到目前为止,本章一再反复提及“token”一词,那么token到底是什么呢?又该如何翻译呢?
不同的领域,token有不同的含义,比如:令牌、标记、代币、通证、支付标记,等等。在AI语境下,token已演变为:模型输入序列中的最小可处理单元,是信息被编码、嵌入、注意力计算的基本原子,如图3-48所示。
图3-48 token与AI模型的关系
图3-48中,AI模型是以Transformer结构为例。另外,token id与token是一对一的关系,是token的一个代指。可以看到,token(或token id)是AI模型的(原子)输入。
只是,token该如何翻译呢?AI领域,token一般翻译为“词元”,但是更多时候,大家采用的是token本身,不使用其中文翻译。
通过图3-48可以看大,人类输入的文本信息(Text),经过Tokenization,变成一个个token(id)以后,才能输入AI模型。Tokenization翻译为“分词”,不过有时候,大家也是直接使用其单词本身。
Tokenization就是将Text分解为Token的一套解决方案。我们看一个例子:
南京市长江大桥欢迎您
这句话该怎么分词?如下的分词方法,到底该选哪一种?
南/京/市/长/江/大/桥/欢/迎/您
南京/市/长江/大桥/欢迎/您
南京市/长江大桥/欢迎/您
......
还是选“南京 市长 江大桥 欢迎 您”?
南京/市长/江大桥/欢迎/您
我们再看一个例子,
Don't count your chickens before they hatch
这个又该如何分词?是不是直接按照空格分词就行了?是的,类似英语这样的单词间有空格的书写方式的,确实有一种冲动:按照空格分词,一个单词一个token。但是,这样的分词方法,有一个明显的缺点:单词/token太多了。牛津英语词典(Oxford English Dictionary)收录了60多万个条目,考虑到“walk/walks/walking/walked”只记作一个条目,那么按照空格分词,英语词表大小(Vocabulary Size)会超过100万(1000K个token)。但是,并不是说词表越大,模型效果越好,这需要一个折中。而当前主流大模型词汇表大小,一般是100K~200K。也就是说,按照空格分词,单从词表大小这一个维度而言,就不是个好主意。
那么到底该如何分词呢?乱花渐欲迷人眼,万花丛中一点红。在众多分词算法中,BPE算法可以说是非常经典、非常基础的存在——很多著名大模型都采用了BPE算法(及其扩展算法BBPE)。
3.7.1 BPE基本算法
BPE(Byte-Pair Encoding,字节对编码)算法,最早由Philip Gage于1994年2月在论文“A New Algorithm for Data Compression”中提出。
2015年,Rico Sennrich等人将BPE首次引入了神经网络机器翻译领域。自此,BPE奠定了在AI领域的江湖地位。
BPE虽然在AI领域尤其是在大模型领域中举足轻重,但是它一开始的目标却只是一个数据压缩算法。不过这也正常,毕竟英语世界,按照字符分割token,则单词被切的稀碎,按照单词分割token,则词表有点太大,BPE则正好介于两者之间。所以,BPE和机器翻译乃至大模型的相遇,也算是天作之合。
下面我们就先以英文为例,介绍BPE算法。
理解BPE,有两个关键词非常重要,一个是“压缩”(来自于论文标题:A New Algorithm for Data Compression),另一个是“字节对”(来自于算法名称:Byte-PairEncoding)。
压缩一词好理解,那么是字节对呢。这就要从ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)说起。英文字母及其他字符,都有着对应的ASCII码,如表3-30所示。
