
🐉 龙哥读论文知识星球来了!还在为视频去噪的纹理细节和运动模糊烦恼吗?想深入探讨更多图像/视频恢复的“分而治之”妙招?星球每日更新AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文精准地抓住了自监督视频去噪领域一个长期存在的“两难困境”,并提出了一个非常巧妙且有效的“分而治之”解决方案。其核心思想——时空解耦——不仅逻辑清晰,而且实验效果拔群,在多个基准测试上超越了现有自监督方法,甚至在某些指标上媲美监督学习。对于从事图像/视频恢复、自监督学习的研究者来说,这篇论文在方法论和工程实践上都具有很高的参考价值。
原论文信息如下:
论文标题:
Frames2Residual: Spatiotemporal Decoupling for Self-Supervised Video Denoising
发表日期:
2026年03月
发表单位:
南京大学, 南洋理工大学
原文链接:
https://arxiv.org/pdf/2603.10417v1.pdf
想象一下,你用手机在昏暗的餐厅拍了一段美食视频,想发朋友圈,结果画面全是噪点,跟撒了胡椒面似的。你想用AI软件去噪,却发现要么运动物体拖出了鬼影,要么食物的纹理细节全被抹平了,看起来像一坨浆糊。😒
这就是视频去噪的核心难题:如何在去除随机噪点的同时,保住清晰的纹理细节和稳定的运动画面?对于需要干净-有噪点成对数据的监督学习方法来说,这已经够难了。但在现实世界,比如生物荧光显微镜观测活细胞,你根本拿不到绝对干净的“标准答案”视频。这时,只能依靠自监督学习——仅凭有噪点的视频自己教自己。
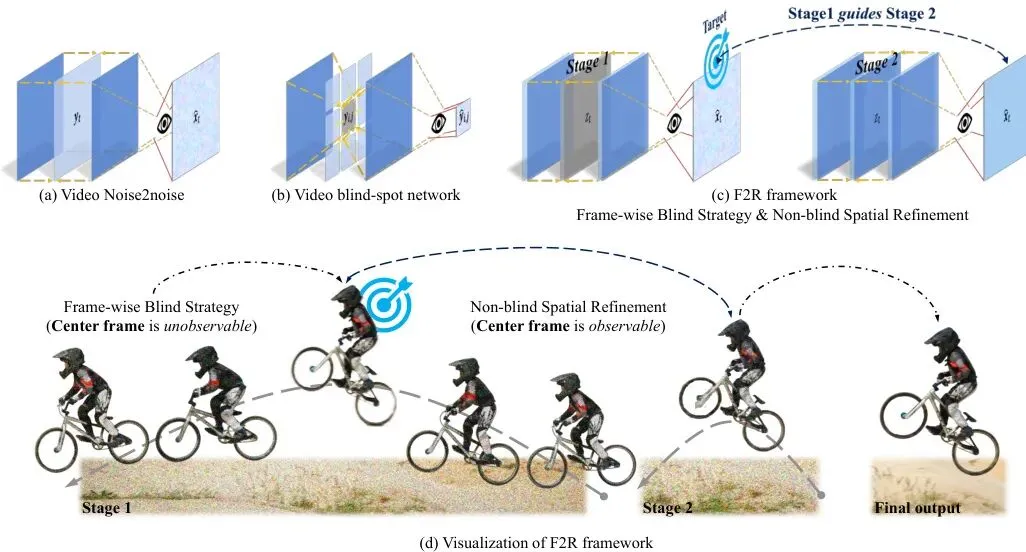
现有的自监督视频去噪方法,仿佛陷入了“鱼与熊掌不可兼得”的困境。最近,来自南京大学和南洋理工大学的研究团队提出了一个巧妙的解法:Frames2Residual (F2R)。他们像一位高明的厨师,把“保持稳定”和“恢复纹理”这两道难题分开处理,最后再完美融合,做出了色香味俱全的“去噪大餐”。😏自监督视频去噪的“两难困境”:要独立还是要纹理?
