论文标题:SAMYOLO: Integrating Super-Resolution and Vision Mamba for Enhanced Small Object Detection作者:Wanjun Wang、Mingyong Pang、Wenxuan Zhou、Chunyan Ma作者单位:南京师范大学、东南大学、河海大学发表信息:IEEE JSTARS,2026DOI:10.1109/JSTARS.2026.3653498
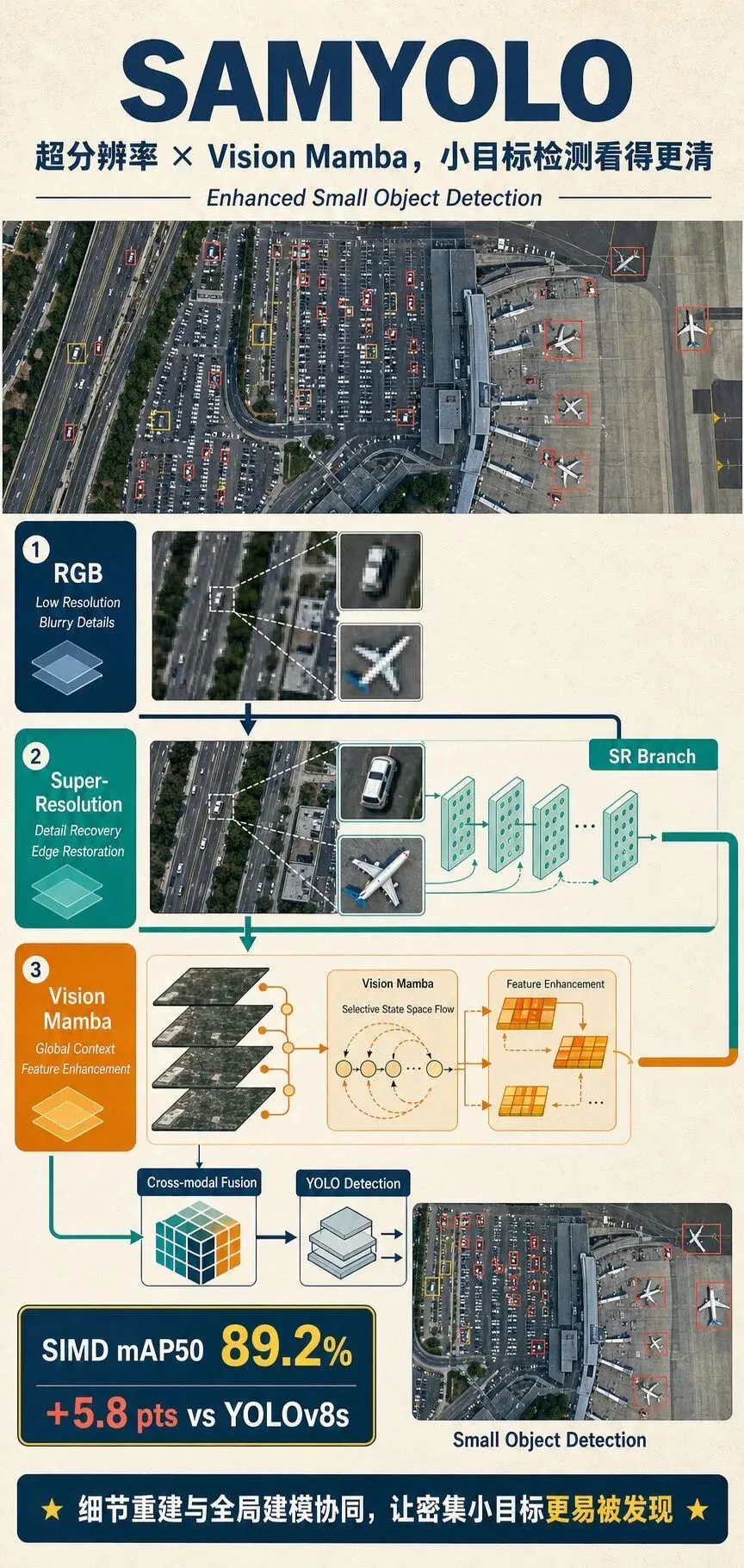
SAMYOLO:先把小目标看清,再把上下文连起来
遥感小目标检测,难点不只是“目标小”。
真正麻烦的是:一辆车、一艘船或一架远处的飞机,可能只剩十几个像素。特征图连续下采样后,边缘和纹理很快消失。
目标一旦密集排列,背景又很复杂,漏检、错检和类别混淆就会一起出现。
SAMYOLO把问题拆成两步:先利用超分辨率恢复局部细节;再用 Vision Mamba 建立更大范围的空间联系。一个负责“看清”,一个负责“看全”。
