<StableMind: Source-Free Cross-Subject fMRI Decoding with Regularized Adaptation>论文:https://arxiv.org/pdf/2605.02586代码:https://github.com/lingeringlight/StableMind一、研究方向及背景
本文属于 fMRI-based brain decoding / 脑视觉解码 方向,即根据人脑在观看图像时产生的 fMRI 信号,恢复或检索对应的视觉刺激图像。近年来,这类方法常将 fMRI 信号映射到 CLIP、扩散模型等大模型的视觉语义空间中,再进行图像检索或图像重建。
传统 fMRI 图像重建方法通常为每个被试单独训练一个模型,但这需要大量高质量 fMRI 数据。现实中,新被试的数据采集昂贵且耗时,往往只能获得 1 小时左右的数据。同时,由于隐私、存储或共享限制,旧被试的原始 fMRI-image 配对数据在新被试适应阶段可能不可用。
因此,本文研究的是更现实的场景:Source-Free Cross-Subject fMRI Decoding,即模型先在多个源被试上预训练,再在新被试上用少量数据适应,但适应阶段不能访问源被试原始数据。
论文认为现有方法性能下降主要来自两个不稳定因素,如 图1 所示:
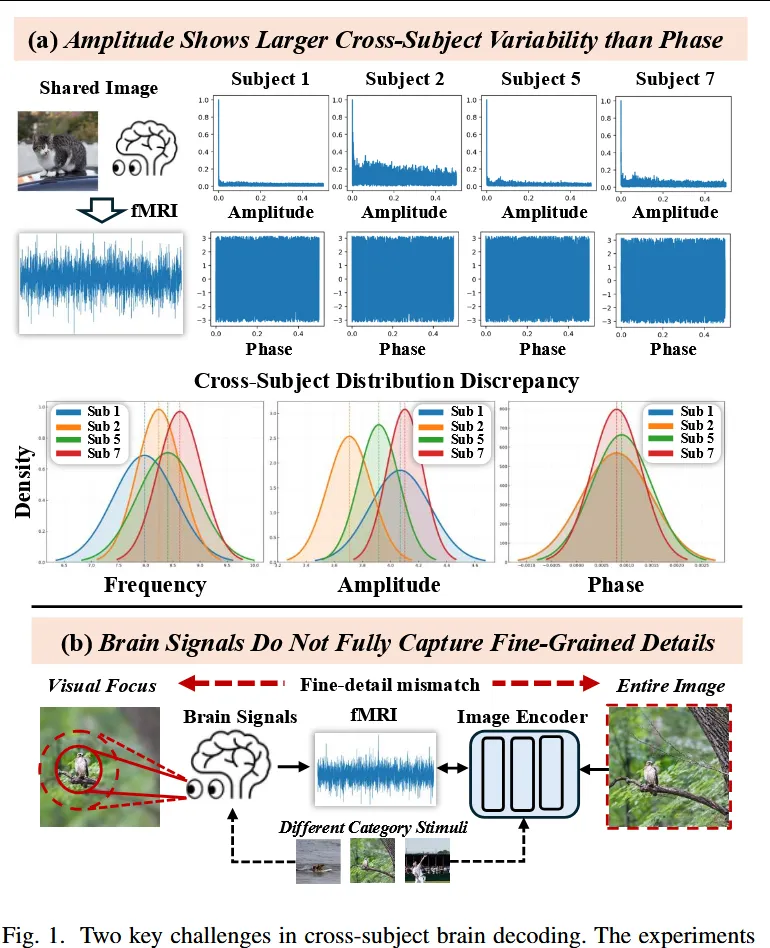
图1(a) 展示了不同被试在相同视觉刺激下的 fMRI 表征分布存在明显差异,尤其是频谱中的 amplitude / 幅度统计差异 大于 phase / 相位差异。这说明跨被试适应时,脑信号侧存在强烈个体差异。
图1(b) 则说明 fMRI 信号未必能可靠捕捉图像中的所有细粒度视觉细节。如果直接用完整清晰图像作为监督,模型可能被迫学习一些脑信号中并不稳定存在的纹理、背景等细节,从而造成过拟合。
二、研究方法或创新点
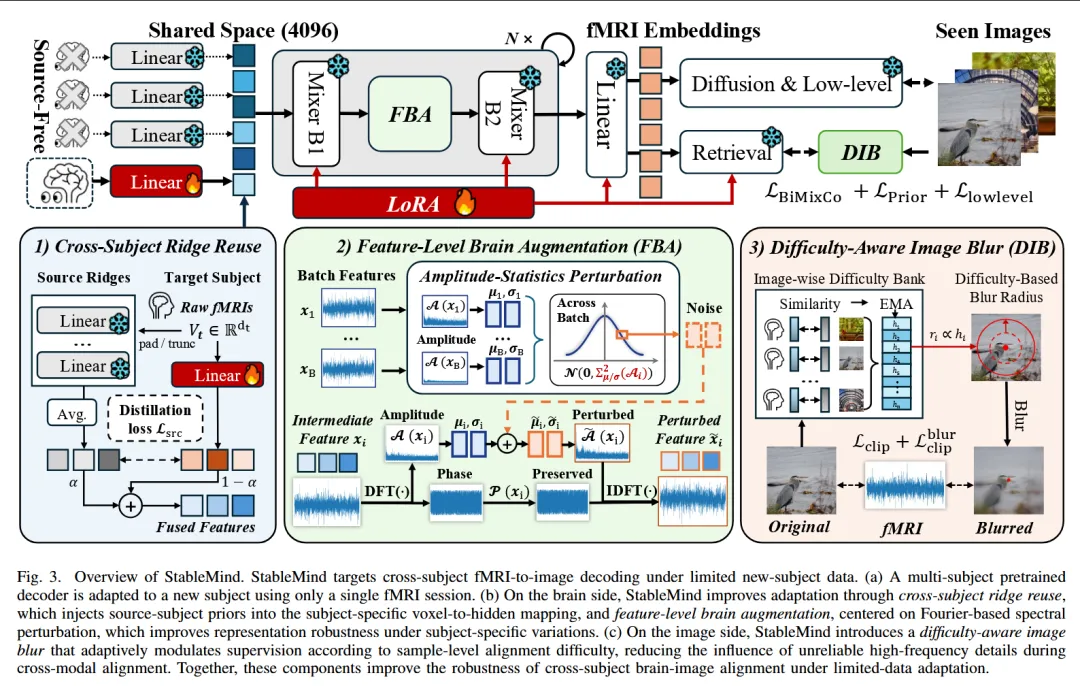
