近日,南京大学与腾讯音乐发布开源语音大模型 VITA-Qinyu ,这是业内首款兼具自然对话、高表现力角色扮演与歌唱能力的 开源端到端语音语言模型 (SLM)。目前 VITA-QinYu 的训练代码与模型权重全面开源。来源丨paperWeekly
⏩颠覆体验!AI 不止会对话,更能演角色、唱金曲
过去的端到端语音语言模型,核心能力集中在实现流畅的自然对话,却难以捕捉人类语音中丰富的副语言信息——比如温柔的安慰语气、贴合角色的专属声线、随口哼唱的旋律,这些充满「人情味」的表达,始终是 AI 语音的短板。
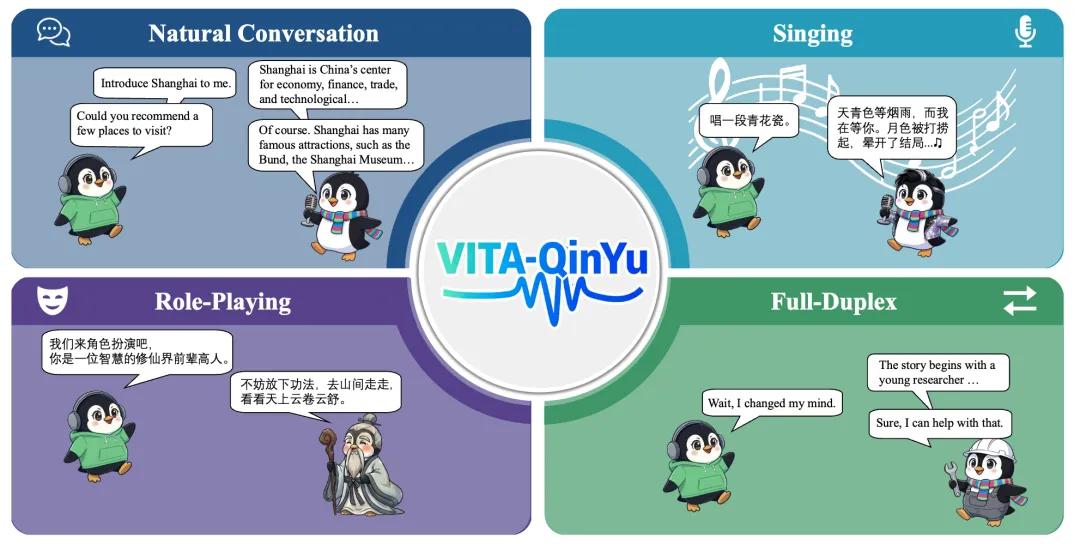
而 VITA-QinYu 的出现,填补了这一空白。它首次将角色扮演与歌唱能力融入通用语音对话模型,实现了三大核心能力:
✅ 自然对话:保持顶尖的对话准确性与流畅度,理解、推理能力媲美同等规模大小的LLM;
✅ 角色扮演:通过给定自然语言描述定制角色进行交流,同步支持动态音色控制,多轮对话人物设定的一致性,角色扮演种类无限制;
✅ 歌唱生成:无需乐谱输入,仅通过用户输入相关哼唱的指令即可生成自然演唱语音,打破传统歌声合成对结构化音乐信息的依赖。
从日常的景点推荐、聊天互动,到化身修仙前辈展开沉浸式角色扮演,再到随口点歌就能哼唱经典旋律,VITA-QinYu 让 AI 语音交互的场景边界被彻底拓宽。
接下来听一下 demo 效果(重心在新能力效果探索上,并没有做 VLLM 以及其他相关的加速,目前实际延时在 H20 上 2s 左右)
自然对话
哼唱能力
角色扮演