要理解F2R的妙处,得先看看前辈们踩过的坑。自监督视频去噪主要有两大流派,它们各自带着“先天残疾”:
这个流派的思想是:既然没有干净画面,那就用另一帧有噪点的画面当“老师”。具体做法是,估算相邻帧到当前帧的光流(Optical Flow,描述像素从一帧运动到另一帧的方向和距离),然后把相邻帧“掰弯”(warp)对齐到当前帧的位置,用这个对齐后的有噪点帧作为监督信号。
问题来了:“掰弯”图像需要进行插值计算,这个过程本身就会破坏噪声的统计特性,并且如果光流估计不准,还会引入严重的“鬼影”或模糊。这相当于让一个“口齿不清”的老师来教你标准发音,结果可想而知。😑
流派二:基于盲点的“Blind-Spot Network”思路
这个流派学聪明了,它彻底避免了对齐操作。它的核心规则是:预测当前帧某个像素时,绝不允许看到这个像素本身的有噪点值,只能看它周围时空邻域的信息。这就像蒙着眼睛,只靠触摸周围环境来猜测中间放了什么。这种方法在数学上能严格保证噪声的独立性,训练信号是“干净”的。
代价呢?它为了“避嫌”,也主动放弃了最能判断纹理细节的直接空间证据。这导致模型学到的特征存在固有的“像素不连续性”,切断了像素与其周围时空邻域之间至关重要的时空相关性。最终结果就是,噪声去掉了,但纹理细节也大量丢失,画面看起来“肉肉的”,不清晰。
图1:自监督视频去噪范式在推理阶段的对比。(a) 视频 Noise2Noise。基于对齐的监督违反了噪声独立性并导致对齐伪影,造成细节模糊。(b) 视频盲点网络。固有的像素不连续性切断了重要的时空相关性,导致纹理丢失。(c) 提出的 F2R 框架。F2R 采用联合空间输入。(d) F2R 框架可视化。灰色虚线说明了阶段1建立的时序一致性。最终输出在保持时序一致性的同时获得了空间特异性,从而有效恢复了时空相关性。
看明白了吗?传统方法陷入了两难困境:想保证噪声独立性(盲点约束),就得牺牲纹理恢复;想恢复纹理,就可能引入对齐误差破坏独立性。这俩目标在单阶段框架里简直就是死对头。时空解耦:F2R如何“分而治之”?
南京大学和南洋理工大学的研究团队思路清奇:既然一个模型同时干两件冲突的事会精神分裂,那咱就分两个阶段,找两个模型来干!这就是Frames2Residual (F2R)的核心——时空解耦。
第一阶段:盲时序估计器。目标:只利用相邻帧的信息,学习帧与帧之间稳定的、一致的信号部分(即时间一致性)。它严格遵守盲点规则,完全看不到要处理的当前帧,因此学到的特征纯粹是“时间流”上的共识,不受当前帧具体噪声和纹理的干扰。这相当于先建立一个稳定的、但可能有点模糊的“骨架”。
