🐉 龙哥读论文知识星球来了!还在为图像去雾、去噪、去模糊、提亮要换不同模型而烦恼?星球为你精选前沿全能修复方案,每日拆解AI图像处理最新论文、开源代码、实战技巧,让你一个模型在手,天下图像我有!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
图像修复领域一直有个老大难问题:一个模型很难同时处理好雾霾、运动模糊、噪声、低光照等多种退化。传统方法要么“专精一门”,要么“样样稀松”。这篇来自南京理工大学等高校的论文,巧妙地将“专家混合”与强大的扩散Transformer结合,提出了一个层次化动态路由的“全能医生”模型。它不仅思路清晰,架构新颖,而且在多个公开数据集上取得了领先的视觉效果和指标,是近期图像修复领域一个非常扎实且有启发性的工作,值得深入解读。
原论文信息如下:
论文标题:
MiM-DiT: MoE in MoE with Diffusion Transformers for All-in-One Image Restoration
发表日期:
2026年03月
发表单位:
南京理工大学, 南开大学, 哈尔滨工业大学
原文链接:
https://arxiv.org/pdf/2603.02710v1.pdf
全能图像修复新范式:当MoE遇见扩散Transformer
想象一下,你有一张完美的照片,但不幸被加上了雾霾、运动模糊、噪点和低光照这“四重debuff”。现在的AI修复工具,大多像专科医生:去雾的只管去雾,去噪的只管去噪。你想恢复这张照片,得跑四个不同的模型,不仅麻烦,效果还可能互相打架。
那有没有一个“全能医生”,能根据病情(退化类型)自动开药(选择修复策略)呢?这就是全能图像恢复(All-in-one Image Restoration)的终极目标。这个目标之所以难,是因为不同的退化对模型的要求可能是矛盾的。比如去雾需要理解整个场景的全局大气光,而去运动模糊则需要恢复锐利的局部边缘。一个模型很难同时兼顾这两套思维模式。
传统的思路主要有两种:一种是训练多个专精模型(费时费力),另一种是用一个“万金油”模型处理所有问题(效果平平)。近年来,两个技术路径崭露头角:专家混合(Mixture of Experts, MoE)和扩散模型(Diffusion Models)。
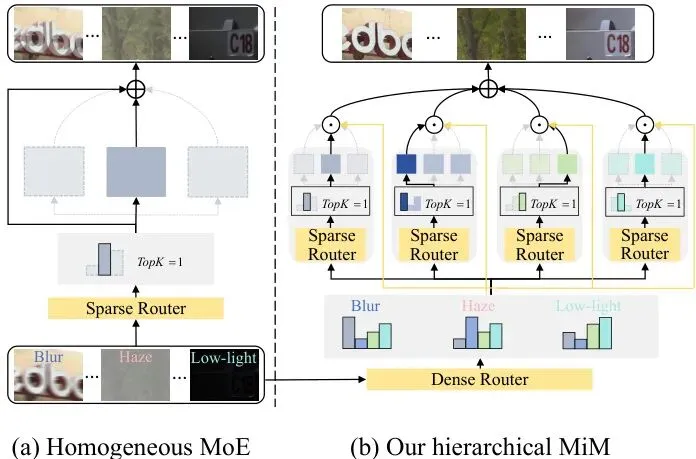