该角色是一个青年男性,身份是穿越者/现代灵魂,性格跳脱吐槽、偶尔迷茫,气质违和,音色自然,带现代口语
该角色是一个幼儿女性,身份是世家千金,性格活泼机敏、爱撒娇,气质天真灵动,音色甜润,语速较快
该角色是一个中年男性, 身份是修真界的前辈高人 , 性格沉稳淡定,善于提出建设性意见,气质偏向智者风格
该角色是一个青年女性,身份是苗女/异族少女,性格直率泼辣、敢爱敢恨,气质野性奔放,音色独特,带口音
⏩硬核设计!混合语音-文本范式,解锁更丰富的语音表达
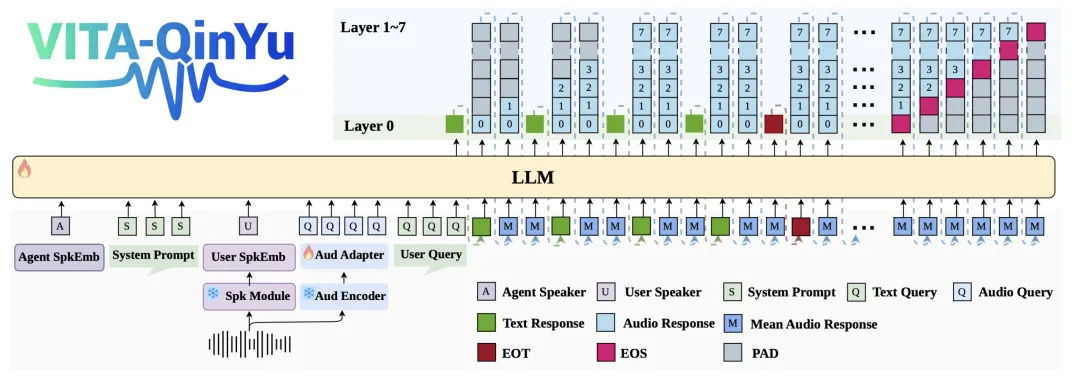
VITA-QinYu 的出色表现,源于其创新的混合语音-文本建模范式。
在原有交错文本-音频建模的基础上,模型引入了多码本音频令牌,既实现了更丰富的副语言特征表征,又保证了音、文模态的清晰分离,避免相互干扰,从底层解决了「表达丰富性」与「模态稳定性」的矛盾。
模型的核心架构还包含这些关键设计:
双骨干模型可选:以 Decoder-only Transformer 为基础,支持 Qwen3-8B、Youtu-LLM-4B 双骨干,推出 4B/8B 两个版本,支持多轮对话(仅保留历史文本响应以降低计算成本),兼顾性能与轻量化;
动态音色控制:集成 Text-to-Timbre(TTT)模块以及 speaker embedding 相关模块,通过角色描述即可生成匹配的声线,实现动态音色控制;
高保真音频编解码:采用 XY-Tokenizer 多码本编解码器(12.5Hz 下 8 个码本),相比单码本方案,能更精准还原语音与歌唱的旋律、韵律,提升生成质量。