第二阶段:非盲空间细化器。目标:在已经有时序稳定“骨架”的基础上,安全地引入当前帧的详细信息,把丢失的高频空间纹理“血肉”给补回来。因为第一阶段已经提供了一个可靠的参考(锚点),第二阶段就可以放开手脚,充分利用当前帧的直接空间证据进行精细修复,而不用担心破坏已经建立起来的时间稳定性。
这个“分而治之”的策略还有一个关键巧思:残差学习。F2R并不直接预测干净的图像,而是预测一个“残差”。它先利用一个预训练好的单图像去噪器(比如NAFNet)对每一帧进行初步去噪,得到一个基础的、静态结构清晰的图像。这个图像去掉了大部分噪声,但也平滑掉了很多纹理细节。F2R要学的,就是这个图像去噪器遗漏掉的高频残差信号。这样,模型的任务就从“无中生有”变成了“查漏补缺”,大大降低了学习难度。
两阶段策略详解:从盲估计到精修复
光有宏观思路还不够,我们看看F2R具体是怎么实操的。请注意,两个阶段只在训练时存在,推理时只用第二阶段训练好的那个“空间细化器”,非常高效。
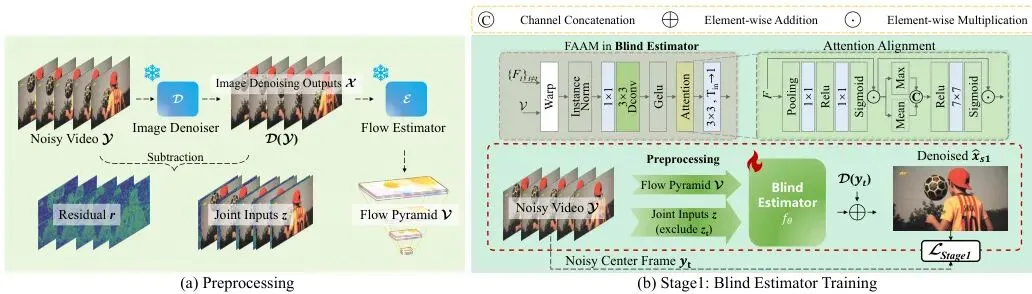
图2:逐帧盲策略。(a) 输入构造的预处理。(b) 盲估计器训练。流金字塔是通过对基础流进行下采样并在每一级将其幅度减半来构建的。
首先,对每一帧有噪图像y,用预训练的图像去噪器D处理,得到基础去噪结果x̂和对应的残差r = y - x̂。然后将x̂和r拼接起来,作为联合输入z。x̂提供清晰的结构参考,r蕴含高频细节线索。
在训练“盲估计器”时,采用“逐帧盲”策略:输入是当前帧t之外的所有相邻帧的联合输入{z_i}_{i≠t},目标是要预测当前帧的残差r_t。因为看不到当前帧,模型被迫从周围帧中去挖掘一致的时间信息。
为了帮助模型融合时间信息,本文使用了预计算的光流(来自预训练的光流估计器如PWC-Net)。但直接做图像扭曲(warp)会引入伪影。因此,F2R设计了一个流引导注意力对齐模块(FAAM, Flow-Guided Attention Alignment Module)。它先用光流将邻帧特征大致对齐,然后通过通道注意力和空间注意力机制,动态选择可靠的帧并过滤掉对齐带来的失真区域,最后融合出一个纯净的时序一致特征。这个阶段的损失函数就是预测的残差和真实残差之间的L1损失:
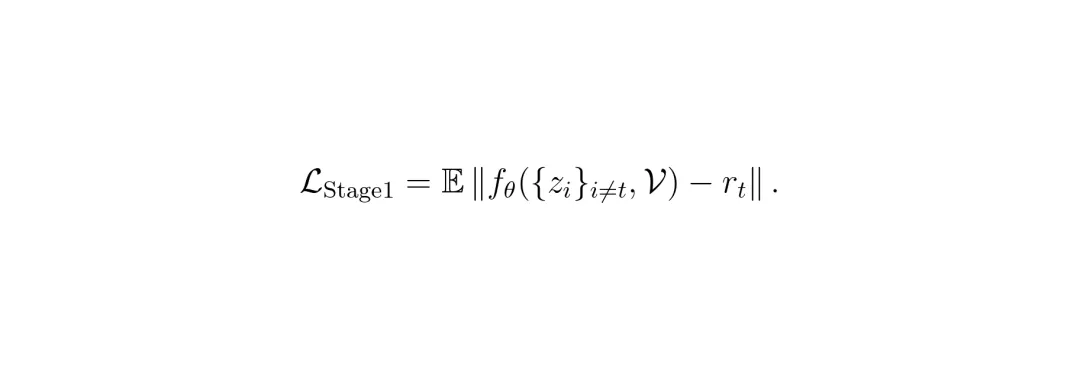 第一阶段损失函数。L_Stage1 = E[ || f_θ({z_i}_{i≠t}, V) - r_t || ]。其中f_θ是盲估计器,V是光流,r_t是当前帧的真实残差。
训练完成后,第一阶段输出一个时序一致的锚点:x̂_s1 = x̂_t + f_θ(...)。这个锚点画面稳定,但缺少当前帧独有的精细纹理。
