南京邮电大学韩斌:一种双编码器自适应特征融合的SAR图像水体分割网络 |《测绘学报》2026年55卷第1期
- 2026-06-07 10:33:56

摘要
摘要
关键词
关键词
基金项目
作者简介
作者简介
韩斌(1990—),男,博士,副教授,研究方向为遥感图像处理。E-mail:njupt.bh@foxmail.com
本文引用格式
阅读全文
阅读全文
利用遥感影像进行水体分割有助于自动提取地表水体信息,在生态环境监测、水资源管理与灾害应对中发挥着关键作用[1-2]。合成孔径雷达(synthetic aperture radar,SAR)成像具备全天候、全天时观测能力,尤其适用于多云、多雨及夜晚等复杂气象条件下的水体检测。水体与陆地在电磁波反射特性上区别较大,两者在SAR图像像素层面表现出明显的差异性。然而,SAR水体检测仍面临多方面挑战。首先,复杂背景下的SAR图像灰度变化较大,地表目标多样化,增加了误检和漏检的可能性。如,湿地、沼泽或植被覆盖区域的反向散射模式可能与水体相似,导致误分类;地形或建筑物投射的阴影区域通常表现为低反向散射,也容易被误认为水体。其次,地形变化和成像噪声会造成水体边界模糊、预测结果支离破碎或河流结构断裂,从而降低分割精度。此外,传统方法通常依赖局部特征,难以将局部细节与全局上下文信息有效结合,这进一步限制了检测精度。综上所述,在复杂背景下实现精确、连续的水体分割仍然是一项极具挑战性的任务。
现有SAR水体分割方法主要分为无监督与监督两类。无监督方法如阈值分割、聚类和边缘检测等在简单场景下表现良好,但缺乏深层语义信息的建模能力,在处理复杂背景图像时性能有限。监督方法引入人工标注样本与特征提取机制,提升了模型的表征能力。文献[3]提出了基于模糊逻辑的洪水映射算法;文献[4]融合极化分解特征与朴素贝叶斯分类器;文献[5]结合外部辅助数据库与CRF(conditional random fields)细化水体边界。尽管上述方法在水体分割精度上有所提升,但仍依赖人工选择特征,难以全面建模SAR图像的非线性特征。
随着深度学习的发展,卷积神经网络(convolutional neural networks,CNN)在SAR图像水体分割中得到广泛应用,而编码器-解码器结构是其中的重要框架结构之一。EDWNet[6]是一种对称的编码器-解码器结构,结合边界增强模块,有效提升了水体边缘的提取质量;MADF-Net[7]引入密集特征融合模块,有效整合语义与边缘信息,增强了网络的表达能力与分割精度;SCR-Net[8]构建双通道编码器,通过光谱信息增强网络对不同波段水体特征的提取能力;FFEDN[9]通过SAR图像中的极化特征和散射特征来提取水体结构,提升水体整体检测精度;SDNet[10]提出了分层三明治型解码器,逐步细化目标边界与结构,在小尺度水体分割方面表现优异;FWENet[11]提出多尺度解码器,融合空洞卷积与残差结构,在复杂场景下进一步提升了模型的泛化能力。此外,注意力机制也被利用来进一步提升模型的性能。UAVSeg[12]提出双编码器跨尺度注意力网络,将扫描聚焦窗口Transformer嵌入CNN并结合跨尺度轻量级融合与线性多层感知机,在降低计算量的同时实现多尺度特征细粒度融合与高分辨率恢复。STRD-Net[13]采用Swin Transformer与ResNet50并行双编码器,在Transformer分支引入卷积块注意力和新Patch合并模块强化局部特征,在CNN分支增加增强空洞空间金字塔池化扩大感受野并用单一跳跃连接平衡精度与效率。DE-Unet[14]在U-Net对称框架中引入双CNN编码器,通过多路径跳跃连接和上下文感知调制融合模块引导编码器间及编码器-解码器间数据融合,从而提升超高分辨率遥感影像分割性能。DSHNet[15]设计双流混合网络,语义流采用预训练视觉Transformer骨干提取全局语义特征,边界流使用Sobel算子捕获局部边界信息,通过边界增强机制融合双流特征,实现了在复杂背景下水体分割的精细化和完整性提升。