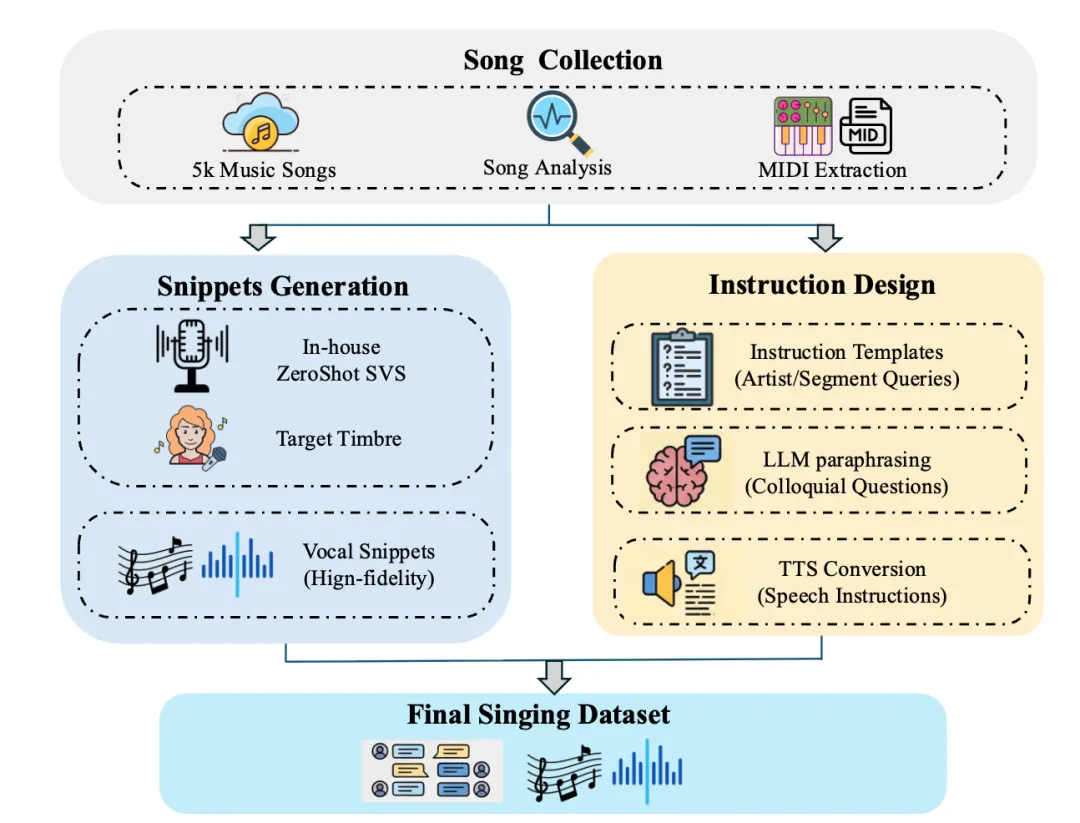
⏩海量数据!多维度精细化处理,筑牢模型训练根基
高质量的模型,离不开大规模、多维度、精细化的数据集支撑与处理。
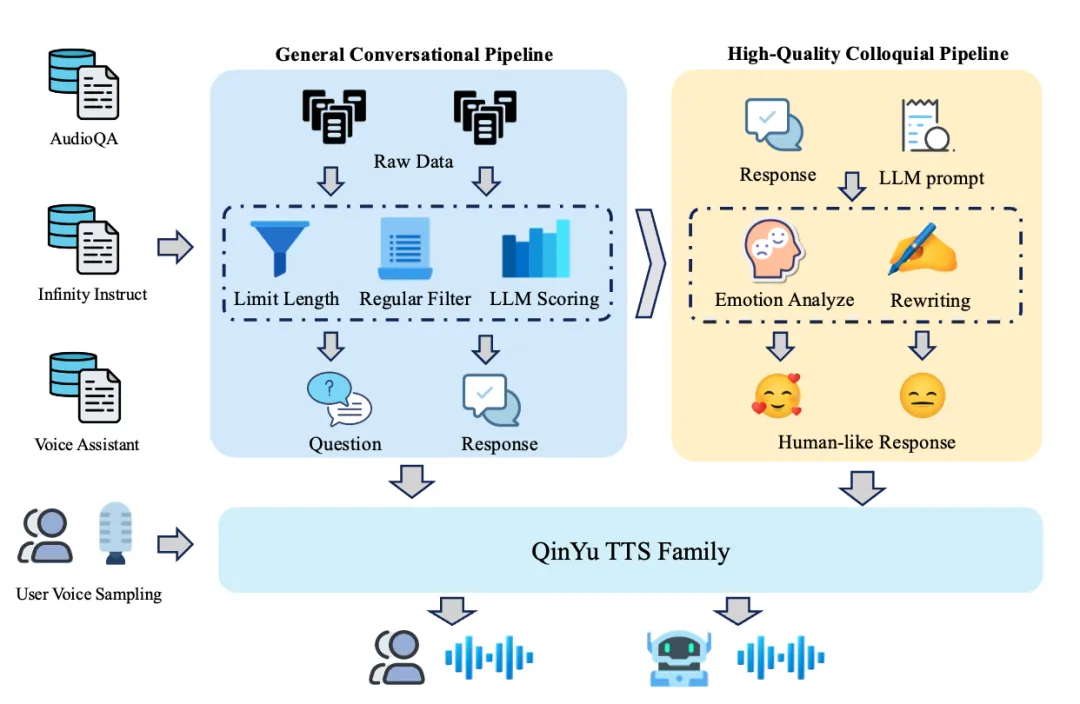
VITA-QinYu 团队打造了一套覆盖自然对话、角色扮演、歌唱三大类的全链路数据处理流水线,累计构建 12K 小时自然对话数据、2.6K 小时角色扮演数据、1.2K 小时歌唱数据,并通过多轮筛选、标注、合成优化,让每一类数据都精准匹配模型能力训练需求,为三大核心能力的落地筑牢基础。
自然对话数据:双层筛选 + 情感优化
从多源文本中筛选 155 万条中英样本,通过长度限制、正则过滤、模型打分剔除低质内容;对高分样本做情感分析与口语改写,生成 40 万条富含情绪的自然对话;合成 9 万 + 独特说话人语音查询,提升模型对不同声线、口音的适配性。
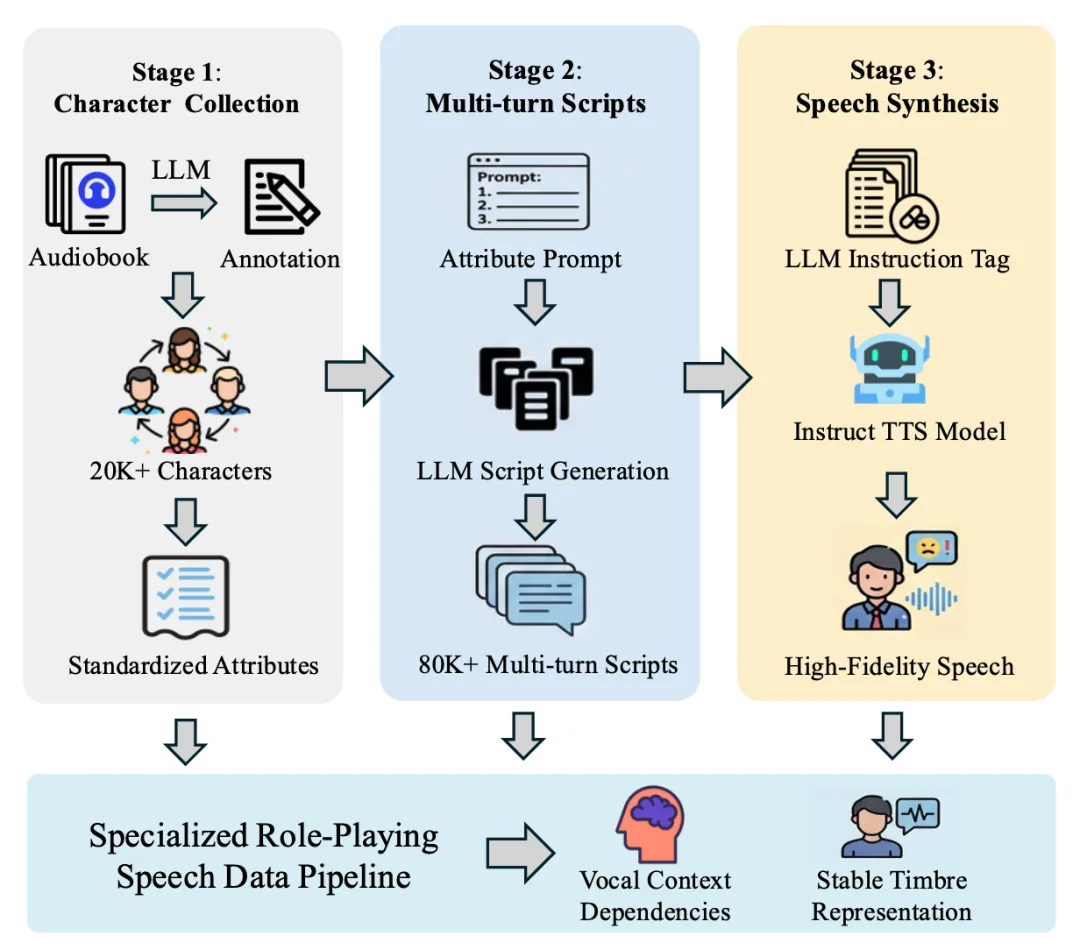
角色扮演数据:三阶段流水线保障人设统一
从有声书中提取 2 万 + 角色,定义人口统计、声线风格等四大属性;通过属性约束提示词,生成 8 万 + 轮贴合人设的多回合脚本;为脚本标注情绪指令,用指令式 TTS 生成精细控制韵律与情绪的语音数据,累计 2.6K 小时。
哼唱数据:无乐谱适配日常场景
收集 5000 首热门歌曲,分解片段并提取 MIDI 旋律;通过零样本 SVS 生成高保真 vocal 片段,绑定统一声线;将标准化点歌指令改写为「唱一段青花瓷」等口语化查询,构建 1.2K 小时歌唱数据。