图1:传统同质MoE vs. 本文提出的MiM架构。图中符号与本方法定义一致。我们的层次化MiM采用两级路由机制,通过将输入路由到合适的架构先验和细粒度专家,确保动态且专业的处理。与传统同质MoE相比,我们的方法通过自适应结构选择,在去模糊、去雾和低光增强任务上实现了更好的修复效果。
MoE就像是一个专家会诊团:模型里内置多个“专家”子网络,每来一张“病患”图片,就由一个“路由网络”判断该请哪几位专家出手。这实现了动态计算,但它有个毛病:基于确定性的回归损失进行训练,修复结果容易过于平滑,丢失纹理细节。
扩散模型则像一个想象力丰富的画家:它从纯噪声开始,一步步“画”出清晰的图像,这个过程天生具有强大的生成先验,能补全缺失的细节和纹理,效果惊艳。但它在全能修复上显得有点“一根筋”:对所有退化类型都采用几乎一样的“绘画”流程,忽略了雾霾、模糊、噪声本质上的巨大差异,导致处理不当会产生结构扭曲或伪影。
于是,一个自然的想法诞生了:能不能把MoE的“动态分诊”能力和扩散模型的“超凡画功”结合起来?这篇论文告诉你:能,而且结合的方式比你想象的更巧妙。
本文提出的MiM-DiT模型,核心思想可以概括为:在一个预训练好的强大扩散Transformer(DiT)画家体内,植入一个高度智能的、分两级的“专家调度中枢”(Hierarchical MoE in MoE)。这个调度中枢会先对输入的退化图片进行“深度体检”,然后动态地组合不同“思维模式”的专家,共同为画家生成一份精准的“修复指导手册”,告诉画家在画画的不同阶段,该重点注意什么(比如这里是全局色彩,那里是局部边缘)。这样,画家就能在保持自身高超画技的同时,有的放矢地解决特定退化问题。
揭秘MiM-DiT:两级路由如何动态适配多种退化
MiM-DiT这个名字,MiM代表“MoE in MoE”,DiT代表“Diffusion Transformer”。它的整体架构如下图所示:
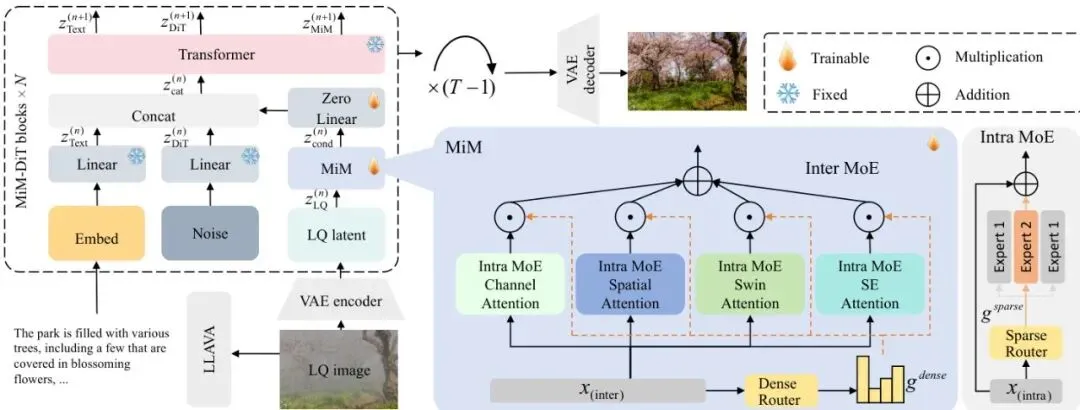
图2:集成到DiT骨干网络中的层次化MoE in MoE (MiM) 框架概览。该框架通过一系列MiM-DiT块处理低质量(LQ)图像。给定LQ输入,MiM模块提取退化特征,并通过一个由Inter-MoE和Intra-MoE两层组成的层次化MoE架构进行处理。在Inter-MoE层,基于四种不同注意力机制(空间自注意力、通道自注意力、Swin注意力和SE注意力)的专家组,通过一个密集路由器进行组合,该路由器计算所有专家组的自适应权重。这种密集融合使模型能够利用互补的归纳偏置。在每个专家组内部,Intra-MoE通过稀疏路由捕捉每个退化类别内的细粒度变化。这些处理后的特征通过零初始化线性层,作为条件输入注入到DiT骨干网络中,动态引导扩散过程生成修复结果。
