南京大学Journal of Hydrology:中国洪峰变化及气候驱动机制
- 2026-06-24 06:51:54

点击上方蓝色字关注我们~
本文转自:生态地理-顶刊解剖实验室
Journal of Hydrology 近期发表题为“Spatially coherent changes in Chinese annual flood peaks revealed by a consensus-based machine learning framework for regionalization”的文章。第一单位为南京大学。doi: https://doi.org/10.1016/j.jhydrol.2025.134665作者邮箱:yanglong@nju.edu.cn标签:#洪水区划 #气候变化 #年最大洪水 #共识聚类 #机器学习 #多层感知机

本文内容速览:
1. 提出科学问题 2. 文章的主要结论 3. 分析过程和方法 4. 研究的局限性
1. 提出科学问题
1.1 研究领域现状
洪水区划是评估区域尺度洪水行为和支持洪水风险管理的关键工具。其核心目标是识别出水文特征相似的区域,即“同质区”。传统区划方法通常依赖于流域的物理属性、气象条件或洪水统计特征进行分类。然而,这些方法存在显著的不确定性。一个主要挑战在于,相似性指标的选择具有一定的主观性,不同的指标组合可能导致迥异的区划结果。此外,现有研究在处理无资料流域(ungauged catchments)时,常假设地理上的邻近等同于水文上的相似,但这忽略了地表特性和气候驱动因素在空间上的复杂异质性,使得区划结果的可靠性受到限制。因此,如何客观、稳健地进行洪水区划,特别是如何减少指标选择带来的不确定性并科学地覆盖无资料地区,是当前水文学研究面临的难题。
1.2 本文要解决的关键科学问题
基于上述研究背景,本文旨在回答以下三个核心科学问题:
• 问题 1: 如何构建一个能够有效减少指标选择不确定性的区划框架,从而在中国这样一个广阔且水文气候条件复杂的区域,客观地识别出水文行为相似且空间格局连贯的同质性洪水区? • 问题 2: 在1980-2017年期间,中国年最大洪水(Annual Maximum Flood)的峰值流量和发生时间在区域尺度上呈现出怎样的长期变化趋势? • 问题 3: 驱动这些区域性洪水变化的主要水文气象因子是什么?不同区域的主导驱动因子(如降雨、融雪、土壤湿度)是否存在差异?
1.3 研究的理论/现实意义
本文的理论意义在于提出了一个创新的、基于共识聚类的机器学习洪水区划框架。该框架通过集合多种聚类结果来获取一个稳健的“共识”解,有效克服了传统方法中单一指标或模型带来的偏差和不确定性。在现实意义上,这项研究首次对中国全国范围内的洪水情势进行了全面的、数据驱动的评估,揭示了过去近四十年来洪水特征的区域性变化规律及其背后的气候驱动机制。这些发现为理解气候变化下的洪水响应提供了科学依据,也为制定更具针对性的、适应性的洪水风险管理策略提供了关键信息,对水资源规划和防灾减灾具有重要的指导价值。