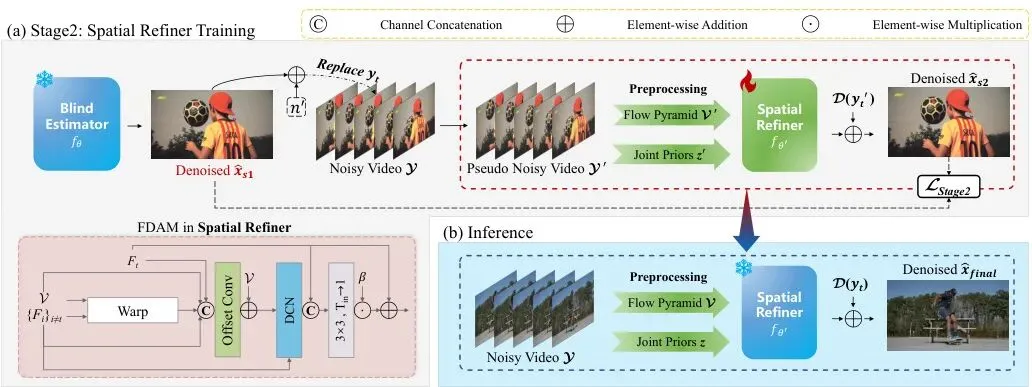
图3:(a) 空间细化器的训练和(b)推理阶段。值得注意的是,预处理操作在两个阶段严格相同。重破坏噪声n'是从已知噪声模型中采样的。
第二阶段的目标是训练一个“空间细化器”,让它学习如何把第一阶段锚点里缺失的纹理补回来。这里用了一个非常巧妙的“重破坏”策略来构造自监督信号:
1. 把第一阶段得到的干净锚点x̂_s1,用已知的噪声模型(比如高斯噪声)再破坏一次,得到y'_t = x̂_s1 + n'。
2. 用这个“重破坏”的锚点替换掉原始视频中的当前有噪帧y_t,构造一个新的伪有噪序列。
3. 对这个伪有噪序列的当前帧y'_t,再次用那个固定的图像去噪器D处理,得到D(y'_t)。
4. 计算新的目标残差:r'_t = x̂_s1 - D(y'_t)。
第一阶段损失函数。L_Stage1 = E[ || f_θ({z_i}_{i≠t}, V) - r_t || ]。其中f_θ是盲估计器,V是光流,r_t是当前帧的真实残差。
训练完成后,第一阶段输出一个时序一致的锚点:x̂_s1 = x̂_t + f_θ(...)。这个锚点画面稳定,但缺少当前帧独有的精细纹理。
图3:(a) 空间细化器的训练和(b)推理阶段。值得注意的是,预处理操作在两个阶段严格相同。重破坏噪声n'是从已知噪声模型中采样的。
第二阶段的目标是训练一个“空间细化器”,让它学习如何把第一阶段锚点里缺失的纹理补回来。这里用了一个非常巧妙的“重破坏”策略来构造自监督信号:
1. 把第一阶段得到的干净锚点x̂_s1,用已知的噪声模型(比如高斯噪声)再破坏一次,得到y'_t = x̂_s1 + n'。
2. 用这个“重破坏”的锚点替换掉原始视频中的当前有噪帧y_t,构造一个新的伪有噪序列。
3. 对这个伪有噪序列的当前帧y'_t,再次用那个固定的图像去噪器D处理,得到D(y'_t)。
4. 计算新的目标残差:r'_t = x̂_s1 - D(y'_t)。
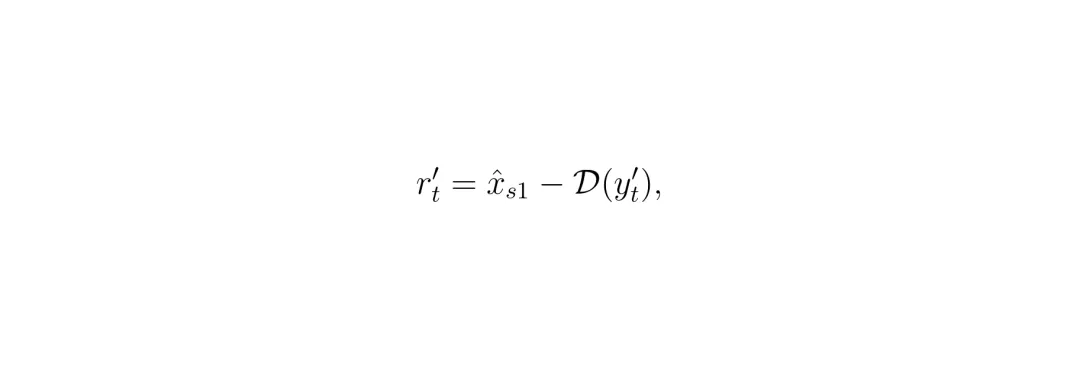 第二阶段的目标残差。r'_t = x̂_s1 - D(y'_t)。即用第一阶段锚点减去对重破坏帧的单图像去噪结果,得到需要学习的纹理残差。
这个r'_t精确地代表了图像去噪器D在处理时会系统性丢失的那部分高频纹理。现在,“空间细化器”可以光明正大地看到当前帧y'_t了(非盲)。它的任务就是融合全部帧的信息(包括当前帧的直接空间证据),去预测这个残差r'_t。损失函数如下:
第二阶段的目标残差。r'_t = x̂_s1 - D(y'_t)。即用第一阶段锚点减去对重破坏帧的单图像去噪结果,得到需要学习的纹理残差。
