
🐉 龙哥读论文知识星球来了!还在为大模型推理又慢又贵而烦恼?想了解如何让AI“聪明地偷懒”?星球每日更新AI前沿论文、资讯、招聘、开源代码,一站式干货,帮你快速掌握让大模型推理又快又准的秘诀!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文精准地戳中了当前大模型推理应用的一个核心痛点:效率与效果的平衡。它没有停留在“一刀切”的压缩思路上,而是引入了一个非常巧妙的“难度感知”机制,让模型自己学会“看题下菜”。这种思路不仅实用性强,能直接降低推理成本,其背后的“熵调控”视角也为理解强化学习如何影响大模型推理能力提供了新的洞见。对于从事大模型优化、推理加速和应用落地的同学来说,这是一篇非常值得细读和借鉴的工作。
原论文信息如下:
论文标题:
Compress the Easy, Explore the Hard: Difficulty-Aware Entropy Regularization for Efficient LLM Reasoning
发表日期:
2026年02月
发表单位:
南京航空航天大学, 滴滴国际业务集团
原文链接:
https://arxiv.org/pdf/2602.22642v1.pdf
想象一下,你让一个超级聪明的AI帮你解一道数学题。为了展示它的“思考过程”,它开始写:“首先,我们设未知数为x。回顾题干,关键信息是...根据公式...进行变形...考虑到边界条件...因此,x等于...” 一番操作下来,答案是对的,但看了几百个token,你钱包里的API调用费用也在“叮叮”作响。😅
这就是当前大模型推理(尤其是Chain-of-Thought,思维链)面临的核心矛盾:显式推理能提升准确性,但极其冗长低效。有没有办法让AI“聪明地偷懒”,既保持正确率,又把废话删光光?
今天要聊的这篇来自南京航空航天大学和滴滴的论文,就提出了一个非常巧妙的解法。它不像以前那样“一刀切”地逼模型写短点,而是像一位高明的老师,根据题目难度,决定让学生是“精炼答题”还是“充分思考”。结果呢?在多个数学推理基准上,答案长度砍掉30%以上,正确率却几乎没掉,甚至偶尔还能涨点。
它叫CEEH,全称是 Compress the Easy, Explore the Hard。下面,龙哥就带大家拆解一下这个让大模型“节能减排”还更“聪明”的新思路。
推理压缩的困境:精度与长度的两难
想让模型写短点,最直接的想法就是用强化学习,给它设计一个奖励函数:答案对了给高分,同时生成得越短,额外奖励越多。
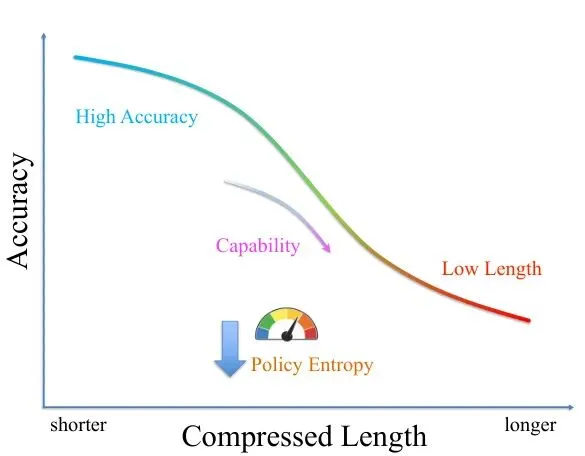