WaterFormer[16]融合CNN与Transformer结构,借助自注意力机制在保持空间分辨率的同时增强全局上下文理解;LEFormer[17]则采用轻量化的CNN-Transformer混合架构,对局部边界信息和全局湖泊结构进行联合建模,实现了更高精度的水体提取。近年来,面向大幅面遥感影像的整体解译技术也引起了关注。如,MFVNet[18]通过多视野自适应融合有效利用跨尺度上下文,在长河流和大范围水体提取中展现出优势。随着大模型的发展,遥感基础大模型也逐渐受到关注。文献[19]提出的多模态基础模型在跨任务、跨领域中展现出较好的泛化能力,为水体分割等下游任务提供了新的思路。
尽管上述研究在水体分割上取得了一些的成果,但其在复杂背景下水体特征提取和关注方面仍存在局限:其一,现有单一编码器结构难以同时兼顾局部细节与全局上下文,而多编码器结构(如双编码器)虽在特征表达上有所提升,但层间信息交互与语义协同仍显不足,导致模型在小型或形态复杂水体的感知与分割精度方面存在限制;其二,现有特征融合方法大多为简单叠加或加权,缺乏针对不同特征来源的自适应交互机制,限制了模型对异构信息的整合;其三,上采样与解码过程常引入特征失真,削弱了边界恢复与细节重建能力。针对上述难题,本文提出了一种双编码器自适应特征融合网络,以实现更加准确的水体分割。该工作的主要贡献总结如下。
(1)构建了结合残差网络和Swin Transformer的双编码器架构,协同提取局部纹理信息与全局上下文语义信息,以增强特征表示的完备性,能更充分地捕捉复杂背景下水体的形态与边缘信息。此外,将残差网络中的标准卷积替换为深度可分离卷积,在保持其特征提取能力的条件下,以有效降低模型的计算开销。
(2)设计了基于交叉注意力和自适应权重学习的特征融合(cross attention and adaptive weight learning-based feature fusion,CAAWLFF)模块来处理上述双编码器提取的特征。该模块利用交叉注意力实现局部全局特征的交互,并通过自适应权重学习完成不同源混合特征的融合,以进一步增强模型对水体结构的表征性能。
(3)在解码阶段,引入多尺度轻量化内容感知上采样模块来恢复特征空间分辨率。该模块集成了多尺度卷积池化和内容感知特征重组(contentaware reassembly of features,CARAFE)模块,以增强特征的多尺度表达能力并有效缓解上采样过程导致的特征失真,精细还原空间细节实现准确的水体分割。
1 本文方法
1.1 DEAFFNet整体结构
DEAFFNet采用经典的编码器-解码器架构,其网络由3个主要部分组成:编码部分、特征融合部分及解码部分。DEAFFNet的输入为256×256像素尺寸的SAR图像;其编码部分为双编码器结构,即一支为基于残差结构的轻量化残差编码器[20],另一支为基于自注意力机制的Swin Transformer编码器[21]。两个编码器各阶段输出的特征通过CAAWLFF模块逐层对齐与融合,融合后的特征通过跳连输入到解码器部分进行特征拼接和解析。解码部分的多尺度轻量化内容感知上采样(multi-scale lightweight content-aware upsampling,MSLCAU)模块则对输入特征进行上采样以逐步恢复空间分辨率,最终输出与输入图像分辨率一致的像素级分割结果。DEAFFNet的整体结构如图1所示。
图1
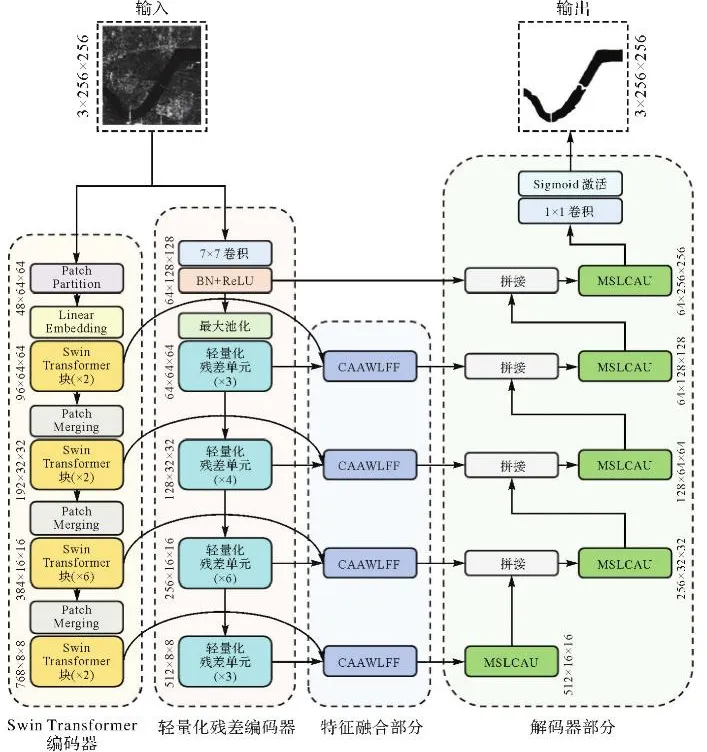
图1 DEAFFNet的整体结构
Fig. 1 Overall structure of DEAFFNet