简单来说,流程就是:低质图片→VAE编码到潜空间→进入一系列MiM-DiT块→最后VAE解码得到高清图。核心创新在于每个MiM-DiT块中的MiM模块,它就像一个两级调度中枢。
面对一张退化图片,MiM首先要判断它主要属于哪一类“大病科”(比如是雾霾、模糊还是噪声)。为了实现这一点,它没有使用功能雷同的专家,而是精心设计了四个结构迥异的“专家组”,每个组代表一种不同的“视觉理解思维模式”:1. 空间自注意力专家:擅长捕捉图像中相隔很远的区域之间的关系(长程依赖)。这对于理解整个场景的构图和去雾很有帮助。2. 通道自注意力专家:专注于分析不同颜色通道(如红、绿、蓝)之间的关联。对于处理颜色失真和进行色彩校正非常关键。3. Swin注意力专家:一种高效的局部-全局注意力,在划定的窗口内进行精细计算,平衡了细节恢复和计算效率。擅长恢复清晰的边缘和纹理,对去模糊和去噪有益。4. SE注意力专家:全称是Squeeze-and-Excitation注意力,非常擅长对通道特征进行全局的重新校准和加权。对于建模全局光照变化(如低光增强)和抑制不重要的噪声通道很有效。
这四个专家组会同时对输入特征进行处理。然后,一个密集路由器(Dense Router)会根据输入图片的特征,计算出每个专家组输出的重要性权重,并将它们加权融合。这就像是医院会诊,内科、外科、影像科的主任同时看片,然后根据病情共同给出一份综合诊断意见。
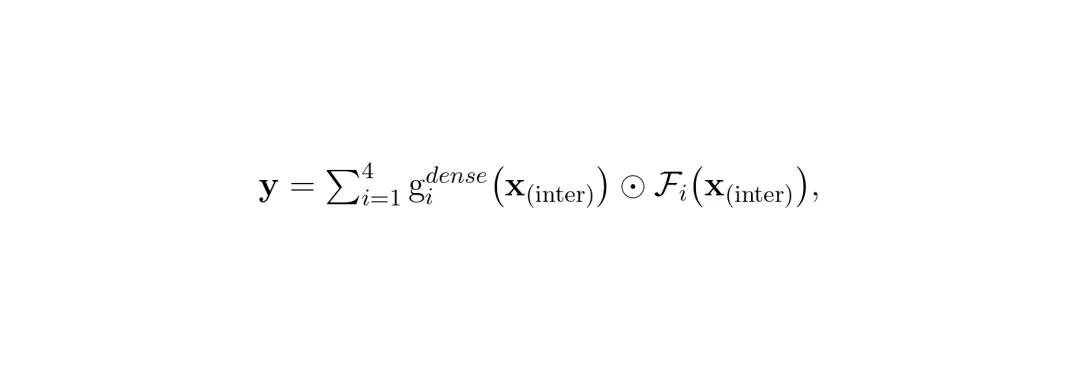 公式:Inter-MoE层输出 y = Σi=1 to 4 (gidense(xinter) ⊙ Fi(xinter))。其中 Fi 是第 i 个专家组的输出,gidense 是密集路由器为第 i 组预测的自适应融合权重,⊙ 表示逐元素相乘。
确定了“大病科”之后,病情还有轻重缓急呢!同样是雾霾,有薄雾和浓雾之分;同样是运动模糊,有轻微抖动和剧烈拖影之别。Inter-MoE的每个“专家组”内部,还嵌套着一个Intra-MoE层。