但问题来了。论文里的图一针见血地指出了这种“粗暴”压缩的后果:
图1:推理压缩中的精度-长度权衡:更短的回复往往以牺牲精度和降低策略熵为代价。
可以看到,随着我们加大“写短点”的惩罚力度(横坐标,长度惩罚系数增大),模型的回复长度(蓝色实线)确实显著下降了。但与此同时,模型的正确率(橙色实线)和策略熵(绿色虚线)也一起暴跌。
这里出现了一个关键术语:策略熵。在强化学习里,它衡量的是模型决策的“随机性”或“探索性”。熵值高,说明模型还在尝试多种可能的推理路径;熵值低,说明模型变得非常“固执”,只认准某一种输出方式。
论文指出,疯狂追求简短会引发“熵崩塌”。模型为了拿“短”的奖励,会迅速收敛到一种极其确定(低熵)的生成模式。但这种模式很可能是一条“捷径”或“死胡同”——对于简单题,也许蒙对了;但对于需要多步推导的难题,因为缺乏探索不同解题思路的能力,就很容易出错。
这就好比为了考试时写得快,你只背一种解题模板,遇到常规题可以,题目一灵活就傻眼了。CEEH核心思想:按难度分配“思考”资源
既然“一刀切”地压缩会导致熵崩塌和精度下降,那该怎么办?CEEH的灵感来源于一个非常自然的观察:
不是所有题目都需要“长篇大论”的思考。对于模型已经掌握得滚瓜烂熟的简单题,就应该鼓励它“精炼作答”,能省则省;而对于那些目前还经常做错的难题,则应该给它“松绑”,允许甚至鼓励它“多想想、多试试”不同的解法,保持探索空间,直到找到正确答案。
为了实现这个思想,CEEH框架主要由两大核心组件构成:
1. 难度感知的熵正则化: 用来在训练中动态地、有区分地控制模型的“探索欲”。
2. 动态最优长度惩罚: 用来确保模型在探索难题时,也不会无限制地写长文,而是朝着“历史上最短的正确解”去优化。
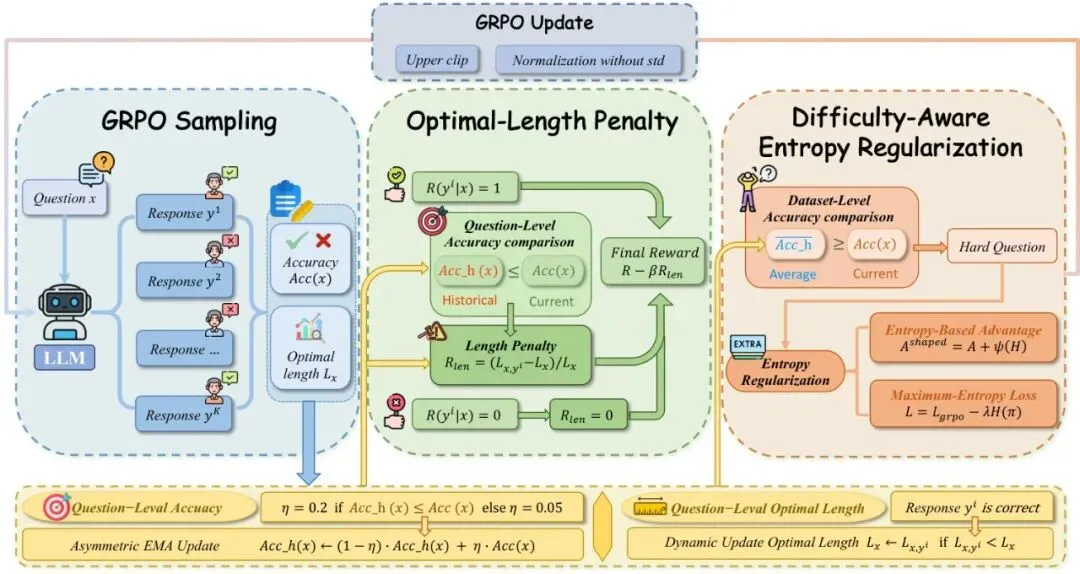
两者协同工作,才能达成“又快又准”的目标。下面的流程图清晰地展示了这个协作过程:
图2:CEEH方法流程图。模型精度通过GRPO进行评估,最优长度从历史正确回答中获取。长度惩罚仅在当前精度超过历史精度时应用于正确回答,而熵正则化则用于那些精度低于平均水平的题目以鼓励探索。
两大法宝:难度感知熵正则化与动态长度惩罚
CEEH需要一个稳定的信号来实时判断每道题对当前模型来说难不难。它采用了一个巧妙的非对称指数移动平均方法来跟踪每道题的“历史正确率”。
在每一步训练中,模型会对每个问题采样生成K个答案,计算一个瞬时正确率 Acc(x)。然后用这个值去更新该问题的历史正确率 Acc_h(x)。“非对称”体现在:如果当前正确率高于历史值(说明模型有进步),就用一个较大的更新率(0.2)快速提升历史记录;如果低于或等于历史值,就用一个较小的更新率(0.05)缓慢下调。这样能平滑噪声,得到一个稳定的难度判断。