DEAFFNet的编码器由两条并行的主干网络构成,即轻量化残差编码器和Swin Transformer编码器,旨在联合提取局部纹理细节与全局上下文信息,以增强模型在复杂背景下的水体识别能力。其中,轻量化残差编码器具有较强的局部特征建模能力与较低的计算开销,主要负责提取目标的局部特征信息,为其轮廓的精细表达提供支持。相较而言,Swin Transformer编码器擅长建模图像中的长程依赖关系,具备出色的全局语义感知能力,能够弥补轻量化残差编码器在全局上下文建模方面的不足。通过双编码器结构的协同特征提取,整体编码部分结构能够同时捕捉局部与全局信息,为后续的特征融合与解码过程提供更加丰富全面的特征信息。
1.1.1 轻量化残差编码器
轻量化残差编码器借鉴了ResNet-34的结构设计,充分利用其浅层残差连接在边缘与纹理特征建模方面的优势,逐层提取图像的局部细节信息。该编码器整体由一个初始卷积阶段和4个残差阶段构成。初始卷积阶段包括一个步幅为2、卷积核大小为7×7的卷积层,一个批归一化(batch normalization,BN)层和一个ReLU激活函数,用于提取图像的低层次边缘特征,并有效降低空间分辨率。后再接一个3×3的最大池化层,进一步压缩图像尺寸。4个残差阶段组成该编码器主干,每个阶段包含若干个轻量化残差单元。每个轻量化残差单元则由两个深度可分离卷积模块构成,每个深度可分离卷积包括一个逐通道卷积和一个1×1的逐点卷积,并配有相应的BN层和激活函数。通过引入深度可分离卷积,显著减少了参数量和计算成本,同时保留了残差连接结构,增强特征的传递能力。4个残差阶段之间通过步幅为2的卷积实现下采样,输出通道数依次为64、128、256和512。该编码器能够有效捕捉局部空间信息,为后续的水体轮廓感知提供细粒度的特征支持。
1.1.2 Swin Transformer编码器
该编码器引入Swin Transformer以增强全局语义建模能力。输入图像首先通过4×4的Patch Partition与Linear Embedding形成初始特征表示,随后经过4个阶段的多层Swin Transformer块逐层提取多尺度特征。每个Swin Transformer块采用基于窗口的自注意力机制和滑动窗口策略,实现局部与跨窗口的信息交互,同时在各阶段间通过Patch Merging操作进行下采样,降低空间分辨率并调整通道数。为了便于与轻量化残差编码器的特征进行融合,4个阶段的输出通道数从原始的96、192、384和768调整为64、128、256和512。该设计可以有效捕捉长距离依赖和多尺度上下文信息,显著提升模型在复杂背景下对水体结构的建模能力。
1.2 基于交叉注意力和自适应权重学习的特征融合模块
在复杂背景下,由于局部纹理细节与全局语义之间存在表征差异,传统融合策略往往难以有效协调多源特征,导致水体边界定位难,整体分割精度低。针对这一问题,本文提出一种CAAWLFF模块来处理双编码器输出的特征。该模块首先通过交叉注意力机制,建立轻量化残差编码器与Swin Transformer编码器特征间的双向交互关系,实现局部全局特征的交互;其次,采用自适应权重学习机制(adaptive weight learning mechanism,AWLM)来自适应动态计算权重,对多源混合特征进行加权融合,以突出关键特征并抑制干扰信息。CAAWLFF逐层融合双编码器提取的异构特征,实现局部细节与全局语义的互补增强,最终提升模型在复杂背景下对水体区域的分割能力,其具体结构如图2所示。
图2
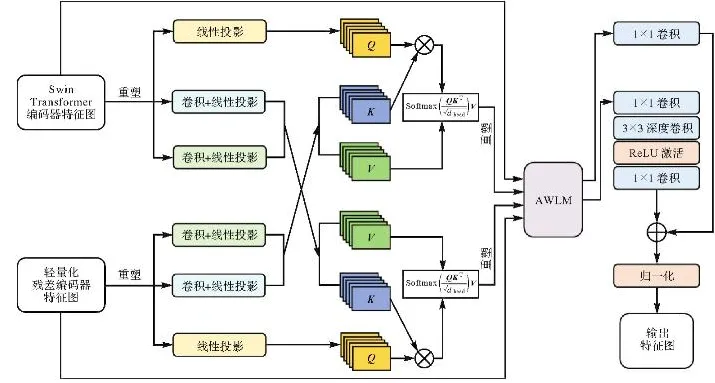
图2 CAAWLFF模块的具体结构
Fig. 2 Specific structure of CAAWLFF module
1.2.1 基于交叉注意力的局部全局特征交互