表3-30 部分ASCII示意
二进制 | 十进制 | 十六进制 | 字符 | 说明 |
0000 0000 | 0 | 0x00 | NUL(null) | 空字符 |
0000 0001 | 1 | 0x01 | SOH | 标题开始 |
0100 0001 | 65 | 0x41 | A | 大写字母A |
... | ... | ... | ... | ... |
0101 1010 | 90 | 0x5A | Z | 大写字母Z |
... | ... | ... | ... | ... |
0110 0001 | 97 | 0x61 | a | 小写字母a |
... | ... | ... | ... | ... |
0111 1010 | 122 | 0x7A | z | 小写字母z |
... | ... | ... | ... | ... |
0111 1111 | 127 | 0x7F | DEL(delete) | 删除 |
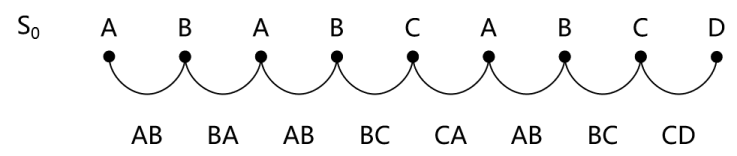
可以看到,每个ASCII码正好对应着八个比特,也就是一个字节。“字节”有了,“字节”对呢?以字符串S0= “ABABCABCD”为例,如图3-49所示。
图3-49 字节对示意
可以看到,所谓字节对,就是相邻字符两两结对。图3-49中的字节对,如表3-31所示。
表3-31 字符串S0的字节对
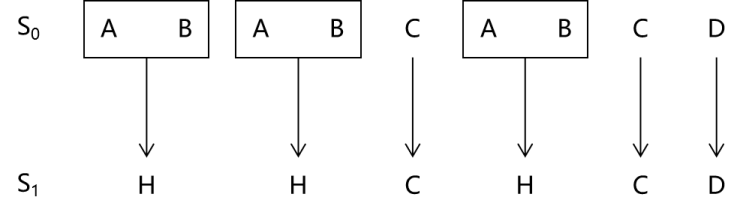
有了字节对,就可以按照字节对压缩了。将数量最对的字节对是“AB”(一共有3对),用一个符号代替。可以想象,这个符号不能是S0中出现的字符,否则会出现二义性。泛化地讲,S0中可能出现ASCII码中任意一个字符,所以这个字符必须处于ASCII码之外。这是编程需要考虑的,这里我们暂时不纠结这么多,假设就用“H”替代“AB”,于是得到了S1。,如图3-50所示。
图3-50 字节对替换
这种替换,就是压缩(用两个字符替代一个字符),可以表达为,
同理对S1继续重复上述算法,就可以得到S2(假设“HC”替代为“G”),
对S2再重复上述算法,就可以得到S3(假设“GG”替代为“X”)
至此,BPE压缩算法迭代结束,因为再也无法压缩。
需要补充一点,BPE压缩算法迭代结束的条件有两个:或者是压无可压,或者是达到指定迭代步数。比如对于S0= “ABABCABCD”,只迭代一步,那么就只能压缩到S1。
有了BPE压缩算法,BPE的解压算法,则呼之欲出,只需要反向替换就可以了,
可以看到,BPE算法相对来说还是比较简单的,进一步,BPE分词算法,也没有那么复杂。
3.7.2 BPE分词算法
BPE分词算法,是以BPE算法为基础,但是各个模型厂商可能也会叠加了自己的细节算法。本小节只介绍通用算法。BPE分词算法,分为三大部分:token词表构建、token编码、token解码。
3.7.2.1 token词表构建
所谓BPE词表构建,就是将训练样本中一堆单词(记为text),基于BPE算法,分割成一系列的token。这一系列的token,组成词表(token_voc,vocabulary)。
在构建词表之前,首先要设定词表大小(记为N)。词表大小,与大模型的能力息息相关,也与大模型的训练、推理效率密切相关。如何确定词表大小,是另外一个深刻的话题,由于篇幅和主题原因,本小节不涉及。单纯从词表构建的角度来讲,词表大小与词表构建算法何时结束相关。
确定了词表大小之后,就可以进行初始化,也就是先预置一些token进去。不同的模型,有不同的实现方法。这里举一个经典例子,仅供参考,如代码3-1所示。
代码3-1词表初始化示例
# 伪代码表示
initial_vocab = {