这个Intra-MoE层包含多个“子专家”。同一个专家组内的所有子专家,结构相同(比如都是Swin注意力),但参数独立训练,从而各自擅长处理该退化类型下的某种特定“亚型”。对于一个输入,Intra-MoE层的稀疏路由器(Sparse Router)会进行Top-K选择,只激活最相关的少数几个子专家,既保证了专业性,又控制了计算量。这就像是确定了去呼吸内科后,再根据CT片决定是请擅长肺炎的专家,还是擅长尘肺的专家来主导治疗。
公式:Inter-MoE层输出 y = Σi=1 to 4 (gidense(xinter) ⊙ Fi(xinter))。其中 Fi 是第 i 个专家组的输出,gidense 是密集路由器为第 i 组预测的自适应融合权重,⊙ 表示逐元素相乘。
确定了“大病科”之后,病情还有轻重缓急呢!同样是雾霾,有薄雾和浓雾之分;同样是运动模糊,有轻微抖动和剧烈拖影之别。Inter-MoE的每个“专家组”内部,还嵌套着一个Intra-MoE层。
这个Intra-MoE层包含多个“子专家”。同一个专家组内的所有子专家,结构相同(比如都是Swin注意力),但参数独立训练,从而各自擅长处理该退化类型下的某种特定“亚型”。对于一个输入,Intra-MoE层的稀疏路由器(Sparse Router)会进行Top-K选择,只激活最相关的少数几个子专家,既保证了专业性,又控制了计算量。这就像是确定了去呼吸内科后,再根据CT片决定是请擅长肺炎的专家,还是擅长尘肺的专家来主导治疗。
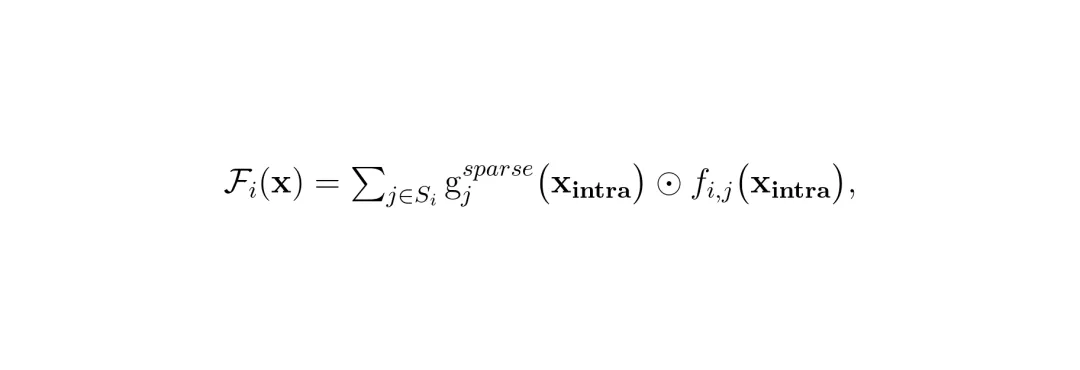 公式:专家组 Fi 的输出 = Σj∈Si (gjsparse(xintra) ⊙ fi,j(xintra))。其中 fi,j 是第 i 组内的第 j 个子专家,Si 是被稀疏路由器选中的子专家集合,gjsparse 是对应子专家的路由权重。
经过两级专家会诊,MiM模块产生了一个富含退化特异性信息的特征。这个特征如何用来指导预训练的扩散Transformer(DiT)呢?方法很巧妙:通过一个零初始化的线性层(Zero-Linear),将这个条件特征注入到DiT的注意力模块中。
“零初始化”是个关键技巧。在训练刚开始时,这个线性层的权重为零,意味着条件信号对DiT没有任何影响,DiT完全依靠自己强大的预训练先验工作。随着训练进行,这个线性层和MiM模块一起被微调,逐渐学会如何将“修复指导手册”(条件特征)有效地传递给DiT,引导它向正确的方向生成。这种设计保证了训练初期的稳定性,避免一开始就破坏了DiT宝贵的生成能力。