首先,对来自轻量化残差编码器和Swin Transformer编码器的输入特征分别进行通道压缩与线性投影,统一其维度以适配后续的交叉注意力[22]计算。然后,构建双向交叉注意力路径:一路由轻量化残差编码器输出作为Query(Q),Swin Transformer编码器输出提供Key(K)和Value(V),形成Swin Transformer到残差的交叉注意力,实现全局语义引导增强局部特征;同理,另一路使用Swin Transformer编码器的输出作为Query,轻量化残差编码器提供Key和Value,形成残差到Swin Transformer的交叉注意力,实现局部特征引导增强全局语义。每一路交叉注意力的输出特征通过Softmax计算注意权重,再与Value进行矩阵相乘获得最终的增强输出。
1.2.2 基于AWLM的多源混合特征融合
双向交叉注意力增强完成后,对增强特征进行维度重塑操作,将其恢复至与原始特征相匹配的空间尺寸和通道数,以确保后续融合操作的一致性和稳定性。在最终的融合阶段,为了自适应地平衡不同特征源的贡献,引入AWLM来实现4组多源混合特征(两个编码器分支的原始特征与对应的交叉注意力增强特征)的有效融合。具体融合方式如图3所示,特征1和特征4分别来自两个编码器的原始输出,特征2和特征3则源自相应的交叉注意力增强结果。4组特征首先分别通过由1×1卷积层、BN层和ReLU激活函数构成的轻量变换模块,以提取权重敏感的特征表示。随后,将4组权重特征沿通道维度进行拼接,并执行像素级运算,再利用一个1×1卷积层进一步整合后,经过Softmax函数归一化,生成4个空间自适应权重图(图3中记作ω1至ω4)用于表示每组特征在各个空间位置上的相对重要性。接着,将4个自适应权重图分别与对应的输入特征进行逐元素相乘,得到4组加权特征并通过对逐像素求和获取最终的融合特征。为了进一步提升融合特征的表达能力,使用一个3×3卷积层对融合结果进行优化。
图3

图3 基于AWLM混合特征融合的具体方式
Fig. 3 Specific approach to AWLM-based hybrid feature fusion
优化后的融合特征进一步通过双分支残差路径进行处理,以增强语义一致性。一路经过1×1卷积通道,另一路依次通过1×1卷积、3×3深度卷积和ReLU激活,再通过1×1卷积压缩通道,最后两路相加,经过归一化后输出结果。CAAWLFF模块通过残差机制、注意力引导和自适应加权融合,有效提升双编码器间的信息交互能力,实现不同源特征间的互补融合。
1.3 DEAFFNet的解码器
在复杂背景的SAR图像中,水体边缘通常较为模糊,容易被背景干扰所掩盖,导致分割结果中出现边缘结构不连续的问题。为此,DEAFFNet在解码器部分引入了一种融合优先的多尺度重建机制,以增强水体结构的还原能力。具体而言,DEAFFNet解码器采用自底向上的逐层重建策略,其核心由MSLCAU模块构成。与传统“先上采样再融合”的方式不同,DEAFFNet在除最底层外的每一解码阶段,均先对当前主干编码器输出与前一阶段解码器输出进行通道拼接融合,再执行上采样操作,从而实现空间细节与语义信息的逐步整合,有效提升特征重建的连贯性。其中,MSLCAU模块内部集成了多尺度卷积池化(multi-scale convolution pooling,MSCP)结构和CARAFE上采样模块[23]。MSCP通过设置膨胀率为1、2、4、6的并行卷积分支,有效整合多感受野下的上下文特征,较小的膨胀率可更精准地捕捉小尺度水体与边缘信息,使水体轮廓提取更为完整。融合后的特征经卷积对齐后输入CARAFE上采样模块,该模块依据局部内容生成重组权重,并以此对特征进行空间重构,从而显著增强边界细节的还原能力,缓解传统上采样操作带来的特征失真。上采样结果经两层卷积和ReLU激活后传入下一解码阶段,逐层提升重建精度。该“融合优先”的设计增强了模型对水体结构的感知能力,在复杂背景下展现出更优的分割性能。MSLCAU模块的具体结构如图4所示。
图4
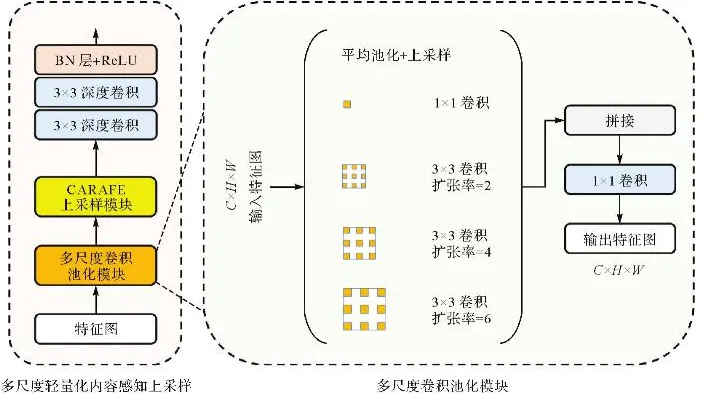
图4 MSLCAU模块的具体结构
Fig. 4 Specific structure of MSLCAU module
1.4 损失函数