# 基础ASCII(95个可打印字符)
'a', 'b', 'c', ..., 'z', # 26
'A', 'B', 'C', ..., 'Z', # 26
'0', '1', '2', ..., '9', # 10
'!', '"', '#', '$', '%', '&', "'", '(', ')', '*', '+',
',', '-', '.', '/', ':', ';', '<', '=', '>', '?', '@',
'[', '\\', ']', '^', '_', '`', '{', '|', '}', '~', # 33个标点/符号
' ', '\t', '\n', # 3个空白符
# 控制标记(Special Tokens)
'<|endoftext|>', '<|pad|>', '<|unk|>' # 3-10个
}
# 总计:约 100-110 个初始token
初始化之后,就可以正式开启词表构建之旅。假设text = “low lower lowest dark darker darkest highhigher highest”。
第一步,根据空格分词(或者其它标点符号分词,本小节以“空格”分词为例),将训练样本分解为一个个单词列表(记为words)。需要强调的是,空格须归属于某个单词,或者放在单词的开头,或者放在单词的结尾。这里我们将空格归属于单词的结尾,并且为了易于阅读,我们将空格用“#”替代
有空格和没空格,核心的区别,在于字节对的构建,如图3-51所示。
图3-51 有空格与无空格的区别
可以看到,空格的作用就是阻断跨单词的字节对结合,以免不同的单词结合在一起,搞得“血肉模糊”。
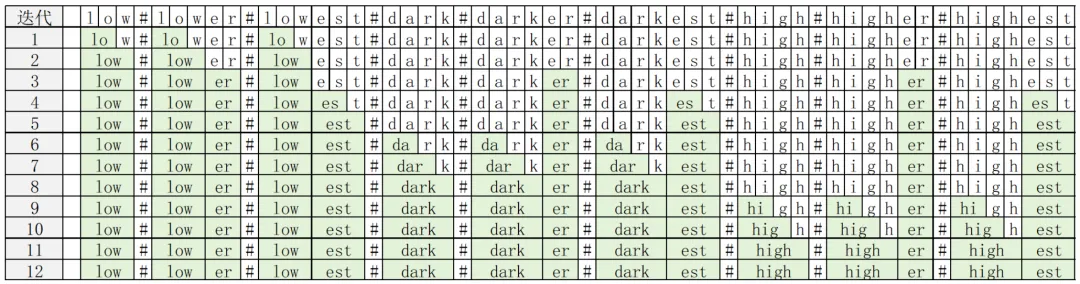
第二步,基于上述原则,再结合BPE算法,就可构建出词表,如图3-52所示。
图3-52 BPE迭代分词
根据图3-52,就可以将words分解为一个个token。此时,有两种分解方法。一种是根据最后一个迭代分解,得到词表(token_voc),称为“最后迭代词表(Last Iteration Token Vocabulary,LITV)”
还有一种是根据每一次迭代的结果,得到词表(token_voc),称为“每次迭代词表(Every Iteration Token Vocabulary,EITV)”
说明:BPE_T,是BPE Tokenize的缩写,表示“基于BPE算法,做Token分词”。
虽然LITV的词表会更小,但是其编码能力比不上EITV(由于篇幅原因,这里不再详述),所以现代主流LLM,选用的都是EITV。
虽然这个例子本身,按照EITV,其词表size比简单按照单词分词的size还要大,但是考虑到足够多的样本分词以后,BPE分词算法还是能够有效减少词表的size的,而且其本根原因是将
排列组合的乘法变成加法
比如,words里有九个单词,其实是三个词根(low,dark,high)和三个级别(原级、比较级、最高级)的排列组合:9 = 3 * 3。而BPE将它们变成了加法:6 = 3 + 3。考虑到原级不需要后缀,所以一共只需要五个token。
考虑到英语中形容词、副词的数量,这种乘法变加法的方法,对于减少词表容量的效果是非常大的。再考虑到英语中其他前缀、后缀的造词法(比如,unlock、unknown、unusual、quickly、weekly、actively),BPE的效果是惊人的。
3.7.2.2 词表构建的产物
无论是LITV还是EITV,分词的结果,显然易见的一个输出是词表,我们记为vocab.json,比如,
代码3-2vocab.json示例
{
"lo": 1000, // token:tokeid
"low": 1001,
"er": 1002,
"est": 1003,
...: ...