判断规则很简单:如果某道题的历史正确率 低于所有题目的平均历史正确率,那它就被标记为当前的“难题”,反之则是“易题”。这个阈值是动态全局平均,会随着模型整体能力提升而水涨船高。
1. 最大熵损失:在训练目标中直接添加一项鼓励熵最大化的损失。并且对难题,这项损失的系数是易题的5倍,强力维持其探索空间。
2. 基于熵的优势函数:在计算强化学习的“优势”时,给那些生成高熵(多样性高)token的行为额外加分,但仅对难题生效。
熵正则化被减弱或取消,让模型可以“自信地”利用已经找到的高效短路径,放心压缩。
鼓励探索(尤其是对难题)有个副作用:模型可能会生成更长的推理步骤。如果不加控制,就会背离“压缩”的初衷。
CEEH的第二个法宝——动态最优长度惩罚——就是来解决这个矛盾的。它非常精明:
1. 只惩罚“正确”答案的长度。 错误的答案本身就没奖励,再惩罚长度意义不大。我们只关心正确的答案能不能写得更短。
2. 惩罚的基准是“历史上最短的正确长度”。 对于每道题,模型会记住它曾经给出的最短的正确回答长度 L_x。如果新生成的正确答案比这个历史记录长,就会受到惩罚;如果更短,则更新这个记录。这就像一个不断被刷新的“最短正确解题记录榜”。
3. 惩罚强度与进步挂钩。 只有当模型在当前题目上的瞬时正确率超过其历史正确率时(即“有进步”时),才施加长度惩罚。这符合直觉:当你终于能做对一道难题时,才是教你如何把它做得更简洁的好时机。
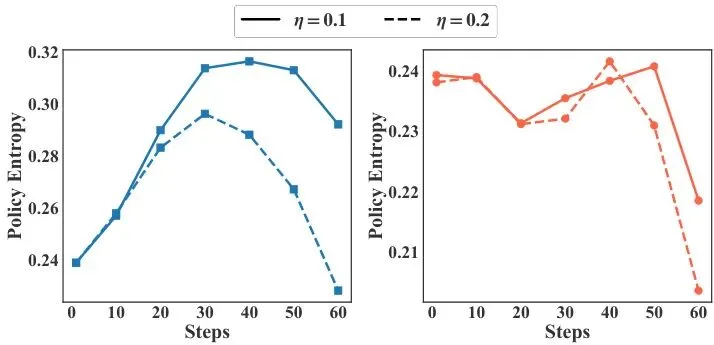
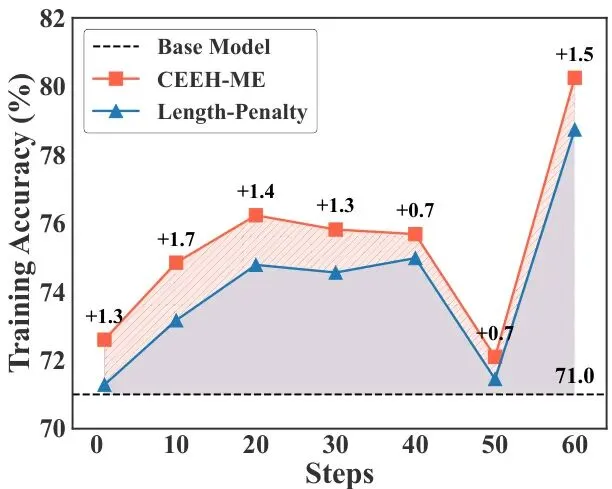
通过这两大法宝的配合,CEEH让模型在训练中始终保持着一种健康的节奏:对难题充分思考以保正确率,同时对任何题都精益求精地压缩长度。从下面这张训练熵动态图可以看到,CEEH方法(右侧两个子图)成功防止了纯长度惩罚(左侧)导致的熵崩塌,维持了更高的探索水平。
图3:在不同长度惩罚系数下,R1-Distill-Qwen2.5-7B的策略熵训练动态。(左:最大熵损失-CEEH-ME;右:基于熵的优势-CEEH-EA)。
实验验证:更短、更准、更强
理论说得再好,还得看实战。论文在GSM8K、MATH500、AIME、AMC、OlympiadBench等六个具有不同难度的数学推理基准上进行了全面测试,对比了包括提示工程、离线蒸馏、在线强化学习在内的多种前沿压缩方法。
为了综合衡量“效率提升”和“精度保持”,论文引入了一个新指标:归一化精度增益。其思想是,看你为了缩短单位长度的回复,牺牲了多少精度。NAG值越低越好,负数则表示在压缩的同时精度还有提升。
