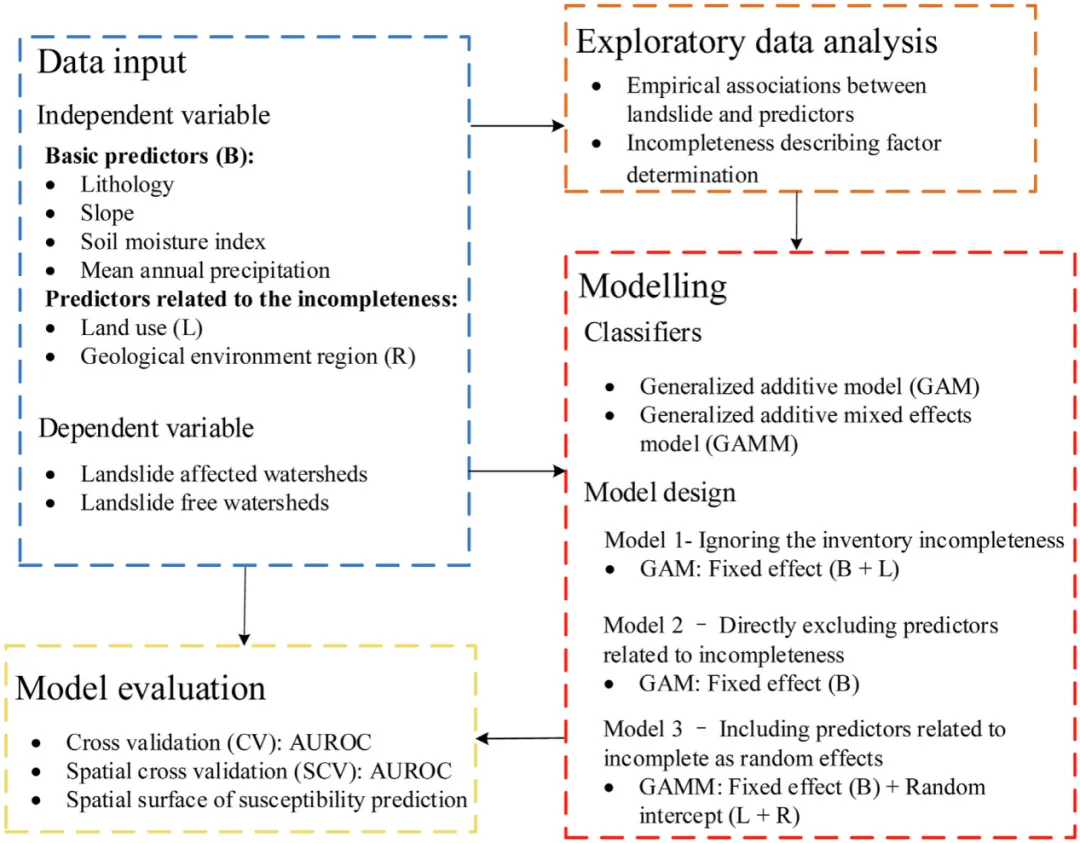
南京信息工程大学的Qigen Lin等针对中国国家级滑坡易发性评估中滑坡数据不完整这一关键问题,开展了系统性的建模研究。该研究基于全国地质灾害详细调查数据,选取岩性、坡度、土壤湿度指数、年均降水量、土地利用和地质环境区等六类影响因子,通过对比三种不同数据处理策略下的广义可加模型(GAM)与广义可加混合模型(GAMM),揭示了滑坡清单不完整性对易发性模型结果的影响,并提出了一种能有效抵消数据偏差的混合效应建模方法。研究成果为在数据不完备条件下开展大范围滑坡风险评价提供了重要方法论支撑。
本研究以中国全境为研究对象,采用了一种系统性的数据处理与建模框架,旨在揭示和纠正由滑坡数据不完整性引入的建模偏差。研究首先基于HydroSHEDS数据库划分子流域作为空间制图单元,共包含73,602个子流域,平均面积约为129.1平方公里,这一选择不仅符合水文地貌单元的一致性,也有助于缓解点状滑坡数据在空间代表性上的不足。滑坡数据来源于国家地质灾害详细调查,经过筛选共获得53,071条降雨诱发型滑坡记录,并按照1:1的比例随机选取了相同数量的非滑坡子流域样本,构成建模的基础数据集。
在影响因子选取上,研究综合考虑了地质、地形、气候、水文和人类活动等多个维度,最终确定六类因子:岩性、坡度、土壤湿度指数、年均降水量、土地利用和地质环境区。其中,岩性、坡度、土壤湿度指数和年均降水量被视为描述滑坡发生环境条件的“固定因子”,而土地利用和地质环境区则被识别为可能反映数据收集完整性的“偏差因子”。地质环境区是根据中国地质结构、地貌和气候条件划分的七个区域,其划分本身就隐含了不同区域在灾害调查投入、可及性和数据详实程度上的系统性差异;土地利用类型则直接影响滑坡的识别、调查和记录概率,例如在人类活动密集区或森林覆盖区,滑坡数据的完整性可能显著不同。