一图流:SAMYOLO 用超分辨率与 Vision Mamba 增强遥感小目标检测
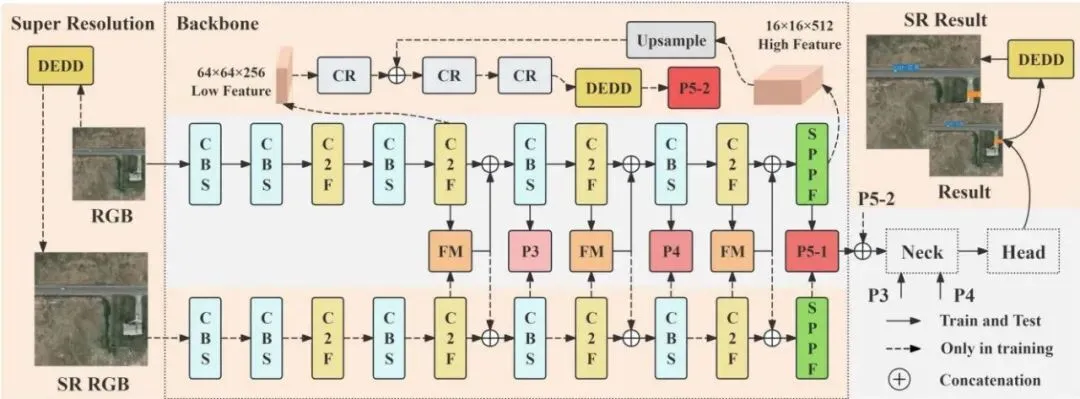
完整路线:RGB 与 SR 双流协同
左侧有两路输入。上路是原始 RGB 图像,下路是经过 DEDD 生成的超分辨率图像,也就是 SR RGB。两路图像分别进入骨干网络,并在多个尺度通过 FM 模块交换信息。
图中的 P3、P4、P5-1 和 P5-2 对应不同分辨率的特征。P3 更适合保留小目标的空间细节,较深层的 P5 则包含更强的语义信息。SAMYOLO 不是在最后才把两路结果拼起来,而是在骨干网络内部进行多尺度融合。
实线表示训练和推理都会经过的路径。虚线主要服务于训练阶段的超分辨率与辅助约束。最终融合后的特征进入 Neck 和 Head,输出检测结果。
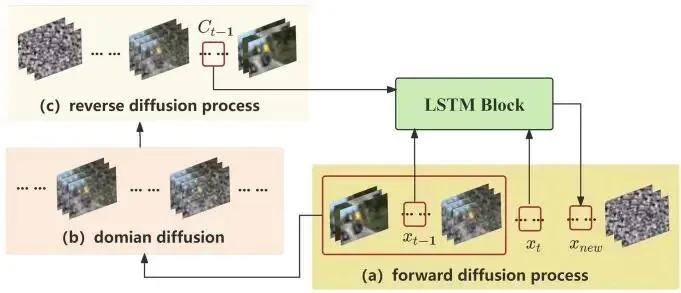
DEDD 怎样补回细节?