这个r'_t精确地代表了图像去噪器D在处理时会系统性丢失的那部分高频纹理。现在,“空间细化器”可以光明正大地看到当前帧y'_t了(非盲)。它的任务就是融合全部帧的信息(包括当前帧的直接空间证据),去预测这个残差r'_t。损失函数如下:
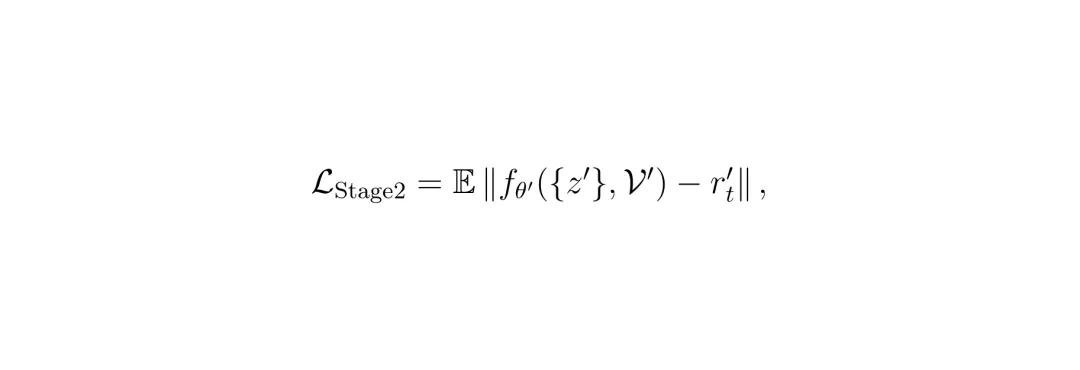 第二阶段损失函数。L_Stage2 = E[ || f_θ‘({z‘}, V‘) - r‘_t || ]。其中f_θ‘是空间细化器。
由于能看见当前帧,第二阶段采用了一个更强的对齐模块——流引导可变形对齐模块(FDAM, Flow-Guided Deformable Alignment Module)。它利用可变形卷积(DCN)来学习更精细的亚像素级偏移,以光流为初始偏移,进一步修正对齐误差,从而能更好地恢复高频细节。
最终,在推理时,只需要使用训练好的空间细化器f_θ‘,输入原始的联合输入{z}和光流V,预测出最终残差,然后加上单图像去噪的结果,就得到了既稳定又清晰的去噪视频:
第二阶段损失函数。L_Stage2 = E[ || f_θ‘({z‘}, V‘) - r‘_t || ]。其中f_θ‘是空间细化器。
由于能看见当前帧,第二阶段采用了一个更强的对齐模块——流引导可变形对齐模块(FDAM, Flow-Guided Deformable Alignment Module)。它利用可变形卷积(DCN)来学习更精细的亚像素级偏移,以光流为初始偏移,进一步修正对齐误差,从而能更好地恢复高频细节。
最终,在推理时,只需要使用训练好的空间细化器f_θ‘,输入原始的联合输入{z}和光流V,预测出最终残差,然后加上单图像去噪的结果,就得到了既稳定又清晰的去噪视频:
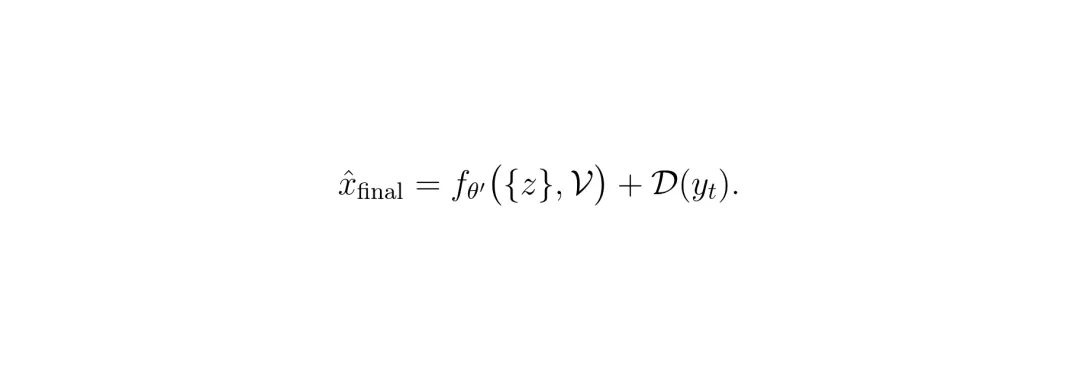 最终输出。x̂_final = f_θ‘({z}, V) + D(y_t)。
最终输出。x̂_final = f_θ‘({z}, V) + D(y_t)。
实验结果:全面超越,甚至媲美监督方法
理论说得天花乱坠,是骡子是马还得拉出来溜溜。F2R在合成高斯噪声(DAVIS, Set8数据集)和真实RAW视频噪声(CRVD数据集)上都进行了测试,对比了当前最好的自监督方法(如UDVD, RDRF, TAP等),甚至拉来了一些监督学习方法当“陪练”。
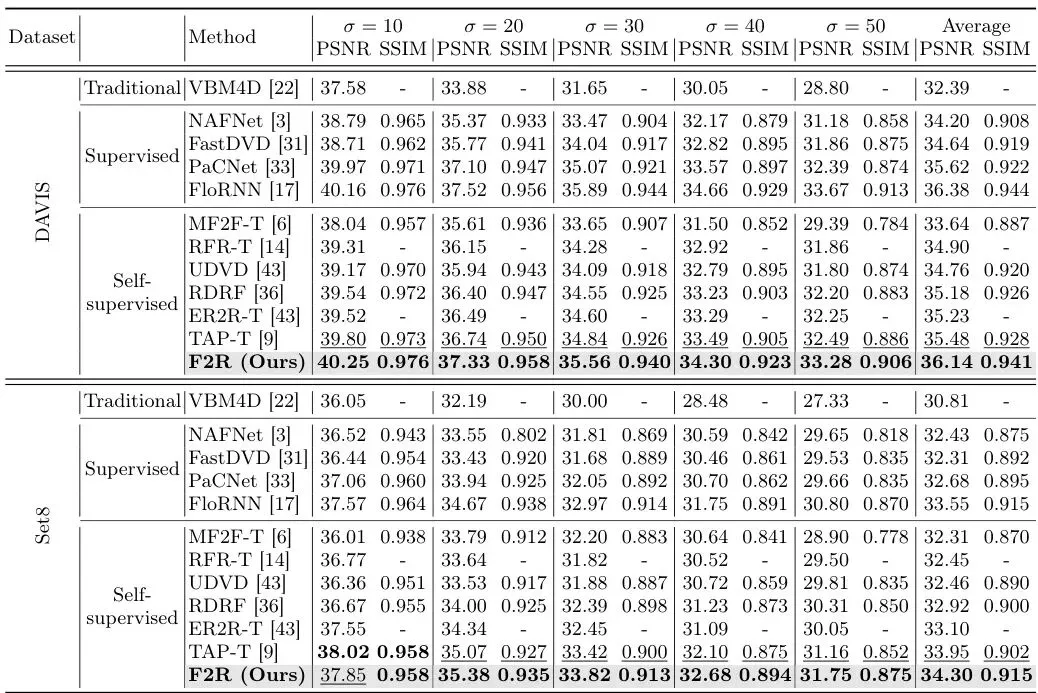
表1:在不同噪声水平下,DAVIS和Set8数据集上的定量比较(PSNR/SSIM)。无监督方法的最佳结果加粗,次佳结果加下划线。