在水体的分割任务中,细小水体往往较难处理。该类目标通常尺寸较小、边界模糊、与背景对比不强,常规的单一损失函数难以兼顾水体区域准确性与边界完整性。于是,设计了一种复合损失函数,其融合了焦点(Focal)损失[24]以及主动轮廓(active contour,AC)损失[25]。
(1)Focal损失。Focal损失用于提升模型的前景识别能力和分割准确性。其重点关注难检测样本,减少易检测样本对梯度的主导,从而减缓前景与背景样本不均衡带来的影响。Focal损失的表达式为
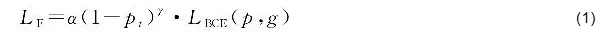
式中,LF表示Focal损失;pt=exp(-LBCE);LBCE为二元交叉熵损失;p表示模型输出预测概率,g表示真实值;α和γ为聚焦因子,通常分别设置为0.8和2.0。
(2)主动轮廓损失。为增强模型对水体边缘轮廓的建模能力,引入基于区域能量和边界平滑的AC损失函数。该损失函数能将主动轮廓模型中区域能量与边界平滑的思想融入网络训练过程中。作为一种结构感知的监督方式来引导模型学习目标区域并准确地定位边缘位置,以提升水体结构的分割精度。AC损失函数融合了区域能量项和边界能量项,其定义式如下
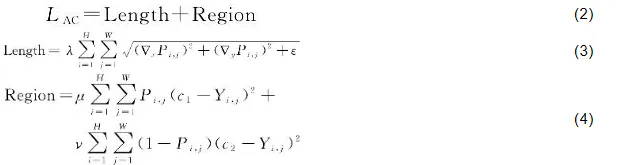
式中,Pi,j为模型预测的概率图;Yi,j为真实标签;c1与c2分别为前景与背景区域的平均强度;∇Pi,j表示预测图的梯度;μ、ν及λ为相应项的权重系数,本文中分别设置为0.8、0.4及0.01。上述参数设置主要基于以下两个方面。首先,参考了主动轮廓损失的原始理论以及多项以该损失为核心的后续研究[25-27],特别是分割网络的相关工作[28-29],以此作为参数设定的初始依据。其次,针对SAR图像中水体目标尺度、边界形态以及背景复杂性等,对区域项与边界项的权重进行了针对性的调优,使其更契合细小水体目标的表达需求。最后,经试验验证与比较分析,确定了所采用的最优参数组合。
(3)总体损失函数。最终训练使用的损失函数定义为两个子项的和

2 试验
2.1 试验数据集
本文使用了两个遥感图像数据集。其中,ALOS PALSAR数据集来自日本宇宙航空研究开发机构(JAXA)2006年1月24日发射的ALOS卫星搭载的PALSAR雷达。原始遥感图像是经过处理后的幅度图像,本文仅对数据集的图像进行了简单的裁剪与尺寸调整,处理后的图像每张图像尺寸为256×256,共有1000张。另一个使用的Sen1-SAR数据集是根据Sentinel-1卫星提供的SAR图像构建的,这些图像来自公开可用的Sen1Floods1 1数据集。从该资源中,选择了1000个大小为512×512的SAR图像样本,并使用Otsu阈值法生成相应的水/非水标签。所有图像在用于训练和评估之前都均匀调整大小为256×256。值得注意的是,本文中所有数据集都仅进行了简单的尺寸调整以适应网络输入,其余处理均保持数据集原始提供的状态。因此,对于其他未经标定的原始数据,可能需先做相应预处理才能作为网络输入。本文方法主要基于影像的空间语义特征进行学习,而非直接依赖成像几何信息,因此在一定程度上对侧视角和侧视方向变化具有稳健性。模型中的残差编码器能够提取方向无关的局部特征,而Transformer编码器可通过自注意力机制建模全局上下文关系,从而在复杂成像条件下保持稳定的特征表达。在本文中,ALOS PALSAR数据集和Sen1-SAR数据集都遵循6∶2∶2的比例划分为训练集、验证集和测试集,分别用于模型训练、参数调优与最终性能评估。其中,训练集用于模型的权重更新,验证集用于动态调整学习率和早停判断,测试集则在训练完成后进行独立推理,以全面评估模型在未见样本上的检测能力。该划分方式确保了数据的多样性和评估的公平性。
2.2 评估指标