超分辨率容易带来一个问题:放大的图更清晰了,但新增纹理可能只是模型“猜”出来的。
论文使用 DEDD,也就是基于视差估计与域扩散的超分辨率模块。它希望恢复结构细节,同时减少不可靠纹理对检测的干扰。
图中包含三个过程:
1. 前向扩散逐步加入扰动,构造不同状态;
2. 域扩散建立可用于修正的中间空间;
3. 反向扩散再从噪声状态恢复更干净的特征。
LSTM Block 接收这些阶段的信息,让前向与反向过程发生交互。
模型在受约束的空间里重新估计细节,而不是进行机械插值。训练时,论文保留了域扩散部分,并把它嵌入 RGB 与 SR 分支的联合训练中。
DEDD 的价值不只是生成一张“看起来更锐”的图。它提供了另一套高分辨率特征,让微小车辆的边缘、飞机轮廓和密集目标间隔更容易保留下来。
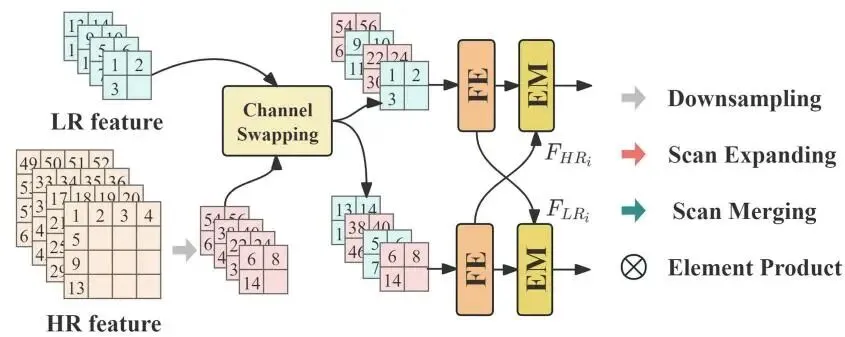
第二步:FM 模块怎样融合两路信息?
有了 RGB 和 SR,并不等于融合自然有效。
RGB 更稳定,保留原始结构。SR 更强调细节,但也可能包含重建误差。直接相加或拼接,很难处理两种模态之间的差异。
FM 模块先把 HR 特征下采样,使它与 LR 特征的空间尺寸和通道数对齐。随后,两路特征被按通道拆分,并通过 Channel Swapping 交叉交换。
论文用下面一组公式表示浅层通道交换:
F_sLR_i 和 F_sHR_i 分别是第 i 个尺度的浅层低分辨率与高分辨率特征,CS 表示通道交换。输出的 F_sFLR_i 与 F_sFHR_i 都同时包含两路信息,但仍保留各自的主分支方向。
通道交换让两路特征在浅层先混合一部分信息,而不是用 SR 特征直接覆盖 RGB。交换后的特征分别进入 FE 和 EM:FE 偏向局部特征提取,EM 负责进一步增强与跨模态融合。
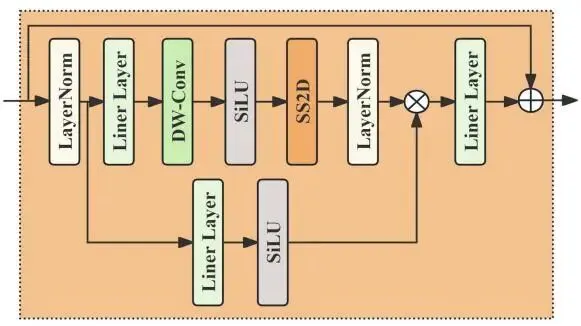
Vision Mamba 的作用
Mamba 的核心落在 SS2D,也就是二维选择性扫描。
上方主分支经过 LayerNorm、线性层、深度可分离卷积和 SiLU,再进入 SS2D。SS2D 会沿上下、下上、左右、右左四个方向展开图像特征,分别建模,再合并回原来的二维布局。这样做的意义是:一个局部小块不再只依赖附近卷积核。
比如机场跑道边的一小段亮色纹理,单看局部很难判断;结合周围停机坪、道路和其他飞机后,语义会更明确。
SS2D 用较适合长序列的状态空间建模,把这类远距离关系带回小目标特征中。
旁路经过线性层和 SiLU,与主分支做逐元素乘法,形成门控;最后再通过残差连接保留输入信息。它同时照顾局部纹理、全局依赖和训练稳定性。
SS2D 处理后的 HR 特征通过拼接形成输出:
第一项保留线性映射后的浅层融合信息,第二项加入 SS2D 建模得到的二维长距离关系,Concat 将两部分重新合并。LR 分支执行相同过程,因此两路输出都同时包含局部细节与全局上下文。
论文还设计了 EM 增强融合结构,让 LR 与 HR 的隐藏特征继续相互作用。Mamba 在这里用于调度两路视觉特征之间的信息,并不承担独立分类任务。