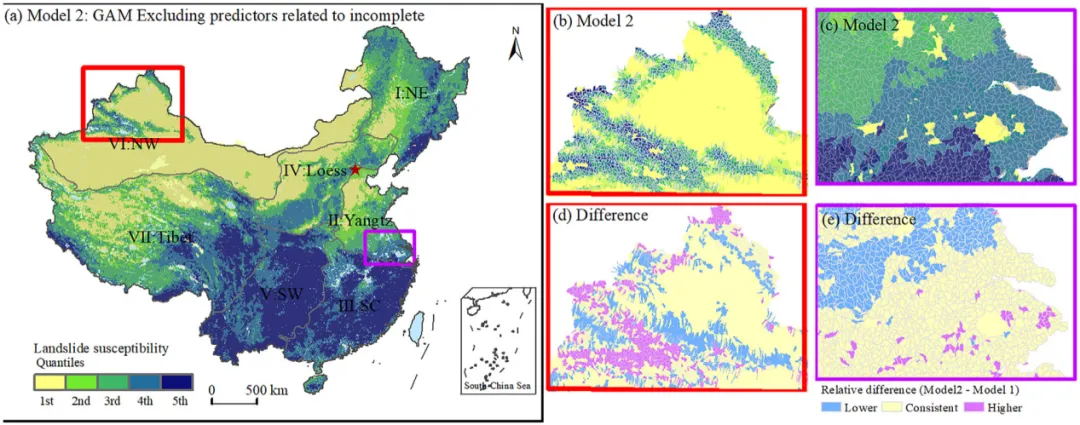
为明确评估数据不完整性对模型的影响,研究设计了三种对比建模方案:模型1采用标准广义可加模型,将所有六个变量作为固定效应纳入,忽略可能存在的偏差;模型2则剔除被认为与数据完整性相关的土地利用和地质环境区变量,仅使用其余四个固定因子进行建模;模型3创新性地引入广义可加混合模型,其数学表达形式为:
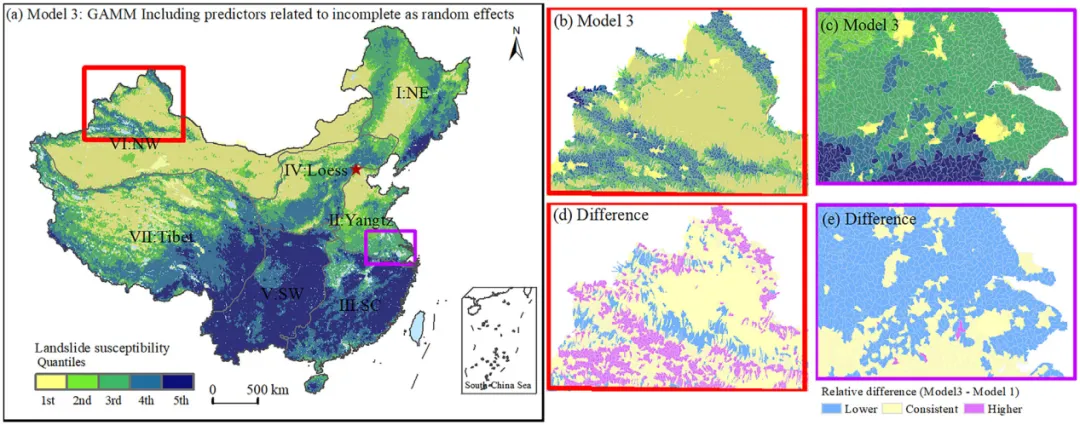
在该模型中,岩性、坡度等四个因子仍作为固定效应,而土地利用和地质环境区则作为随机效应引入。随机效应项假设服从均值为零的正态分布,用于捕捉和量化由这些变量所代表的、与研究区域系统性差异相关的未观测变异。模型在训练阶段同时估计固定效应与随机效应参数,但在最终的空间预测阶段,仅使用固定效应部分进行计算。这种设计的核心优势在于,它允许模型在训练过程中知晓并适应数据收集的系统性偏差,而在对外预测时则将其平均掉,从而得到更纯粹反映滑坡发生环境潜势的估计。
模型评估采用严格的交叉验证策略,包括非空间交叉验证和更具挑战性的空间交叉验证,以受试者工作特征曲线下面积作为主要量化指标。更重要的是,研究并未止步于统计指标的比较,而是进一步对生成的易发性图进行了地貌合理性分析,即结合中国宏观地形、地质构造和气候格局,定性判断预测的高风险区是否与已知的滑坡活跃带相符,从而鉴别模型是真正捕捉了灾害规律,还是仅仅复现了训练数据的调查偏差。
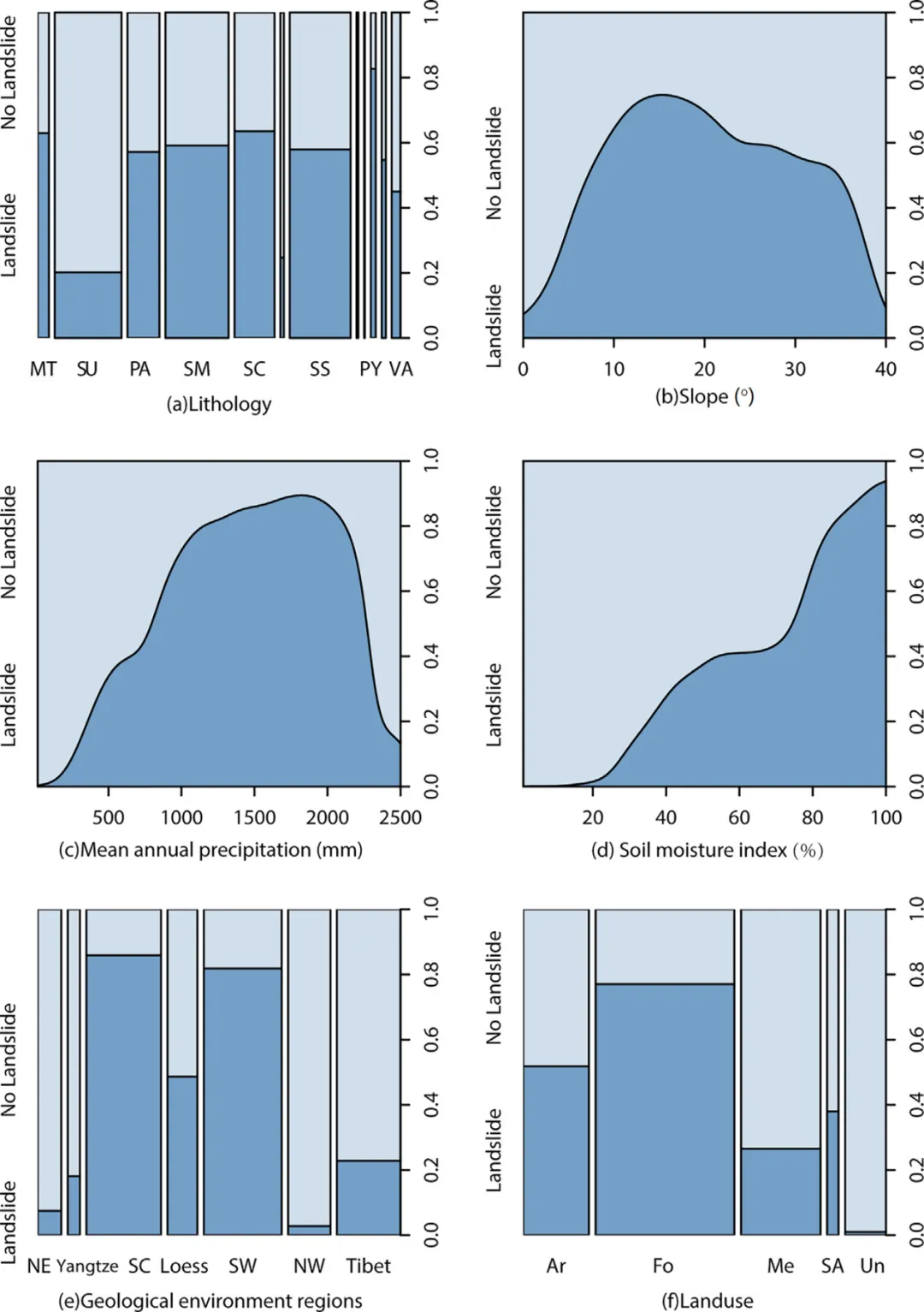