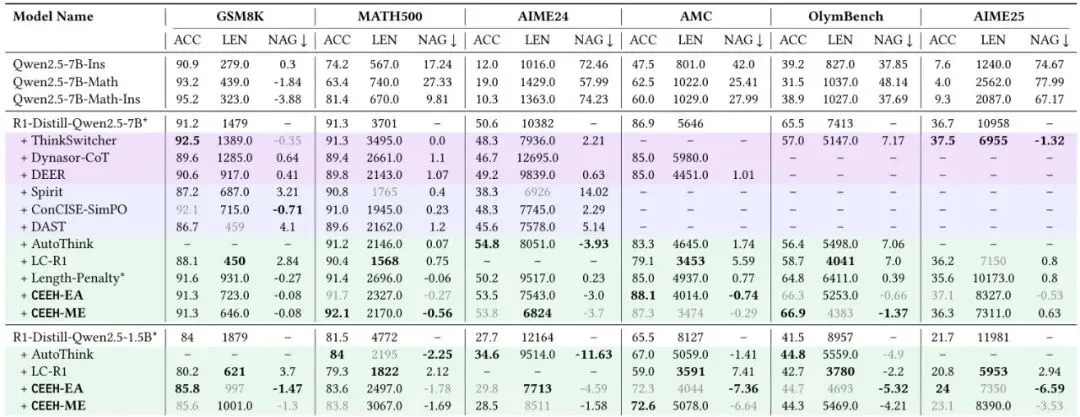
表1:在多个数学基准上的性能对比。粗体表示每个指标的最佳得分,灰色精度表示第二佳得分。
非常震撼!聚焦最后几行CEEH的结果(基于R1-Distill-Qwen2.5-7B模型):
1. 全面大幅压缩: 在几乎所有数据集上,CEEH-EA和CEEH-ME都将回复长度压缩到了基线模型的30%-50%左右。例如在GSM8K上,从基线的1479个token压缩到了646-723个token。
2. 精度保持甚至提升: 更厉害的是,在如此大幅的压缩下,CEEH方法的正确率(ACC)与强大的基线模型相比几乎持平,在多个数据集上甚至取得了第一或第二的最佳精度(如MATH500、AIME24、AMC、OlymBench)。这直接体现了“按难度探索”策略的成功——它保护了解决难题的能力。
3. 优异的权衡指标: 看NAG列,CEEH方法在很多数据集上都取得了负值,这意味着它们在缩短回答的同时,精度非但没有损失,反而有所提升!而其他许多方法(如DAST、LC-R1、Spirit)的NAG是较大的正值,表明它们用精度换取了长度。
此外,论文还评估了Pass@k指标(即采样k次,至少有一次答对的概率),这更能反映模型的“潜力”和探索能力。如表2所示,CEEH方法成功维持甚至提升了基线的Pass@k性能,而纯长度惩罚方法则在一些数据集上出现了下降。这进一步证实了维持熵(探索性)对于模型解决难题潜力的重要性。
表2:从R1-Distill-Qwen2.5-7B训练的不同方法的Pass@k性能。Pass@k使用每个问题16次采样计算。
从训练曲线也能直观感受到CEEH的优势。图4显示,在同样的训练数据上,CEEH方法(特别是CEEH-ME)能够达到比纯长度惩罚方法更高且更稳定的正确率。
图4:在同一数据集上的训练精度,以R1-Distill-Qwen2.5-7B为基础模型。
方法启示:平衡探索与利用的艺术
CEEH的成功,不仅仅在于它提出了一种有效的推理压缩技术,更在于它为我们提供了一个精巧的范式,来解决AI训练中一个永恒的主题:探索与利用的平衡。
在追求单一目标(如长度最短)时,模型很容易陷入局部最优,过早地“利用”一个看似高效的捷径,却丧失了“探索”更优、更鲁棒解的能力。CEEH通过引入“难度”这个维度,将一刀切的优化转变为自适应、精细化的调控。
这种思想可以迁移到很多需要权衡“效率”与“效果”的场景。例如,在代码生成中,是否可以对简单函数要求极简实现,而对复杂算法允许更多的注释和调试语句?在对话系统中,是否可以对常见问题给出简洁回复,而对陌生复杂问题允许模型进行更长的内部“思考”?