损失函数也在配合 SR
完整训练目标包含目标存在、定位、分类和额外的超分辨率约束。
L_obj、L_loc 和 L_cls 分别约束目标存在性、边界框定位和类别预测,L_s 约束超分辨率结果。四个权重 lambda_1 至 lambda_4 用于平衡检测任务与图像重建任务,避免某一分支主导联合训练。
超分辨率约束写为:
其中,S 是超分辨率输出,I 是对应输入图像。该项通过像素级二范数限制重建偏差,使 SR 分支提供更稳定的细节特征。
前三项负责检测,额外的 L_s 约束负责重建分支。作者还引入基于 Inner-IoU 的定位优化,通过辅助框改善边界框回归,尤其关注小目标对位置偏差更敏感的问题。
这意味着 SAMYOLO 的提升不是单一模块带来的。
输入、特征融合和训练目标,是一起设计的。
实验结果:
以 YOLOv8s 为基线,多模态 RGB+SR 输入将 mAP50 从 83.4% 提升到 84.8%。在 84.8% 的双流基线上,只加入 SR 模块达到 86.2%,只加入 FM 达到 87.5%,两者同时使用达到 89.2%。
FM 单独带来的增益高于 SR,两者组合时达到最高结果。实验结果表明,细节重建与全局特征融合具有互补作用。
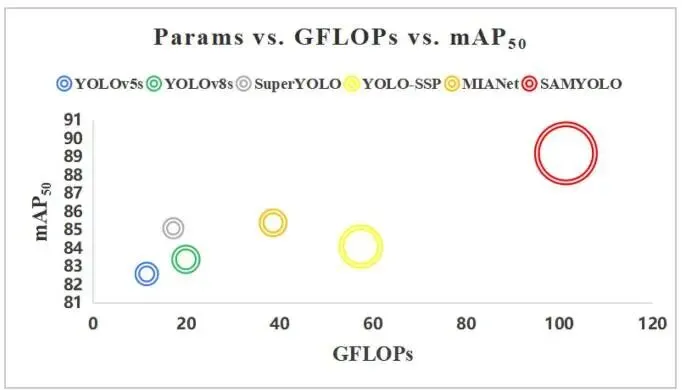
气泡图的纵轴是 mAP50,横轴是 GFLOPs,圆圈大小表示参数量。红色 SAMYOLO 位于最高的 mAP50 区域,同时也处在最右侧;完整 YOLOv8s 版本达到 67.6M 参数和 101.4 GFLOPs,而原始 YOLOv8s 是 11.2M 参数和 19.9 GFLOPs。
SAMYOLO追求的是精度优先,而不是轻量化。
定性结果:
图中各行依次比较 Ground Truth、YOLOv5s、YOLOv8s、SuperYOLO、YOLO-SSP、MIANet 和 SAMYOLO,六列对应不同遥感场景。
在密集停车区、码头船只和车辆紧邻的区域,基础模型容易漏掉边缘目标,或把相邻小目标混在一起。SAMYOLO 在多组场景中给出了更完整的检测框,还识别出部分未被原始标签覆盖的小目标。
检测到“标签之外的目标”可能说明模型更敏感,也可能来自数据标注不完整。判断实际效果时,仍需结合 mAP、误检率和真实部署数据。
方法总结
论文把“恢复细节”和“理解上下文”放进同一个端到端框架。
DEDD 让小目标有更多可辨认信息。FM 通过通道交换连接 RGB 与 SR。SS2D 再用四向扫描补充全局关系。三者沿着一条完整的信息流协同,而不是孤立地堆叠模块。
因此,SAMYOLO 更适合遥感监测、航空影像分析等漏检成本较高、算力相对充足的场景。若要部署到边缘设备,下一步重点应是轻量化 SR、压缩 FM,以及减少双分支推理开销。
免责声明:本文仅用于学术交流与技术学习,内容基于公开论文及相关资料整理。如有理解偏差、内容错误,或涉及版权、侵权等问题,欢迎联系作者更正或删除。
搜一搜关注作者


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