⏩开源共建!代码模型全开放,邀开发者一起完善
为了让更多开发者能够参与到表达型语音大模型的研发中,推动技术的快速迭代与场景落地,做出了一个重要决定——将模型的训练代码、权重全面开源,并打造了一套易用的 Web demo 演示系统,支持流式传输与全双工交互。
这套系统融合了 Whisper 语音识别、TEN 框架实现打断检测能力,还原了真实自然的人机语音交互场景,开发者无需复杂部署,即可快速体验自然对话、角色扮演相关的效果能力,更能基于开源代码与模型,进行二次开发、场景定制与技术优化。
从基础的语音交互优化,到个性化的角色音色定制,再到歌唱能力的升级、垂直场景的适配,VITA-QinYu 的开源为开发者提供了全新的技术底座,期待全球开发者的加入,一起完善模型能力,探索更多新可能。
⏩未来可期
目前 VITA-QinYu 的角色扮演与歌唱能力仍处于早期探索阶段,团队表示未来将持续优化模型,进一步提升表达丰富度、场景适配性与生成质量。而此次开源,更是为行业注入了新的活力,让更多开发者能够参与其中,共同推动 AI 语音交互技术的发展。
这款「能说、会演、善唱」的 AI 语音大模型,正在为智能助手、沉浸式交互、数字人、语音娱乐、在线教育等领域,打开全新的想象空间。
相信在开源社区的共同努力下,VITA-QinYu 将不断进化,让 AI 语音的交互体验更贴近人类,让科技真正拥有「人情味儿」。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