为了全面评估模型在水体分割任务中的性能,本文采用了4个常用评估指标:交并比(intersection over union,IoU)、平均交并比(mean IoU,mIoU)、准确率(POA)及Kappa系数。这些指标从不同维度衡量模型的预测质量与稳健性。IoU衡量预测区域与真实区域的重叠程度;mIoU是背景与水体类别IoU的平均值;POA反映了模型对所有像素的整体分类准确性;Kappa系数用于评估分类结果与真实标注之间的一致性。上述指标的具体计算式如下
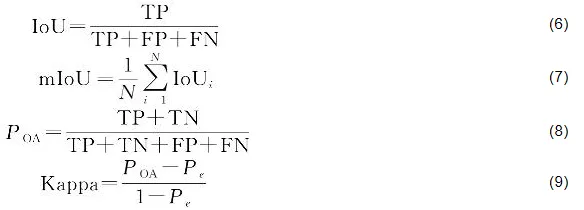
式中,POA表示实际分类准确率;Pe表示随机一致性概率,其表达式如下
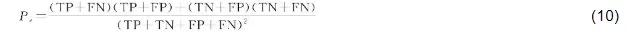
式中,TP、TN、FP和FP分别表示真阳性、真阴性、假阳性和假阴性的像素数量。在水体分割任务中,尤其是在复杂背景下,往往存在显著的类别不平衡问题。IoU通常聚焦于水体类别的预测准确性,容易忽略对背景(非水体)类别的评估,因而无法全面反映模型整体性能。为此,本文引入mIoU指标,通过对所有类别的IoU取平均,能够更有效地衡量模型在整体语义空间中的表现。
2.3 试验环境具体设置
本文提出的DEAFFNet模型在PyTorch框架下实现,所有试验均在搭载NVIDIA GeForce RTX 4070 GPU的工作站上完成。训练过程中采用Adam优化器,初始学习率设为0.000 1,并使用基于验证集性能的学习率调度策略(ReduceLROnPlateau),根据验证损失动态调整学习率。模型采用混合精度训练以加速计算和节省显存。每轮训练使用批量大小为2,训练周期设定为100,并在训练过程中启用了早停机制以防止过拟合。
2.4 与其他模型的对比试验
图5直观地展示了DEAFFNet的水体分割结果,并将其与其他8种主流模型进行比较,以验证所提模型在复杂干扰背景下的分割准确性。对比模型涵盖了经典的卷积神经网络结构(UNet、ResUNet[30])、双分支编码器结构(DSHNet、WaterFormer)、基于注意力机制的两种代表性方法(SwinUNet[31]、MAFUNet[32]),以及近年来专门的SAR图像水体分割网络(QTU-Net[33]、LEFormer)。相应模型的水体分割结果如图5所示。
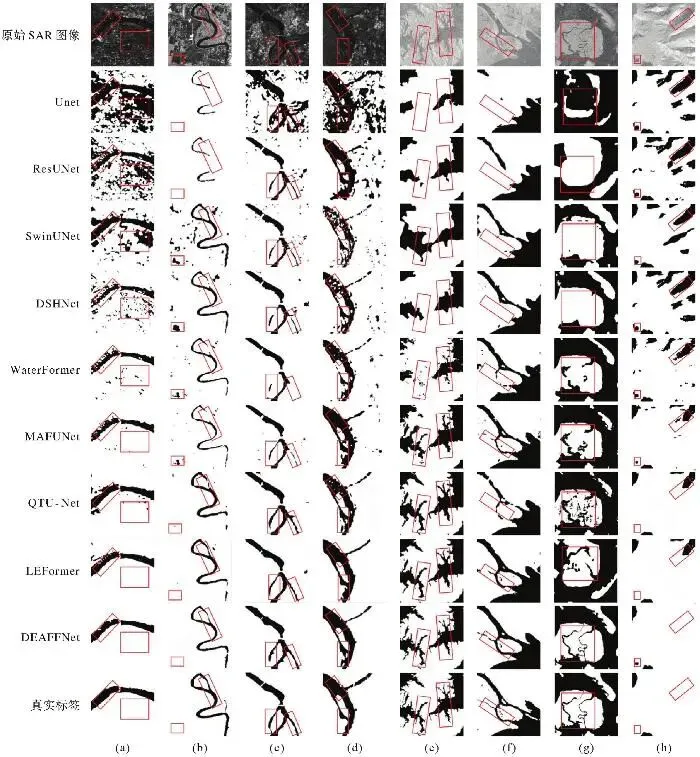
图5
图5 水体SAR图像和原始标签及8种模型的水体分割结果
Fig. 5 Water body segmentation results on SAR images, including the original label and the outputs from eight different models
相比之下,本文提出的DEAFFNet在多个方面实现了性能提升。在ALOS PALSAR数据集和Sen1-SAR数据集上与其他8种模型对比的定量评估结果见表1。首先,双编码器架构融合了轻量化残差编码器的局部纹理建模能力与Swin Transformer的全局依赖建模能力,有效缓解了复杂背景中非水体区域引发的误判,同时提升了对水体整体结构的语义理解。其次,在特征融合阶段引入基于交叉注意力和自适应权重学习的特征融合模块,通过空间权重重构,引导不同源特征间的信息互补,显著提升了模型在纹理复杂区域中对目标的识别准确性。针对细小河流水体结构容易中断的问题,DEAFFNet在解码阶段使用多尺度轻量化内容感知上采样模块,实现对多尺度结构信息的逐层恢复,有效保障了水体轮廓的连续性与细节完整性,使得预测边界更加平滑且与真实标签高度一致。此外,设计的融合Focal损失与主动轮廓损失的复合损失函数,有效优化了水体区域的边界贴合度与内部一致性。在性能评估中,DEAFFNet在多个关键指标上均显著优于其他试验模型。在ALOS PALSAR数据集上与MAFUNet相比,DEAFFNet的IoU提高了1.39个百分点,mIoU提高了1.42个百分点,POA提高了0.66个百分点,Kappa提高了3.15个百分点。在Sen1-SAR数据集上与MAFUNet相比,IoU提高了0.98个百分点,mIoU提高了2.28个百分点,POA提高了1.35个百分点,Kappa提高了2.11个百分点。