公式:专家组 Fi 的输出 = Σj∈Si (gjsparse(xintra) ⊙ fi,j(xintra))。其中 fi,j 是第 i 组内的第 j 个子专家,Si 是被稀疏路由器选中的子专家集合,gjsparse 是对应子专家的路由权重。
经过两级专家会诊,MiM模块产生了一个富含退化特异性信息的特征。这个特征如何用来指导预训练的扩散Transformer(DiT)呢?方法很巧妙:通过一个零初始化的线性层(Zero-Linear),将这个条件特征注入到DiT的注意力模块中。
“零初始化”是个关键技巧。在训练刚开始时,这个线性层的权重为零,意味着条件信号对DiT没有任何影响,DiT完全依靠自己强大的预训练先验工作。随着训练进行,这个线性层和MiM模块一起被微调,逐渐学会如何将“修复指导手册”(条件特征)有效地传递给DiT,引导它向正确的方向生成。这种设计保证了训练初期的稳定性,避免一开始就破坏了DiT宝贵的生成能力。
实验验证:多项指标领先,视觉结果惊艳
这么精巧的设计,实际效果如何?本文在多个全能图像修复基准上进行了测试,主要是在FoundIR数据集(一个覆盖去模糊、去噪、去雾、去雨、低光增强等多种退化的高清数据集)上,与众多前沿方法进行对比。
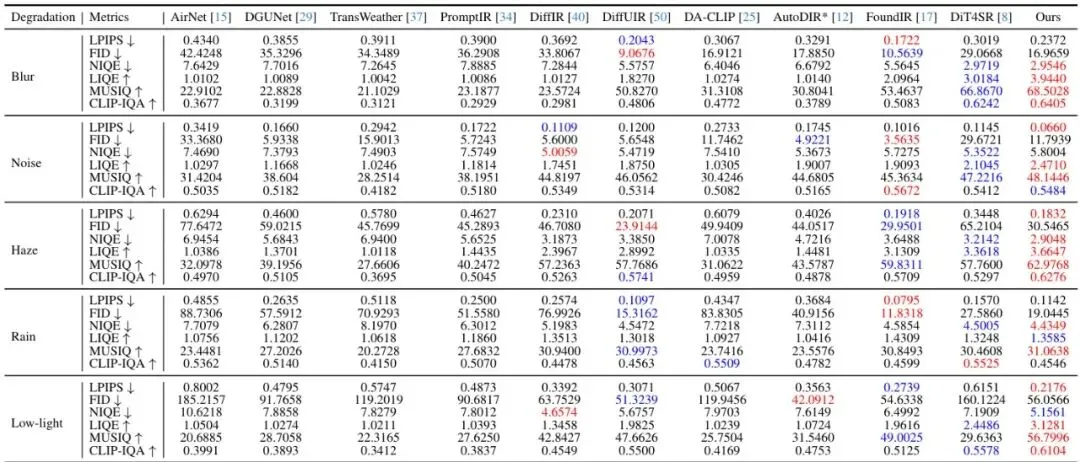
表1:在FoundIR基准上,本文方法与前沿方法的量化评估对比。带星号(*)的模型使用官方发布的预训练权重评估,其余在相同数据集上按照FoundIR方案重新训练以进行公平比较。最佳和第二佳性能分别用红色和蓝色标记。
表格有点长,但结论很清晰:MiM-DiT在绝大多数退化类型和评价指标上都取得了最佳或接近最佳的性能。它不仅在传统的像素级指标(如LPIPS↓, FID↓)上表现出色,在更侧重人类感知的质量指标上(如NIQE↓, MUSIQ↑, CLIP-IQA↑)优势更加明显。这证明了它结合扩散模型生成先验的优势——修复结果不仅数值上接近真值,视觉上更加自然、清晰、富有细节。
图3:在FoundIR数据集上的去模糊结果对比。(c)-(g)中的去模糊结果仍包含明显的模糊效应。相比之下,本文方法生成了清晰的结果。
图4:在FoundIR数据集上的去雾结果对比。(c)到(g)的结果未能完全恢复原始场景内容。相比之下,本文方法生成了清晰且忠实于原始场景的重建结果。
图5:在FoundIR数据集上的低光增强结果对比。(c)到(g)的结果存在色偏和细节涂抹。相比之下,本文方法恢复了准确的颜色和精细的结构。