论文提出 StableMind,一个面向无源跨被试 fMRI 解码的正则化适应框架。整体流程见 图3。它从两个层面稳定模型适应过程:
- 脑信号侧稳定性:减少新被试 fMRI 表征因个体差异造成的不稳定。
- 图像监督侧可靠性:避免模型过度依赖 fMRI 难以支持的细粒度图像细节。
StableMind 主要包含三个模块。
创新点一:跨被试 Ridge 重用
Cross-Subject Ridge Reuse, CSRR
跨被试 fMRI 解码中,不同被试的 voxel 数量和脑响应模式不同,因此通常需要一个被试特定的 ridge projection,将不同被试的 fMRI 映射到统一潜在空间。
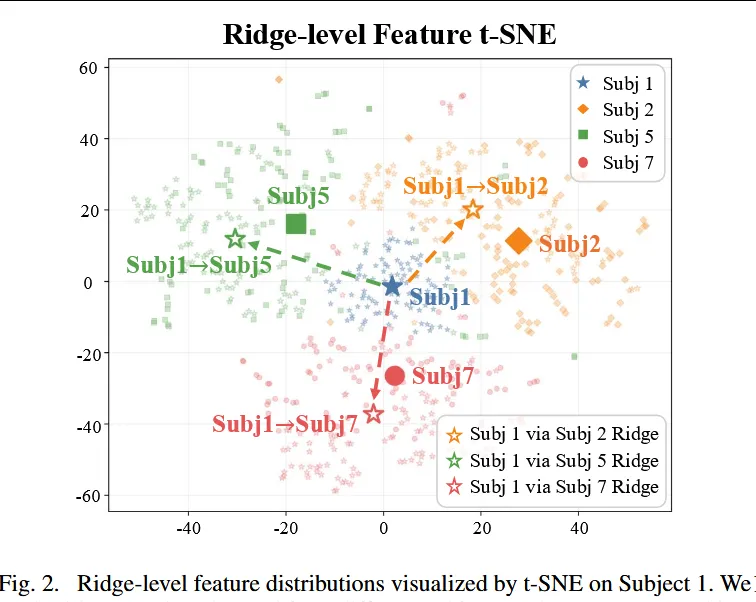
论文通过 图2 发现:即使输入同一个目标被试的 fMRI 信号,使用不同源被试的 ridge 层进行映射,也会得到分布明显不同的 latent feature。这说明 ridge 层本身包含被试特异性的投影模式。
StableMind 的做法是:在新被试适应时,不完全依赖新被试少量数据学习 ridge,而是复用预训练模型中源被试的 ridge projection 作为弱先验。具体来说:
- 将目标被试 fMRI 经过 padding / truncation 后送入多个冻结的源被试 ridge;
- 得到多个源 ridge 输出后求平均,形成 source prior;
- 将目标 ridge 输出与 source prior 加权融合;
- 再用一个弱 cosine distillation loss 约束目标 ridge 不要偏离源先验过远。
这一设计的作用是:用多个源被试的投影知识稳定新被试的 voxel-to-latent 映射,降低少样本适应时的过拟合风险。
创新点二:特征级脑表征增强
Feature-Level Brain Augmentation, FBA
论文观察到,跨被试 fMRI 表征差异主要体现在频谱幅度统计上,而相位信息相对稳定。因此,StableMind 在中间脑特征上进行 Fourier-based augmentation:
- 对中间 fMRI feature 做离散傅里叶变换;
- 对 amplitude / 幅度统计进行高斯扰动;
这一过程见 图3 中的 Feature-Level Brain Augmentation 模块。
其核心思想是:只扰动容易受个体差异影响的幅度统计,而保留结构性更强的相位信息。这样可以让模型在训练时见到更多“合理变化”的脑特征,从而减少对某些被试特异性或样本特异性模式的依赖。
论文在 表VII 中比较了多种增强方式,包括 random noise、uniform、swap amplitude、mix amplitude 和 Gaussian model。结果显示,Gaussian amplitude-statistics perturbation 效果最好,说明平滑、受控的幅度统计扰动比无结构噪声更适合 fMRI 跨被试适应。
创新点三:难度感知图像模糊监督
Difficulty-Aware Image Blur, DIB
现有方法往往直接使用原始清晰图像或图像编码特征作为监督目标。但在只有 1 小时 fMRI 数据的情况下,脑信号未必支持图像中的全部细节,尤其是纹理、背景等高频信息。
StableMind 因此提出 难度感知图像模糊监督:
- 维护一个 image-wise difficulty bank;
这一机制见 图3 中的 Difficulty-Aware Image Blur 模块。
在 表VI 中,论文比较了 clean image、whole blur、fixed-radius blur 和 difficulty-aware blur。结果显示,难度感知模糊在 PixCorr、Inception、CLIP、image retrieval 和 brain retrieval 等指标上整体最优,说明自适应模糊比固定模糊或全图模糊更有效。
三、实验结果
1. 数据集与实验设置
实验在 Natural Scenes Dataset, NSD 上进行。NSD 是大规模 7T fMRI 数据集,包含 8 名被试观看自然图像时的脑响应。论文采用跨被试设置:
- 目标被试只使用 1 小时 fMRI 数据 进行适应;
- 主要在 subject 1、2、5、7 四个完成全部 40 个 session 的被试上评估。
这对应大约只使用完整单被试训练数据的 2.5%。
2. 与 SOTA 方法比较:检索性能明显提升
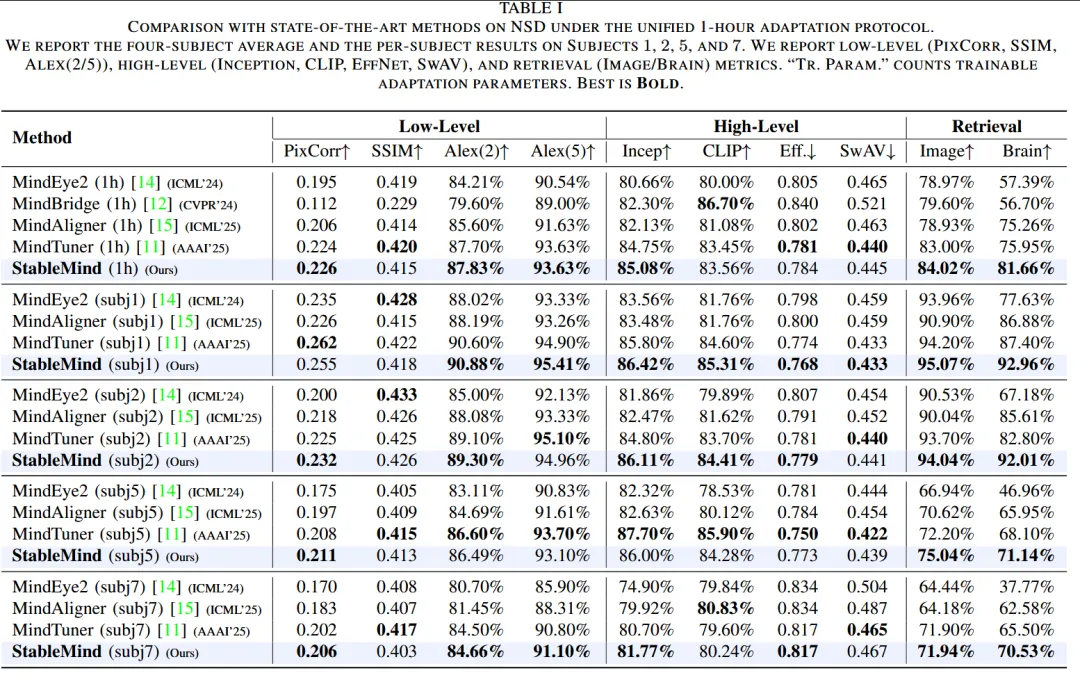
核心结果见 表1。
在四个目标被试平均结果上,StableMind 达到:
其中 Brain Retrieval 的提升尤其明显,说明 StableMind 学到的脑-图像对齐表征更加稳定、可区分。
相比 MindEye2,StableMind 的 Brain Retrieval 从 57.39% 提升到 81.66%,提升幅度达到 24.27 个百分点。
3. 图像重建质量:保持竞争力
表1 还报告了 fMRI-to-image reconstruction 的低层和高层指标:
- 低层指标:PixCorr、SSIM、AlexNet(2)、AlexNet(5)
- 高层指标:Inception、CLIP、EffNet、SwAV
与 MindEye2 相比,StableMind 在多数指标上更好,例如:
- Inception:80.66% → 85.08%
与 MindTuner 相比,StableMind 的重建质量整体相当,并在部分高层语义指标上更好。
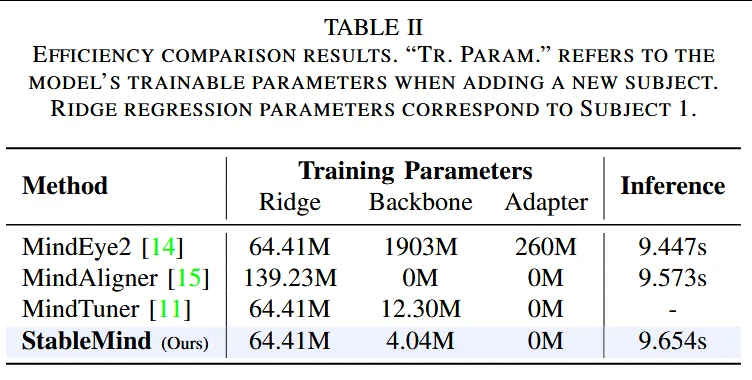
4. 参数效率:更少可训练参数
见 表2。StableMind 在新被试适应时只需要约 4.04M 个可训练适应参数,而 MindTuner 需要 12.30M。这说明 StableMind 不仅性能更强,而且更加参数高效。
5. 消融实验:三个模块互补有效
见 表3。论文分别去除 CSRR、FBA、DIB 后观察性能变化。结果表明:
- 只要加入其中两个模块,性能就超过无模块 baseline;
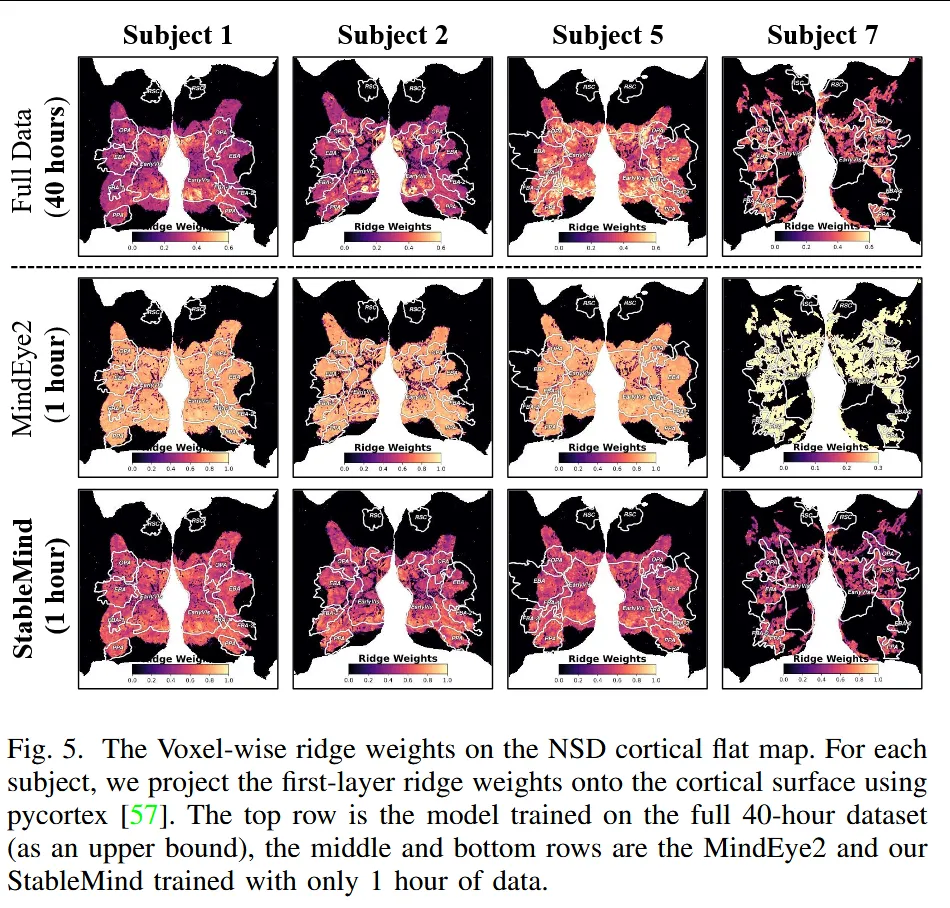
6. 可视化结果