2. 文章的主要结论
本文通过构建一个新颖的机器学习框架,对中国1980-2017年的年最大洪水数据进行了系统的区域化分析,得出了以下主要结论:
• 结论 1: 成功将中国划分为20个水文同质性洪水区。研究发现,在进行洪水区划时,表征气候态平均洪水情势的指标(如多年平均的归一化洪峰流量)比表征年际变率的指标(如洪峰流量的变异系数)更为重要。其中,纬度和平均归一化洪峰流量是划分区域最关键的两个因素,这与夏季风的纬向推进规律紧密相关。 • 结论 2: 在全国尺度上,中国年最大洪水在1980-2017年间呈现出显著的洪峰流量减小(20个区域中的15个)和发生时间推迟(20个区域中的15个)的总体趋势。通过区域化聚合分析发现,洪水序列在区域尺度上表现出比单个站点更强的长期持续性(即赫斯特指数更高),表明区域性趋势比局部趋势更为稳定和明确,这凸显了洪水区划在识别长期变化信号中的效用。 • 结论 3: 区域性的洪水变化主要是气候驱动的结果。具体而言,降雨变化是影响大部分区域洪峰流量和发生时间的主导因素。在东部地区,土壤湿度的变化对洪峰流量的减小趋势有重要影响;而在西北地区,洪水驱动机制正经历从融雪主导向降雨主导的转变,这种转变与该地区洪水特征的变化密切相关。
3. 分析过程和方法
本文的核心是构建并应用了一个集成了多种机器学习技术的洪水区划框架,其逻辑流程清晰,旨在解决传统区划方法的不确定性问题,并实现对有数据、数据稀疏及无数据流域的全面覆盖。
整个分析过程可以概括为:数据准备 -> 三步式区划框架 -> 区域洪水特征与驱动力分析。
1. 数据准备与指标选取研究使用了覆盖全国的1111个水文站1980-2017年的年最大洪峰流量及发生日期数据。一个关键的预处理步骤是,作者根据记录长度将站点分为“数据充分”站(626个)和“数据不足”站(485个),为后续区别处理奠定基础。
为了进行区划,作者选取了6个直接从观测数据中计算得出的洪水指标:
• 平均洪水发生日期 和 其年际变率:反映洪水发生的季节性规律。 • 平均归一化洪峰流量 和 其年际变率:反映洪水的平均量级。 • 洪水比率(10年一遇洪水与平均洪水的比值):反映极端洪水的相对强度。 • 洪水同步性:反映区域内洪水同时发生的程度。
这种直接使用洪水观测指标而非间接的流域物理属性(如坡度、土壤类型)的做法,旨在让数据本身说话,避免引入过多先验假设。
2. 创新的三步式区划框架这是本文方法论的核心,通过一个三阶段的流程,逐步将全国划分为同质区。
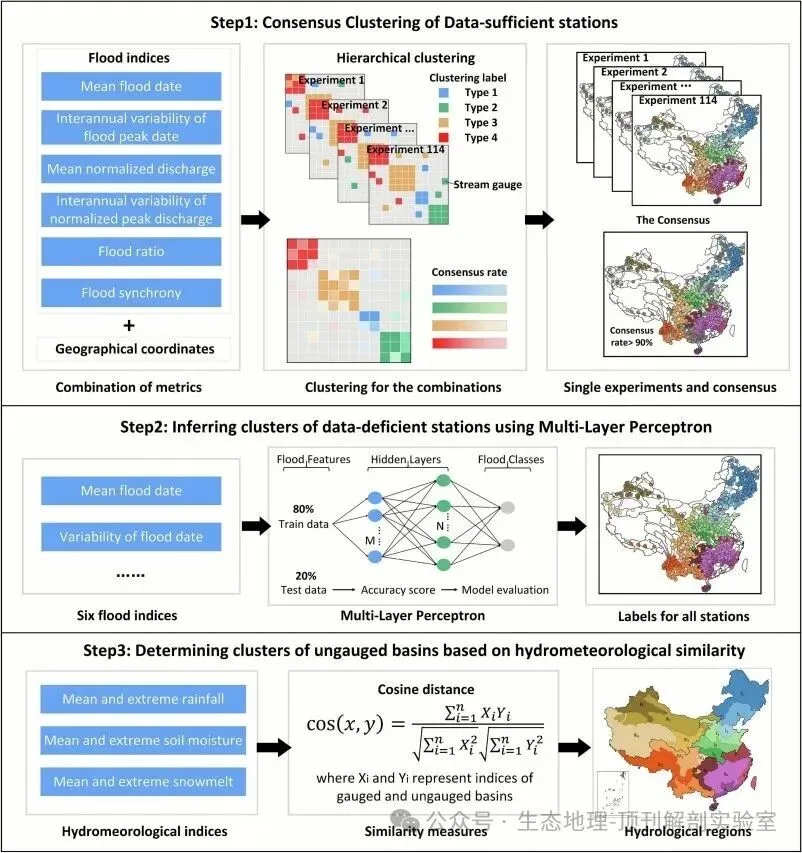