视觉对比是最有说服力的。无论是去除复杂的运动模糊、还原雾霾后的清晰远景,还是提升昏暗环境下的画面亮度和细节,MiM-DiT都展现出了卓越的恢复能力。它的结果色彩自然,纹理清晰,边缘锐利,且很少引入奇怪的伪影,明显优于其他对比方法。
深入分析:消融实验揭示核心组件价值
一个好的研究,不仅要效果好,还要能证明为什么好。本文通过一系列消融实验,系统地验证了每个核心组件的必要性。
表3:关于Intra-MoE模块有效性的消融实验,比较了在FoundIR数据集上包含和不包含Intra-MoE的性能。包含Intra-MoE的变体在所有指标上都取得了更好的结果,验证了Intra-MoE的重要性。
首先验证Intra-MoE。去掉它(即每个专家组内部只有一个专家,没有细粒度路由),模型在所有退化任务上的性能全面下降。这证明了处理同类退化内部差异性的重要性。从视觉上看,没有Intra-MoE的结果清晰度和细节更差。
图6:Intra-MoE的效果。包含Intra-MoE的模型产生了更锐利、更清晰的结果。
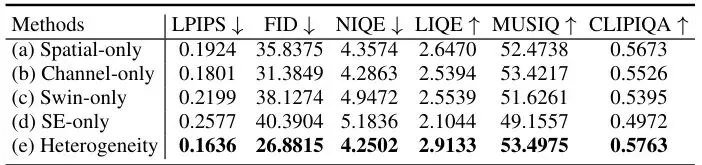
表4:关于Inter-MoE中结构异质性的消融实验。在FoundIR数据集上,异质的Inter-MoE(融合所有四种注意力类型)在所有指标上都优于单一结构的变体,证明了组合多种注意力机制对于全能修复至关重要。
其次是Inter-MoE的结构异质性。如果只使用单一类型的注意力(比如全用Swin注意力)来构建四个专家组,效果显著变差。这强有力地支持了论文的核心论点:不同的退化类型需要不同的网络架构偏好(归纳偏置),而动态融合多种异构专家是解决这一冲突的关键。
表5:路由器设计的消融研究。在FoundIR数据集上,“密集Inter-MoE + 稀疏Intra-MoE”的组合优于其他配置。
第三是路由器的设计。实验对比了不同层使用稀疏或密集路由的组合。结果表明,在Inter层使用密集路由(所有专家组都参与,但权重不同)以充分融合不同结构信息,在Intra层使用稀疏路由(只激活少数子专家)以提高效率和专业化,这样的组合是最优的。
最后,论文还分析了路由器在不同退化类型上的自适应权重。结果显示,对于去模糊任务,模型更依赖于擅长局部细节的Swin注意力;对于去雾和低光增强,擅长全局通道建模的SE注意力权重更高;而对于需要理解整体结构的任务,空间自注意力则扮演了更重要的角色。这直观地证明了MiM-DiT确实学会了根据输入“病情”动态调配“专家资源”。
总结与展望:层次化动态计算是未来方向吗?