}
这就是典型的词表形式,它记录了token和tokenid的关系。token由分词算法(比如BPE)获得,tokenid由分词算法自己分配,只要不重复就行,如图3-53所示。
图3-53 token与token id示意
除了词表(vocab.json),还有一个文件也很重要,我们记为merges.txt。该文件是BPE分词迭代过程的产物。每次迭代,merges.txt都严格按照时间顺序记录“字节对合并”的过程。
merges.txt虽然是分词迭代的产物,它的目的却是BPE编码的“控制器”。
3.7.2.3 token编码
merges.txt,看起来就是一个普通的文本文件,比如:
代码3-3merges.txt示例一
merges.txt示例一:
1. a b // 创建ab的规则(第1轮)
2. ab c // 创建abc的规则(第2轮)
3. c d // 创建cd的规则(第3轮)
但是,merges.txt是BPE算法中用于指导编码(Encoding)阶段的有序合并规则列表,它是一个线性有序序列(Ordered Sequence),记为
其中每个元素mi是一个二元组(Bigram):
表示:在当前序列中,当且仅当tleft和tright相邻且未被其他合并隔离时,将它们合并为新的符号单元。
BPE根据merges.txt进行编码,其基本算法为:
(1)严格全序:mi的索引i定义了应用优先级,i<j意味着mi必须在mj之前尝试
(2)贪心回退:每执行一次合并后,扫描指针必须重置到m1(第一行)重新开始
这么说,有点抽象,我们举个例子。假设,要编码“abcd”,那么按照“merges.txt示例一”,则编码为(具体编码过程从略,您可以自行推导),
如果merges.txt是另外的样子,
代码3-4merges.txt示例二
merges.txt示例二:
1.a b // 创建ab的规则(第1轮)
2.c d // 创建cd的规则(第2轮)
3. ab c // 创建abc的规则(第3轮)
那么,“abcd”将会编码为,
可以看到,merges.txt通过严格的行号顺序定义了"在遇到多种可合并情况时,必须优先选择哪一种"的确定性策略,确保分词与编码时,同一文本产生完全一致的Token序列。
当然,处于某种需要,我们可以人为地调整merges.txt的顺序,我们也可以将merges.txt与vocab.json做一个合并,这里另外的话题,无须深究。
3.7.2.4 token解码
token的解码比较简单。因为编码时,每个token都有着对应的Token ID,那么解码时,直接根据Token ID查表即可。假设词表,如表3-32所示。
表3-3 token词表举例
Token ID | 1 | 2 | 3 | 4 | 5 | 6 |
Token | I | love | 空格 | you | him | her |
如果token编码为,
那么,解码后的text为,