表1SAR图像水体检测结果的定量评价分析
Tab. 1
| POA | |||||
|---|---|---|---|---|---|
2.5 消融试验
为验证本文提出DEAFFNet各关键模块在复杂背景水体检测任务中的有效性,在ALOS PALSAR数据集上设计并开展了消融试验。具体评估了以下3个核心组件的性能影响:双编码器结构(轻量化残差编码器+Swin Transformer编码器)、基于交叉注意力和自适应权重学习的特征融合模块(CAAWLFF)以及集成多尺度轻量化内容感知上采样(MSLCAU)模块,相应的消融试验结果数据列见表2。此外,基线模型采用ResNet作为编码器,引入跳跃连接机制,在解码阶段使用双线性插值进行逐步上采样。
表2模型不同模块的消融试验结果
Tab. 2
| POA | ||||
|---|---|---|---|---|
从仅使用基线模型进行训练开始。本文引入了并行的Swin Transformer编码器,构建了双编码器结构,表中记为“双编码器”。与基线模型相比,该结构显著提升了模型性能,IoU提高了2.21个百分点,验证了Swin Transformer在建模长距离依赖关系和捕获全局语义上下文方面的优势。为增强特征表示能力,基于双编码器结构,本文评估了两个关键模块的增益效果。引入CAAWLFF模块后,模型在IoU上提升了1.74个百分点,表明基于交叉注意力与通道增强的融合机制能够有效强化语义一致性,同时抑制背景干扰信息,提升结构表达能力。与此同时,引入MSLCAU模块同样带来了显著性能提升。与双编码器模型相比,IoU提高了0.9个百分点,说明该模块在解码阶段有效增强了多尺度上下文感知,并改善了边界与细节的恢复效果。最终,集成全部模块的DEAFFNet模型在各项指标上均取得最优表现,IoU达到95.67%,mIoU达到86.17%,POA达到97.89%,Kappa系数达到89.96%。这些结果充分验证了所提出模块之间的协同作用,以及该模型在复杂遥感场景下进行水体精细分割的有效性与稳健性。
此外,为验证所提出复合损失在复杂水体检测任务中的有效性,本文在两种模型结构(基线与DEAFFNet)上分别引入二元交叉熵(binary cross-entropy,BCE)损失、Focal损失与复合损失函数(Focal+AC)进行对比试验,结果见表3。传统的BCE损失因其实现简便,广泛应用于语义分割任务中,但在遥感水体检测中常受到前景与背景类别不平衡的影响,导致模型更倾向于预测背景区域,难以有效识别小尺度或低对比度水体。为缓解该问题,本文引入Focal损失替代BCE损失。Focal损失通过对易分类样本赋予较小权重、对难分类样本给予更高关注,能够显著提升模型在复杂场景中对小目标和模糊边界的辨识能力。然而,Focal损失主要关注分类置信度,对于边界结构的连续性和轮廓光滑性缺乏有效约束。因此,本文进一步引入主动轮廓(AC)损失,作为边界感知的正则项,增强模型对目标形状的建模能力,抑制预测结果中的不规则边缘与噪声干扰。Focal损失与AC损失构建的复合损失函数,能兼顾难例识别与边界精细化,从而提升模型对复杂水体结构的整体感知与分割质量。
表3不同损失函数下的性能比较
Tab. 3
| POA | ||||
|---|---|---|---|---|
在基线模型上,使用Focal损失相较于BCE损失,在各项指标上均有所提升,其中POA提高了0.57个百分点,IoU提升了0.38个百分点。这表明Focal损失通过聚焦于难分类样本,有效缓解了前景与背景之间的类别不平衡问题。进一步引入AC损失后,模型性能持续提升,相较于仅使用Focal损失,Kappa提高了0.46个百分点,POA提高了0.28个百分点,表明AC损失有助于优化水体边界的空间连续性,抑制预测结果中的不规则轮廓和噪声干扰。在DEAFFNET模型上,相比于仅使用BCE损失,结合Focal与AC的复合损失在IoU上提升了0.69个百分点,POA提升了0.58个百分点,Kappa提升了3.07个百分点,在所有评价指标中均取得最佳表现,验证了复合损失在复杂水体检测任务中的有效性与稳健性。