• Step 1: 对数据充分站进行共识聚类 (Consensus Clustering) • 目标:为数据质量最高的站点找到一个最稳定、最可信的分类结果,作为后续步骤的“基石”。 • 挑战:单一的聚类算法和指标组合会产生不确定的结果。 • 解决方案:本文采用共识聚类这一核心技术。它并非只做一次聚类,而是进行了114次独立的层次聚类实验,每次实验使用不同的洪水指标组合。 • 实现思路: • 方法优势:这种方法极大地降低了对特定指标组合的依赖,得到的“核心簇”是经历过多种“考验”的稳健结果,有效减少了区划的不确定性。 1. 将6个洪水指标和地理坐标进行不同组合,形成多个特征集。 2. 对每个特征集,使用层次聚类算法对626个数据充分站进行聚类。 3. 通过轮廓系数(Silhouette score)和形状因子(shape factor)评估每次聚类结果的质量,筛选出效果好的实验。 4. 统计所有合格实验的结果,如果两个站点在超过90%的实验中都被分到同一类,那么它们就被认为属于同一个“共识”核心簇。 • Step 2: 利用多层感知机 (MLP) 推断数据不足站的归属 • 目标:将其余485个数据记录较短的站点划分到已建立的核心簇中。 • 方法:将问题转化为一个监督学习分类任务。 • 实现思路: 1. 训练模型:使用第一步得到的“核心簇”站点作为训练集。其中,每个站点的6个洪水指标是模型的输入特征(X),该站点所属的核心簇标签是输出(Y)。2- 构建分类器:训练一个*多层感知机(MLP)*神经网络模型,学习洪水指标与区域归属之间的非线性关系。3- 预测分类:将数据不足站点的洪水指标输入到训练好的MLP模型中,模型会预测出它们最可能属于哪个洪水区域。 • Step 3: 基于水文气象相似性确定无资料流域的分区 • 目标:实现全国范围的“无缝”区划,覆盖所有未设站的流域。 • 方法:不再依赖洪水观测数据,而是转向更易获取的气候数据。 • 实现思路: • 方法优势:该方法基于一个合理的水文假设——相似的气候条件产生相似的洪水过程,从而科学地完成了对无资料区域的推断,比简单的地理邻近法更为可靠。 1. 为每个无资料流域和已划分的洪水区域,提取其平均的气候特征(如降雨、融雪、土壤湿度)。 2. 计算每个无资料流域的气候特征向量与各个洪水区域平均气候特征向量之间的余弦相似度。 3. 将该无资料流域分配给与其气候特征最相似的那个洪水区域。
3. 区域洪水特征与驱动力分析在完成区划后,文章对每个区域的洪水特征进行了深入分析。
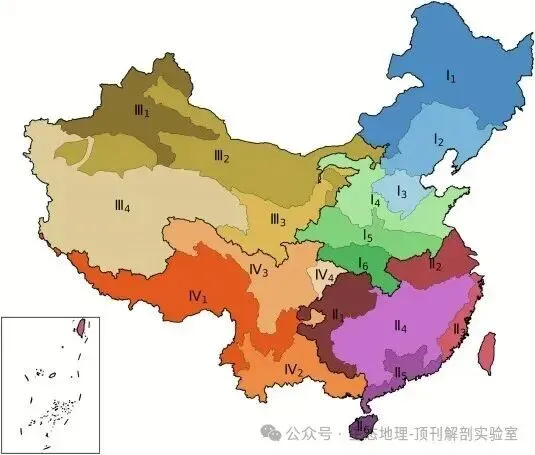
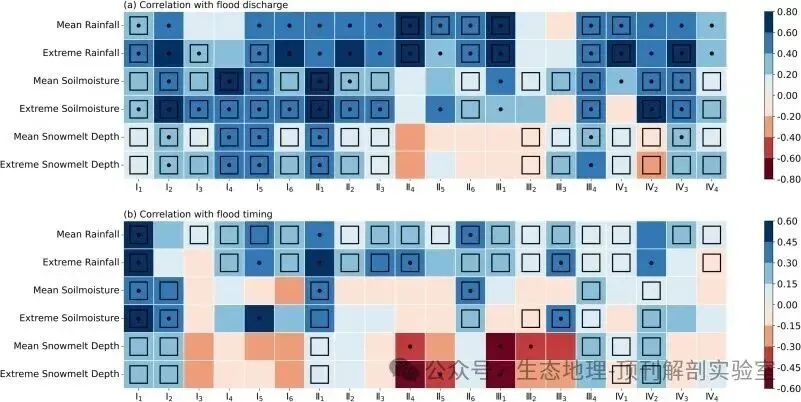
• 区域特征分析:通过冗余分析(RDA)评估了不同指标在区划中的重要性。结果(图6)显示,纬度、平均归一化流量等气候态指标贡献了大部分方差,证明了平均气候状况是洪水分区的主导因素。 • 趋势与持续性分析: • 对每个区域内的所有站点序列进行整合,形成区域尺度的复合时间序列。 • 使用非参数的Theil-Sen斜率估计和Mann-Kendall检验来分析1980-2017年间区域洪峰流量(图7)和发生时间(图8)的趋势。 • 计算*赫斯特指数(Hurst exponent)*来评估趋势的长期持续性。结果(图9)表明,区域复合序列的赫斯特指数远高于单个站点,说明区域化分析能够滤除局部噪声,揭示更稳定、更具持续性的长期信号。