通过对影响因子与滑坡记录进行探索性数据分析,研究揭示了明显的空间数据不完整性模式。滑坡记录高度集中于中国南方,尤其是华南基岩丘陵区和西南岩溶山区,而在青藏高原、西北干旱区等地域广阔、地形复杂的地区记录稀少。条件密度分析显示,不同地质环境区之间、不同土地利用类型之间的滑坡记录比例存在显著差异,这种差异与各区域的地形陡峭程度或降雨量水平并不完全匹配,进一步证实了土地利用和地质环境区可作为数据编录完整性的代理指标。
三种模型的交叉验证结果呈现出一个关键发现:在传统的非空间交叉验证中,模型1取得了最高的AUROC中位数(0.90),模型2和模型3均为0.88,这似乎表明忽略偏差的模型拟合效果更佳。然而,当采用更贴合实际预测场景、要求模型预测未知空间位置情况的空间交叉验证时,模型3展现了最强的稳健性,其中位数AUROC为0.84,性能下降幅度最小。相比之下,模型1的空间验证表现最差,且其预测结果的不确定性(四分位距)最大,这表明它对训练数据中的空间偏差过于敏感,泛化能力不足。
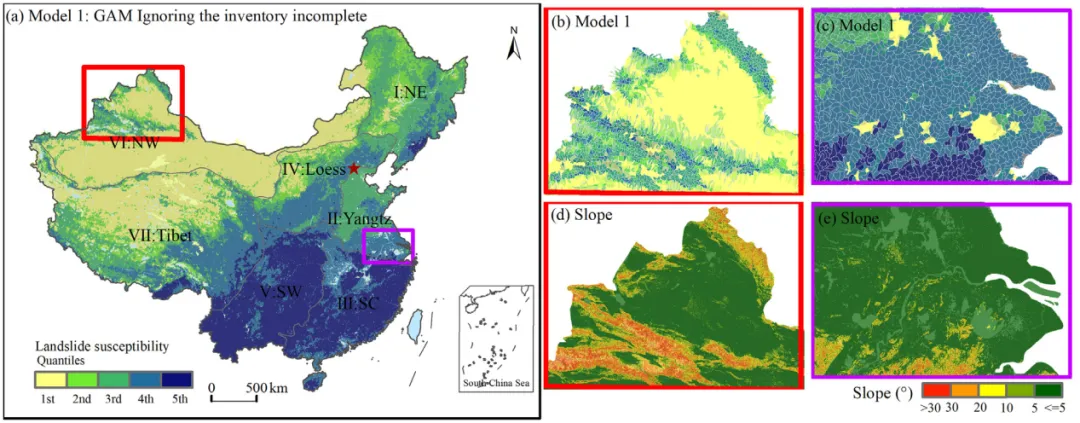
对易发性图空间格局的深入分析,清晰地展现了不同建模策略的实质影响。模型1生成的易发性图呈现强烈的“南高北低”格局,极高易发性区几乎全部集中在华南和西南地区。然而,这种格局与中国实际的地形和地质灾害背景存在明显矛盾:在西北部的天山、阿尔泰山,以及青藏高原周缘的喜马拉雅山、横断山脉等区域,地形陡峻、构造活动活跃,是公认的滑坡高风险区,但模型1在这些区域普遍预测为低至中等易发性。这强烈暗示模型1仅仅学会了“在调查详细的地区预测高风险”,而非真正识别滑坡的地质地形控制因素。
模型2通过剔除偏差变量,得到的易发性图更为均衡,高风险区更广泛地分布于各大山系,包括西北山区和青藏高原边缘。但在一些滑坡数据极端稀缺的区域,如昆仑山部分地区,预测的易发性等级仍然偏低。模型3则表现最佳,其生成的易发性图不仅在高风险区的空间连续性上更好,而且成功在数据稀缺的西北高山区域(如天山、阿尔泰山、昆仑山)识别出了连续的高易发性带,这与区域地质调查知识和相关区域性研究结论更为吻合。同时,模型3在长江中下游平原等平坦区域的预测也更为保守,避免了因这些区域经济发达、调查数据多而可能导致的过高估计。
