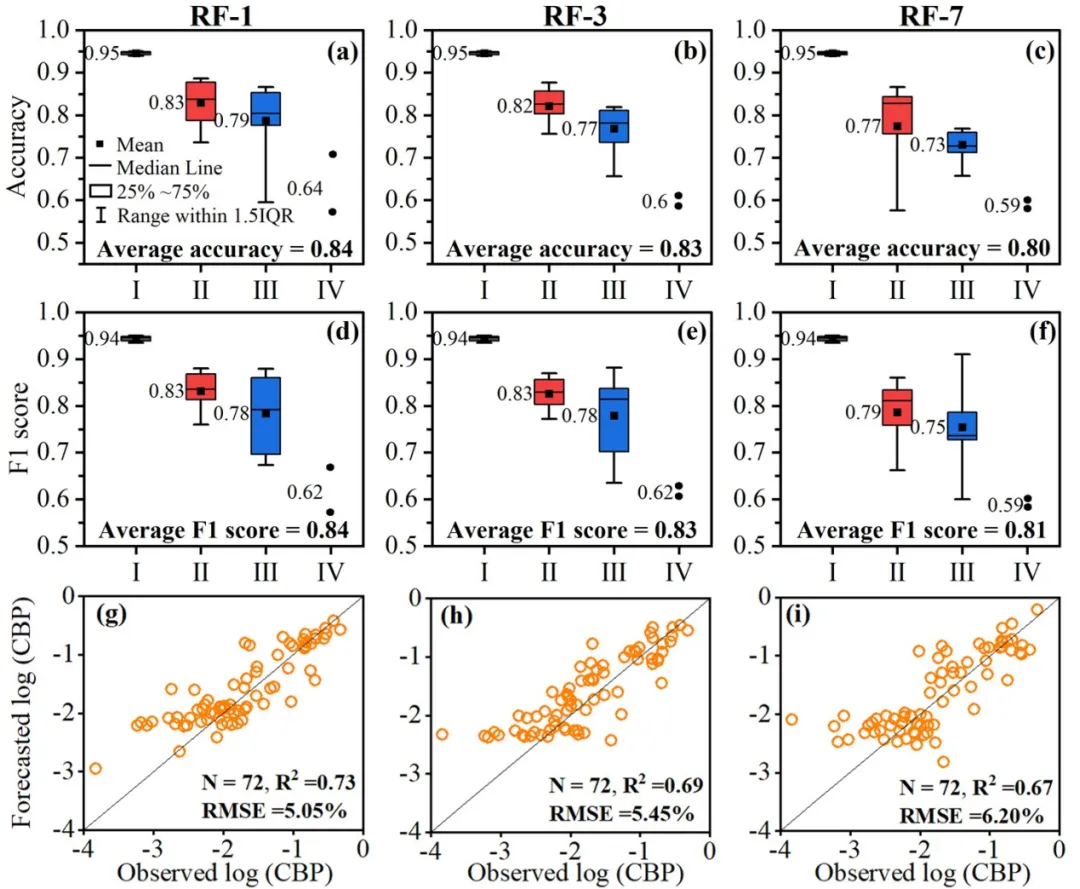
在空间分布预测方面,基于随机森林的框架在1天预测中实现了84%的像元精度与0.84的F1分数,能有效识别面积大于0.25 km²的水华斑块。模型对不同规模水华的预测能力存在差异,对小至中等规模水华预测精度较高(73–83%),而对大规模水华的预测精度相对较低(59–64%),主要受训练数据不平衡与非线性的水华扩张动力学影响。
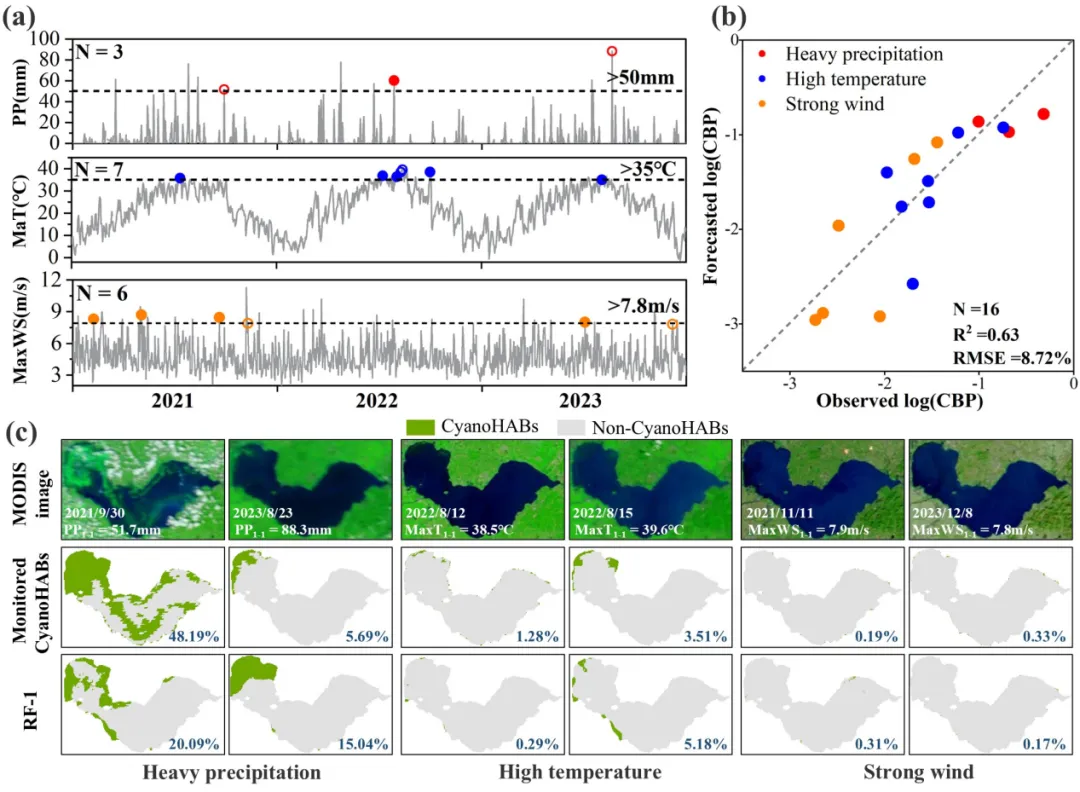
在极端天气情景下(强降水、高温、大风),模型仍保持较好的预测稳定性(决定系数=0.63),能够捕捉降水后水华萌发、高温对水华的抑制效应以及强风对水华的驱散作用,体现了框架在气候胁迫情景下的应急响应潜力。
本研究构建的预测框架在数据稀缺的富营养化湖泊中展现出良好的应用前景,但仍存在若干局限,为未来研究指明了方向:
第一,当前框架依赖无云卫星影像进行验证,夏季水华高发期常受云层干扰,影响空间验证频率。未来可融合多源卫星数据(如Sentinel-2、Landsat-8、GOCI-II),构建虚拟卫星星座,以提升数据覆盖与时空连续性。
第二,基于站点插值的空间变量虽能反映大尺度空间梯度,但难以完全捕捉富营养化湖泊中复杂的湖内生化梯度与局部过程。未来可探索耦合机理模型与机器学习的混合架构,以更好地表征水华生消的生态过程与突发性人为干扰(如调水、清淤)的影响。
第三,模型对大规模水华事件的预测能力仍有提升空间。未来可引入代价敏感学习、面向空间不平衡数据的过采样等先进算法策略,并整合更多能反映生态阈值或突发扰动的影响因子,以提高对稀有但高影响事件的检测性能。
第四,本研究确立的关键预测变量(如温度、氮磷比)及其累积时间窗口在具有不同营养状态、气候区域与形态特征的湖泊中的普适性仍有待验证。未来需在更多湖泊中进行移植与适应性调试,以推动框架的广泛业务化应用。
引用
Zhang, K., Qi, T., Shen, M., Qiu, Y., Cao, Z., Jiao, Y., & Duan, H. (2026). Time cumulative effects and machine learning-driven forecasting of cyanobacterial blooms in data-sparse eutrophic lakes. Journal of Hydrology, 134966. https://doi.org/10.1016/j.jhydrol.2026.134966
注:本文为未经编辑的预印版本,最终内容以正式出版为准。
本文由【生态风险与韧性前沿】发布,欢迎转发分享,转载请注明出处。
关注我们,共同探索生态风险与韧性提升的发展之路。