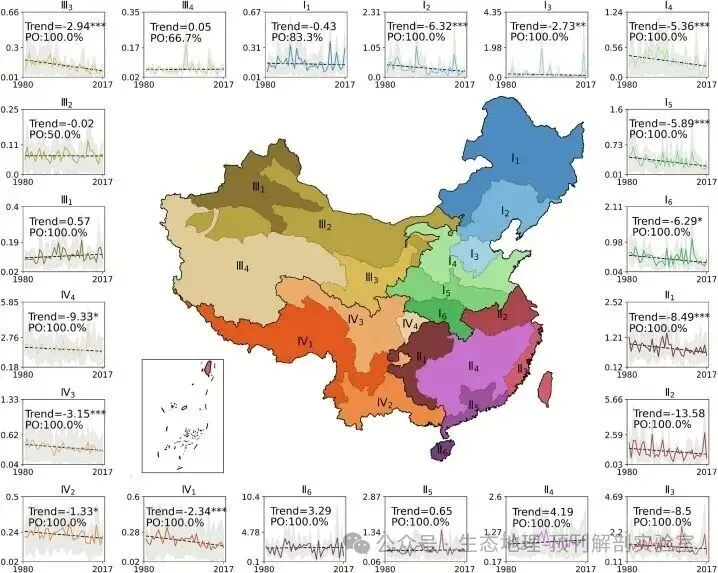
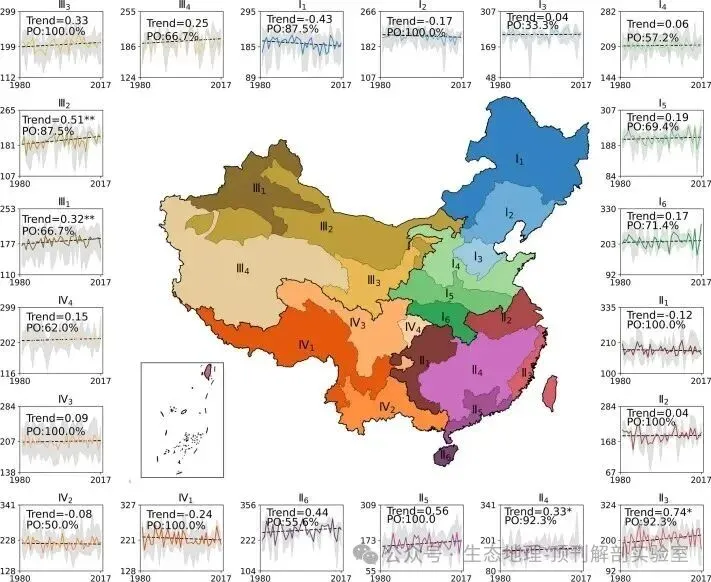
• 驱动力识别: • 为探究洪水变化的驱动力,作者计算了每个区域的洪水复合序列与多种水文气象变量(年均/极端降雨、年均/极端土壤湿度、年均/极端融雪)序列之间的斯皮尔曼等级相关系数。 • 选择与洪水变化趋势方向一致且相关性最高的那个气象变量,作为该区域洪水变化的主导驱动因子(图10)。
通过上述流程,文章不仅提出了一个方法学上的创新,还系统地揭示了中国洪水的时空演变规律及其背后的物理机制,形成了一个从方法构建到科学发现的完整闭环。
4. 研究的局限性
文章在讨论部分也客观地指出了研究中存在的一些局限性,这对于我们理解研究的边界和未来方向很有帮助。
• 人类活动因素的简化处理:本研究在区划过程中未直接包含人类活动(如修建水库、城市化、土地利用变化)的量化指标。作者的理由是,所选的洪水指标在空间上呈现出与气候格局高度一致的模式,表明其主要受大尺度气候背景控制,而非局地的人类活动。尽管如此,作者也承认人类活动在局部地区对洪水过程有重要影响,但本文的框架侧重于捕捉全国尺度的气候驱动信号。 • 洪水指标的局限性:由于数据可获得性的限制,本研究仅使用了年最大洪水的峰值流量和发生日期两个属性。其他能够描述洪水过程的指标,如洪水历时、洪量等,未能被纳入分析框架。这可能会限制对洪水特征的全面刻画。 • 驱动力分析的不确定性:对于少数几个区域,研究未能识别出明确的主导驱动因子。作者推测这可能是因为这些区域内的水文站点较为稀疏,无法完全捕捉水文气象强迫场的空间变异性,导致信号被平滑或抵消。

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 双警报齐发!南京的雨有多大?江苏出梅最新消息
- 南京给江苏争气了,江苏首个跻身市值百亿梯队的先进制造企业站出来了,那就是智能装备相关龙头!
- 江苏南京私立学校教师招聘12人公告
- 土木君转行高校行政岗位——南京艺术学院
- 【南京小人书】19| 朝堂骂他胆小、将领不肯救援,晚清绝境只剩他一人硬扛
- 南京市六合区力丰人力资源服务有限公司面向社会公开招聘拟录用人员公示
- 粉花碧桃,拍摄于南京
- 没有人能拒绝南京!中山陵392级台阶的教训、夫子庙美食避雷大全、玄武湖日落机位,本地人带路3天2夜终极攻略
- 南京科技工作者之家出席2026南京·中韩大健康与生物环保产业技术合作交流大会
- 南京给全国打了个样,印度人不能再破坏我们的社会规则了