上述消融试验结果表明,各组件在不同方面对水体检测性能的提升均有积极贡献,结合Swin编码器的双编码器结构与MSLCAU模块进行解码在提升全局建模能力与细节还原方面作用显著,而CAAWLFF模块则有效促进了多源特征的信息融合,从而提升了复杂背景下水体检测的准确性。此外,复合损失函数在优化过程中兼顾了边界轮廓保持与小目标敏感性,提升了模型指标上的表现。
3 结论
为了提高复杂背景条件下SAR图像水体检测的准确性,提出了一种双编码器自适应特征融合网络(DEAFFNet)。该模型充分融合CNN与Transformer的优势,构建了双编码器结构:其中,轻量化残差编码器侧重于提取局部空间细节特征,而Swin Transformer编码器则通过分层自注意力机制建模长距离上下文依赖,实现了细节保持与全局感知能力的有机统一。为有效融合异构特征信息,DEAFFNet设计了基于交叉注意力和自适应权重学习的特征融合模块,引入交叉注意力以加强不同源特征间的协同表达,显著提升了模型对边界和小目标的感知能力。在解码器部分,模型使用多尺度轻量化内容感知上采样模块,结合了卷积池化结构与内容感知上采样操作,有效缓解了传统上采样过程中导致的特征失真问题,提升了边界还原的连续性与结构完整性。此外,针对水体检测任务中常见的边界模糊与目标尺寸不平衡问题,本文构建了融合Focal损失与AC损失的复合损失函数,进一步强化了模型对水体边界的辨识能力与对小目标的检测敏感性。在ALOS PALSAR数据集上的水体检测试验表明,与现有主流方法相较,DEAFFNet能获取更加准确的水体检测结果,在IoU、mIoU、POA及Kappa系数上均具有一定的优势。
尽管如此,本文模型仍存在一定的局限性。在高分辨率的复杂背景SAR图像中,DEAFFNet对细长水体和广域水域的连续性建模仍有待提升,可能出现局部漏检或背景误判现象。针对上述挑战,未来研究方向可包括以下4个方面:①引入遥感基础大模型,利用多模态基础大模型的多任务和多领域泛化能力,通过知识迁移或微调,进一步提升模型在少样本、复杂背景和多任务场景下的表现;②结合大幅面遥感影像整体解译技术,在长河流或大范围水体提取中,引入如MFVNet的多视野融合机制,以充分利用跨尺度上下文信息,增强大尺度连通性和边界连续性,与局部尺度特征处理形成互补;③融合多源遥感模型或对复杂噪声进行建模,通过整合光学、SAR或多波段信息,以及引入更复杂的噪声建模策略,提高模型在极端干扰条件下的稳健性和泛化能力;④多视角数据集试验,在多角度的遥感影像数据集上验证模型的性能,并考虑引入几何校正或角度自适应注意力机制,以增强模型在不同侧视条件下的泛化能力。

往期推荐
资讯

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 邵东海归精英唐彬:14岁考入南京大学,如今公司坐拥3万亿流水
- 【生物学】南京市、盐城市2026届高三年级第一次模拟考试试题+答案
- 【地理】南京市、盐城市2026届高三年级第一次模拟考试试题+答案
- 【数据分析】南京大学物理学院;专业招生规模悬殊?物理学占优!
- 今年高考的方向来了,南京盐城一模!难度不低,新高考地区的重要试卷,做一张少一张
- 今日苏超 2026.03.28 | 南京队迎首胜,苏南德比激情上演
- 特别提醒!南京公交临时开通12条公交祭扫专线,其中祭扫10号线服务六合区!
- 南京鼓楼区的张老师事件反转?是真相来了,还是真相被搅浑了?
- 封神级美景,南京随手一拍都是壁纸
- 五人得分上双 新疆伊力特94-87战胜南京天之蓝