该研究证实,在国家级滑坡易发性建模中,忽视滑坡清单的不完整性会导致模型结果严重偏离真实的地质地理规律,即使其表现出较高的统计性能。广义可加混合模型通过将描述数据收集偏差的变量作为随机效应,能够在建模过程中控制这些干扰,从而在预测中生成更稳健、更合理的地理格局。该方法特别适用于中国这类幅员辽阔、数据调查程度不均的国家,为构建可靠的大尺度滑坡风险底图提供了关键方法支持。研究也强调,滑坡易发性评估应超越单纯的统计指标比较,必须结合空间验证与地貌知识进行综合诊断,以避免被数字上的高精”所误导。
该研究成果发表于Geoscience Frontiers,详细内容见:Lin Q, Lima P, Steger S, et al. National-scale data-driven rainfall induced landslide susceptibility mapping for China by accounting for incomplete landslide data[J]. Geoscience Frontiers, 2021, 12(6): 101248.
原文链接:https://doi.org/10.1016/j.gsf.2021.101248
投稿邮箱:401784656@qq.com
欢迎各位的关注与来稿!
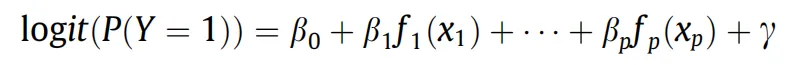


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