图5 展示了 voxel-wise ridge weights 在 NSD cortical flat map 上的分布。StableMind 在只有 1 小时数据时,能恢复出比 MindEye2 更清晰、更接近 40 小时全数据模型的视觉皮层权重模式。
图6 展示了图像重建样例。相比 MindEye2 和 MindAligner,StableMind 重建图像在物体形状、颜色、场景布局上更接近原始刺激图像。
图7 展示 t-SNE 特征分布。StableMind 的类内聚合更紧密、类间分离更清晰,说明其学习到的脑表征更具判别性。
表IX 则从频谱角度证明 StableMind 降低了跨被试差异:其 frequency gap、amplitude gap、phase gap 均低于 MindEye2、MindAligner 和 MindTuner,其中 amplitude gap 从 MindEye2 的 20.068 降到 6.078。
四、总结
这篇论文的核心贡献是:将跨被试 fMRI 解码问题从单纯的“表征对齐”重新理解为一个 有限数据下的正则化适应问题。
StableMind 针对两类不稳定来源提出对应解决方案:
- 被试差异导致的脑表征不稳定
通过 CSRR 复用源被试 ridge 先验,并用 FBA 在频谱层面对脑特征进行增强。 - 图像细节监督与 fMRI 信号不匹配
通过 DIB 对图像监督进行难度感知模糊,减少模型对不可靠细节的过拟合。
实验表明,在仅使用 1 小时目标被试 fMRI 数据的设置下,StableMind 在图像检索、脑检索和图像重建方面都取得了较强表现,尤其显著提升了 Brain Retrieval,并且所需可训练参数更少。
总体来看,本文的价值在于把 fMRI 跨被试解码推进到更真实的部署场景:数据少、源数据不可访问、个体差异显著。这对未来脑机接口、神经影像辅助诊断、个体化脑解码模型等方向具有一定启发意义。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~本文仅做学术分享,如有侵权、笔误等,请联系修改、删文