CEEH告诉我们,智能的本质或许不在于永远长篇大论,也不在于永远言简意赅,而在于知道什么时候该多思,什么时候该速决。龙迷三问
文中提到的RLVR和GRPO是什么意思?RLVR全称是Reinforcement Learning with Verifiable Rewards(带可验证奖励的强化学习)。这是一种特别适合数学、代码生成等有明确对错答案任务的RL设定。模型生成答案后,通过与标准答案比对直接获得奖励(对=1,错=0),信号清晰。GRPO全称是Group Relative Policy Optimization(组相对策略优化),是RLVR中一种高效且无需额外价值函数网络的优化算法。它通过在一次性采样的一“组”输出内部进行奖励归一化来计算相对优势,大大降低了训练开销。
“熵”在这个上下文中具体指什么?为什么它重要?在这里,“熵”特指策略熵,量化了语言模型在生成下一个词时概率分布的混乱程度。如果模型总是以接近1的概率输出某个词,熵就很低,意味着它的行为很确定、很“固执”。高熵则意味着模型在多种可能的词之间犹豫,行为更多样、更具探索性。在推理任务中,保持一定的熵对于尝试不同的解题步骤、进行自我纠错至关重要。纯长度惩罚会无情地降低熵,让模型变得“思维僵化”,从而损害解决复杂问题的能力。
动态长度惩罚为什么只惩罚“正确”答案的长度?这是一个非常巧妙的设计。主要基于两点:1. 训练效率: 错误的答案本身就没有奖励(奖励为0),如果再施加一个负的长度惩罚,会使得这个样本的总奖励非常低,可能对梯度更新产生过大影响,且其主要问题在于“错误”而非“长短”。2. 目标清晰: 压缩的终极目标是“用更短的文字得到正确答案”。因此,我们只关注那些已经得到正确答案的路径,看它们能不能进一步精简。对于错误答案,首要任务是让其变正确,而不是变短。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
核心创新在于将“难度感知”这一概念与熵正则化结合,用于解决推理压缩中的探索-利用困境。思路清晰巧妙,不是简单的技术堆砌,而是有深刻的洞察。但在熵调控的具体技术上,借鉴了前人的方法(最大熵损失和熵优势)。实验合理度:★★★★☆
实验设计全面,在六个不同难度的数学基准上进行测试,对比方法涵盖了主流三类技术(提示、离线、在线)。消融实验和动态分析(如熵、长度变化曲线)充分,增强了结果的可信度。但部分基线方法在某些数据集上的结果缺失,稍显遗憾。学术研究价值:★★★★☆
价值较高。不仅提出了一个有效的压缩方法,更重要的是为如何在大模型RL训练中精细平衡多目标(精度、长度)提供了一个可借鉴的“难度感知”框架。对“熵崩塌导致性能下降”的分析也加深了社区对RL训练大模型机理的理解。稳定性:★★★☆☆
方法依赖于在线RL训练,其稳定性受超参(如长度惩罚系数β、熵正则化系数λ0)影响。尽管论文通过动态设计(如动态最优长度)部分缓解了这一问题,但在新任务上应用可能仍需一定的调参。适应性以及泛化能力:★★★☆☆
目前仅在数学推理领域验证,且需要问题有明确对错答案(适用于RLVR设定)。对于开放式生成、创意写作等没有唯一标准答案的任务,其难度评估和奖励设计可能需要调整,泛化能力有待进一步验证。硬件需求及成本:★★☆☆☆
需要在线强化学习训练,涉及多轮采样、评估和模型更新,计算成本和时间成本远高于推理或简单的微调。虽然GRPO减少了部分开销,但训练阶段仍然需要可观的算力。复现难度:★★★☆☆
论文方法描述较为详细,但实现涉及RL训练框架、非对称EMA更新、动态记录管理等多个细节。如果作者后续能开源代码,复现难度将大大降低,目前仅凭论文复现有一定挑战。产品化成熟度:★★☆☆☆
主要作为模型训练阶段的优化技术。训练完成后,得到的模型可以直接用于推理,此时无额外成本。因此,其产品化价值体现在为云服务厂商或需要高频调用大模型的企业训练一个“节能”版模型上。直接拿来作为终端用户产品功能不成熟。可能的问题:实验主要集中在数学推理,对其他复杂推理任务(如科学问答、逻辑谜题)的泛化性未充分证明。动态难度评估依赖于历史正确率,在训练初期或数据分布变化时可能不够准确。“最优长度”的追求是否可能导致对某些题目的“过度压缩”,牺牲可解释性?[1] Luo, Qin-Wen, et al. “Compress the Easy, Explore the Hard: Difficulty-Aware Entropy Regularization for Efficient LLM Reasoning.” arXiv preprint arXiv:2602.22642 (2026).原文链接:https://arxiv.org/pdf/2602.22642v1.pdf*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想让你的大模型推理也学会“看题下菜”,实现又快又准吗?快来加入龙哥读论文粉丝群,和志同道合的小伙伴一起探讨前沿技术!
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 大模型推理+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