在合成高斯噪声上,F2R全面领先所有无监督方法。在DAVIS数据集上平均PSNR达到36.14 dB,比最近的强有力竞争者TAP高出0.66 dB。更令人惊喜的是,在Set8数据集上,F2R(34.30 dB)甚至超越了监督方法FloRNN(33.55 dB),显著缩小了有监督和无监督方法之间的性能鸿沟。👏
图4:在噪声水平σ=30下,DAVIS(上)和Set8(下)数据集上的视觉对比。我们将F2R与有监督(FastDVDNet, FloRNN, NAFNet)和无监督(UDVD, TAP)方法进行比较,每个补丁下方显示了PSNR/SSIM指标。黄色箭头指示用于详细纹理比较的区域。†表示有监督方法。
视觉对比更是一目了然。在图4中,无论是文本的清晰边缘(“maker Gebr. Verkooyen”),还是滑雪者裤子上复杂的动态织物纹理,F2R都恢复得最好,既干净又锐利。而其他方法要么模糊,要么纹理丢失严重。
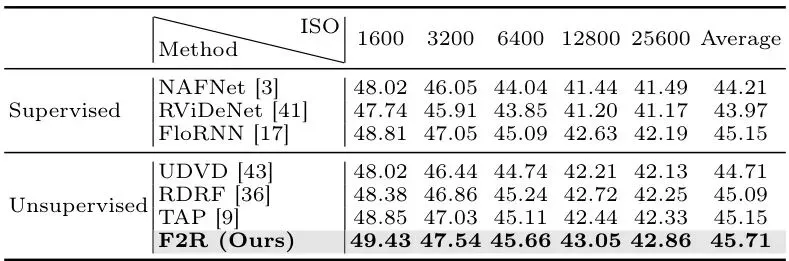
表2:CRVD室内数据集在不同ISO级别下的定量比较。无监督方法中的最佳结果加粗。
在处理复杂的真实传感器噪声时,F2R的优势依然稳固。在CRVD数据集上,它比最好的无监督方法TAP高出0.56 dB,并且再次超越了监督方法FloRNN。这表明F2R的解耦策略和残差学习对于泛化到未知的真实噪声分布也非常有效。
图5:CRVD室内数据集上的视觉对比。结果已使用[41]中提供的预训练ISP转换为sRGB域以便可视化。黄色箭头指示用于详细纹理比较的区域。†表示有监督方法。
从图5的视觉结果看,在昏暗室内场景中,F2R成功恢复了窗框的清晰线条和墙面的真实质感,效果最接近干净的真实画面。
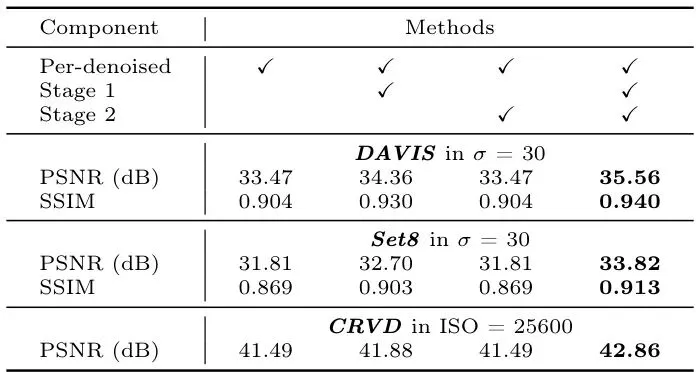
论文还进行了详尽的消融实验,证明了每个阶段都是不可或缺的。如果只用第一阶段,画面稳定但纹理模糊;如果跳过第一阶段直接用第二阶段,模型会学到一个毫无意义的恒等映射。只有两阶段协同工作,才能达到最佳效果。
图6:F2R中间阶段的视觉消融。在Set8的快速运动摩托车序列上评估,噪声水平σ=30。阶段2表示阶段1和阶段2级联训练后,由f_θ‘去噪的结果。
表3:F2R中各个阶段的影响。我们研究了阶段1和阶段2的贡献。请注意,对于仅‘阶段2’的设置,我们直接使用初始联合输入来执行重破坏。方法启示:解耦思想与先验利用的价值
F2R的成功,给自监督视频处理乃至更广泛的视觉任务提供了两个非常重要的启示:
1. “分而治之”的解耦思想:当单一模型面临相互冲突的优化目标时(如“独立vs纹理”),强行捏合往往导致性能妥协。F2R通过巧妙的两阶段时空解耦,让每个阶段专注于解决一个子问题,最后再整合,实现了1+1>2的效果。这种思想可以迁移到其他存在类似“困境”的任务中。
2. 高效利用强大先验:F2R没有从头开始蛮干,而是聪明地利用了现成的、成熟的单图像去噪器和光流估计器作为先验。这相当于站在巨人的肩膀上,让视频去噪模型只需要学习“查漏补缺”和“时空融合”这些更高级、更专有的任务,大大降低了学习难度,提升了效率和性能。这是一种非常务实的工程哲学。
龙迷三问
什么是“时空相关性”?为什么它重要?时空相关性指的是视频中一个像素点与其在时间(前后帧)和空间(周围像素)上邻居之间的结构连续性。例如,物体边缘在连续帧中应该平滑移动,纹理在局部区域内应该连贯。保持这种相关性是视频看起来自然、清晰、无伪影的关键。传统盲点网络为了噪声独立性切断了这种联系,导致纹理丢失。
为什么F2R要采用“残差学习”而不是直接预测干净图像?这是一个降低任务难度的策略。直接从有噪视频预测绝对干净的图像非常困难,尤其是在没有真值监督的情况下。而利用一个强大的单图像去噪器先获得一个“基线”,F2R只需要预测这个基线遗漏的“残差”(主要是高频纹理)。这样,任务从“无中生有”变成了相对容易的“查漏补缺”,模型更容易学习和收敛。
F2R依赖外部预训练模型(图像去噪器、光流器),这是缺点吗?这可以看作是一个“权衡”。依赖外部模型确实增加了部署的复杂性和对先验质量的敏感性。但另一方面,这是利用领域内已有SOTA成果的聪明做法,避免了重复造轮子,让F2R能专注于解决视频特有的时空融合难题,从而取得了性能的显著提升。在实际应用中,只要这些外部模型稳定可靠,这种依赖是可以接受的。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将时空解耦和残差学习结合,以两阶段方式明确解决自监督视频去噪中的固有冲突,思路清晰且新颖,不是简单的堆砌模块。实验合理度:★★★★☆
在合成和真实数据集上进行了充分验证,对比了当前主流无监督及部分监督方法,消融实验完整,证明了各组成部分的必要性,结论可信。学术研究价值:★★★★☆
为解决自监督学习中的“目标冲突”问题提供了一个经典的“解耦”范例,其方法论对视频恢复、甚至其他自监督任务有启发意义。利用强大先验聚焦核心问题的思路也值得借鉴。稳定性:★★★☆☆
方法本身逻辑闭环,但性能一定程度上依赖于外部预训练模型(图像去噪器、光流器)的质量。如果这些先验在特定场景(如极端运动、特殊噪声)下失效,可能影响F2R的最终表现。适应性以及泛化能力:★★★★☆
在合成高斯噪声和不同ISO的真实传感器噪声上都表现优异,显示了较强的泛化能力。其解耦思想本身也适用于不同噪声模型。硬件需求及成本:★★★☆☆