是的,这世界上最浪漫的数字,除了1314,也有可能是13234。
3.7.3 BBPE
BBPE(Byte-level BPE)是BPE算法的字节级变体,被许多大模型采用。其核心思想是:将文本视为原始字节流进行子词分词。
BBPE与Unicode(Universal(通用)+ Code(编码),统一码)的概念密切相关。抱歉,由于篇幅和主题的原因,本小节不能深入展开Unicode的讲述,只能举个例子说明BBPE和BPE的区别。
以“深度学习”为例,这四个字的UTF-8编码,如表3-33所示(UTF-8是Unicode的一种编码方式)。
表3-33 深度学习的UTF-8编码
中文 | 深 | 度 | 学 | 习 | 备注 |
UTF-8 | 230 183 177 | 229 186 166 | 229 173 166 | 228 185 160 | 三个字节 |
如果是BPE编码,它会将每个汉字所对应的UTF-8编码当作一个编码单元(心中认为是一个字节,虽然它们实际上是三个字节),按照BPE算法进行编码。
如果是BBPE编码,它会将每个汉字所对应的UTF-8编码中的每一个字节,按照BPE算法进行编码。
相对于BPE来说,BBPE最明显的优点,是在BPE编码时,不会出现OOV(Out-of-Vocabulary,未登录词)。比如,“龘”(dá),在词表构建时未出现过,也就是说vocabulary里没这个汉字的token。但是,在token编码时,最差的情况,也可以根据它的UTF-8编码(0x9F 0x98 0x85),编码成三个token:[0x9F, 0x98, 0x85]。


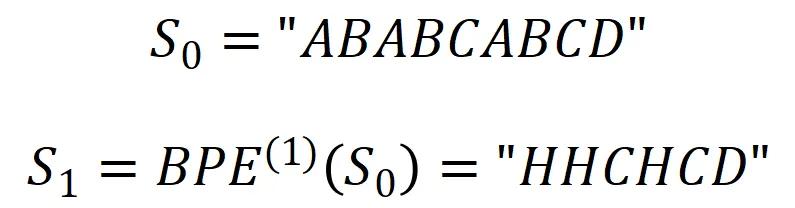
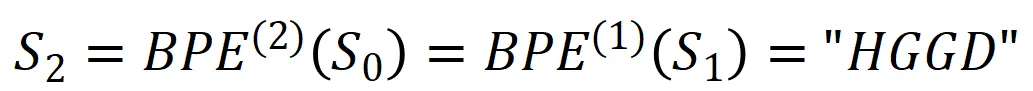
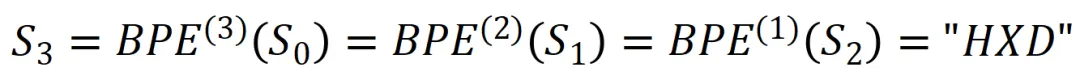
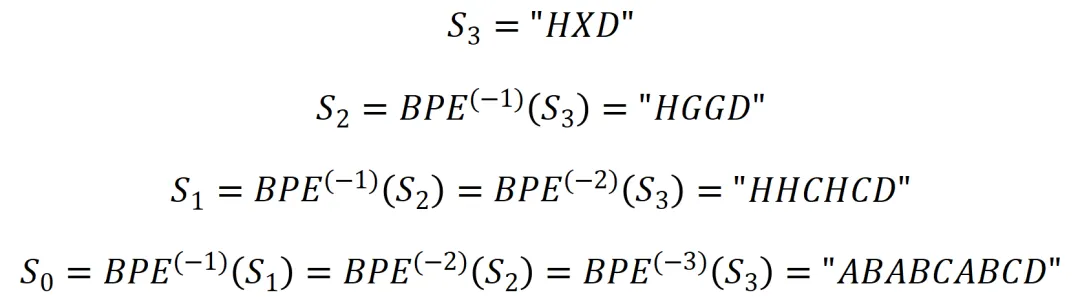

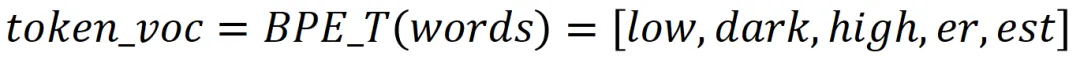
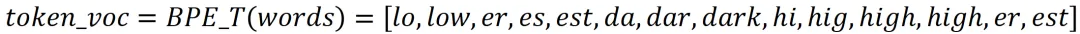

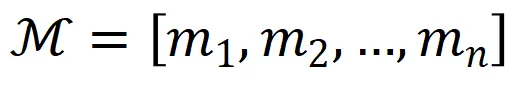
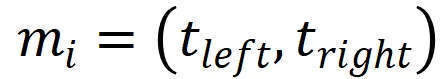
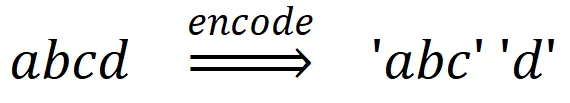
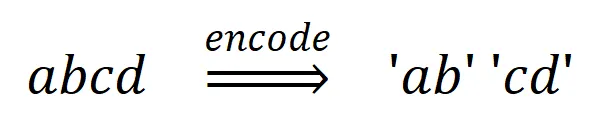
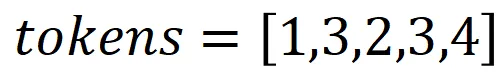
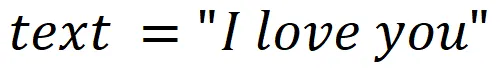


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