总结一下,MiM-DiT这篇工作为全能图像修复提供了一个非常优雅且有效的解决方案。它的核心贡献在于提出了一个层次化的MoE-in-MoE架构,并将其与强大的预训练扩散模型无缝集成。
它的成功启示我们:在处理复杂、多变的现实世界问题时,“静态统一”的模型可能已经接近天花板。未来的模型可能需要具备更高级的“智能”——不仅能学习数据中的模式,还能根据具体输入,动态地组织和调用自身内部不同功能、不同架构的模块。这其实就是“条件计算”或“动态网络”思想的深化。
展望未来,这种层次化动态计算的思路可以扩展到更多领域:视频修复、多模态理解、甚至自动驾驶的感知系统,任何需要处理多种不同子任务或复杂输入变化的场景,都可能从中受益。当然,目前这类方法也面临着计算复杂度、训练稳定性以及如何设计更有效的路由机制等挑战。
龙迷三问
这篇论文解决的是什么核心问题?核心是解决“全能图像恢复”中一个模型难以同时高质量处理多种性质迥异的退化(如雾霾、模糊、噪声、低光)的问题。传统统一模型往往效果平庸,而本文通过动态路由融合不同架构的专家,并利用扩散模型的生成能力,实现了对不同退化的自适应、高质量修复。
文章中的MoE和DiT分别是什么?MoE(Mixture of Experts, 专家混合)是一种模型架构,它包含多个“专家”子网络,并通过一个“路由器”根据输入动态选择激活哪些专家,实现条件计算。DiT(Diffusion Transformer)是基于Transformer架构构建的扩散模型,是当前最强的生成模型之一。本文的创新点就是将层次化的MoE作为条件信号生成器,嵌入到预训练的DiT中,指导其进行针对性修复。
文中提到的几种注意力机制有什么区别?这是Inter-MoE设计的关键:1) 空间自注意力:计算所有像素点之间的关联,擅长捕获长程依赖和全局结构。2) 通道自注意力:计算不同特征通道(如颜色通道或抽象特征通道)之间的关联,擅长特征重新校准和色彩处理。3) Swin注意力:在局部窗口内计算注意力,再通过窗口移动建立窗口间联系,平衡了局部细节和全局上下文,效率高。4) SE注意力:对每个通道特征进行全局池化后,通过一个小型网络学习每个通道的重要性权重,擅长全局通道建模,对光照、对比度调整有效。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将两级MoE(结构异质的Inter-MoE和参数异质的Intra-MoE)与预训练扩散DiT相结合,思路清晰且有层次感,在动态网络设计上迈出了一步。实验合理度:★★★★☆
在主流全能修复基准上进行了充分对比,消融实验设计全面,从模块有效性、结构异质性、路由器设计等多个角度验证了核心设计,结论可信。学术研究价值:★★★★☆
为“一个模型处理多种任务”这一经典难题提供了新的解决方案范式(层次化条件计算+大模型先验),对图像处理乃至其他领域的动态网络研究有启发意义。稳定性:★★★☆☆
基于扩散模型的方法在生成质量上具有优势,但其采样过程的随机性可能带来结果的不完全确定性,在某些极端退化或对确定性要求极高的场景下可能存在稳定性挑战。适应性以及泛化能力:★★★★☆
论文验证了在多种已知退化类型上的强大适应能力。其框架设计原则(动态适配)具备良好的泛化潜力,但面对训练数据中未出现过的、全新的混合退化类型时,效果有待验证。硬件需求及成本:★★☆☆☆
需要加载预训练的Stable Diffusion 3.5(DiT)大模型,推理时需要多步采样,并运行复杂的MoE路由和多个专家前向传播,计算量和显存需求都非常大,距离实时或端侧部署有相当距离。复现难度:★★★☆☆
方法本身描述清晰,但复现需要具备预训练的SD3.5 DiT模型权重、大规模全能修复数据集(如FoundIR)以及较强的算力支持进行微调,对个人研究者有一定门槛。产品化成熟度:★★☆☆☆
目前主要作为一项前沿学术研究,展示了高质量全能修复的可能性。受限于计算成本、推理速度以及扩散模型固有的随机性,距离成熟、稳定、高效的商业化产品落地还有较长的路要走,更适合云服务场景。可能的问题:本文是一篇扎实且富有启发性的工作,主要短板在于其巨大的计算开销限制了实用性。未来研究可探索更轻量的专家设计、更高效的路由机制,或探索知识蒸馏将其能力迁移至小模型。[1] Lingshun Kong, et al. "MiM-DiT: MoE in MoE with Diffusion Transformers for All-in-One Image Restoration." arXiv preprint arXiv:2603.02710 (本论文).[17] Chen, et al. "FoundIR: A Foundational All-in-One Image Restoration Model." CVPR 2024.[33] Peebles, W., & Xie, S. "Scalable Diffusion Models with Transformers." ICCV 2023.*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

想让你的照片一键“去雾”、“去噪”、“提亮”?想了解AI如何像专家会诊一样处理复杂图像问题?欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 图像处理+上海+清华+龙哥),根据格式备注,可更快被通过且邀请进群。