推理时只需运行一个U-Net模型和两个外部预训练模型(单图去噪、光流)。计算量主要来自这两个外部模型和U-Net本身的推理,相较于一些复杂的视频Transformer模型更轻量,但对实时应用仍有挑战。复现难度:★★★☆☆
论文描述清晰,但复现需要首先获得或训练性能达标的图像去噪器和光流估计器,并正确实现两阶段训练流程,有一定工程门槛。代码若开源将大幅降低难度。产品化成熟度:★★★☆☆
方法有效,在画质要求高的专业场景(如科研影像处理、影视后期)有直接应用潜力。但依赖于其他模型且非端到端,在消费级产品(如手机)中集成需要进一步的优化和打包。可能的问题:
训练过程涉及两阶段和“重破坏”策略,相对复杂。性能上限受限于所使用的单图像去噪先验,如果该先验无法提供良好的基线,后续残差学习效果会打折扣。论文未深入探讨对极端运动或严重遮挡的处理能力。[1] Frames2Residual: Spatiotemporal Decoupling for Self-Supervised Video Denoising. Mingjie Ji, Zhan Shi, Kailai Zhou, Zixuan Fu, and Xun Cao. https://arxiv.org/pdf/2603.10417v1.pdf[3] NAFNet: Nonlinear Activation Free Network for Image Restoration. Liangyu Chen et al. (文中使用的单图像去噪器)[9] TAP: Token-wise Adaptive Pre-training for Video Restoration. (对比的无监督方法)[29] PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume. (文中使用的光流估计器)[41] CRVD dataset and RViDeNet. (真实RAW视频去噪数据集及方法)*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

还在为视频去噪的纹理细节和运动模糊烦恼吗?想深入探讨更多图像/视频恢复的“分而治之”妙招?欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 图像处理+上海+清华+龙哥),根据格式备注,可更快被通过且邀请进群。








 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
