「七院院士」黄维领衔!南京邮电大学凌海峰/解令海最新Nature子刊 | 基于本征氧梯度的二阶忆阻器!
- 2026-05-09 13:02:32


持续学习是人类认知系统的核心能力,它使个体能够在整个生命周期中不断获取、优化和转移知识。这一复杂过程由生物体内精密的电生理机制支撑,通过跨细胞膜的内源性离子梯度实现信息的巩固与提取。在人工智能领域,强化学习被视为实现持续学习最有潜力的算法框架,而固态离子型忆阻器因其模拟生物离子信号处理的能力而备受关注。然而,现有忆阻器缺乏稳定的本征梯度构建,导致离子重分布过程随机且状态变化剧烈,无法生成持续强化学习所需的时间相关内部状态。尤其是一阶忆阻器难以保留长时程的导电相关性,而二阶忆阻器虽具备类生物的可塑性,但其状态变量衰减过快,限制了在长时间尺度上的信息处理能力。因此,如何通过材料设计构建稳定的本征氧梯度,以延展二阶忆阻器的时间动力学窗口,成为实现高效持续强化学习的关键科学问题。
针对以上难题,南京邮电大学黄维院士(西北工业大学)、凌海峰教授、解令海教授团队等人报道了一种基于本征氧梯度的二阶忆阻器,通过引入分子配位层(锌卟啉,ZnTPP)实现了稳定的界面势垒演化(>10²秒),从而在单极脉冲刺激下平衡氧离子的迁移与扩散,获得显著的导电调制(ΔG = -98.1%)。该器件表现出40个可区分的伪非易失性电导状态,并将其映射为强化学习算法中的动态学习率,使学习任务的时间尺度与器件动力学协同演化。与常规策略相比,本征梯度驱动的调制在静态和动态环境中分别减少了68.75%和35.65%的训练迭代次数。该研究揭示了慢动态二阶忆阻器作为物理嵌入的时间自适应单元,在神经形态系统中桥接器件动力学与算法学习的潜力。
相关论文以“Intrinsic gradient oxygen-driven second-order memristors for continual reinforcement learning”为题,发表Nature Communications上。
值得注意的是,这已经是黄维院士团队2026年发表的第6篇Nature子刊!
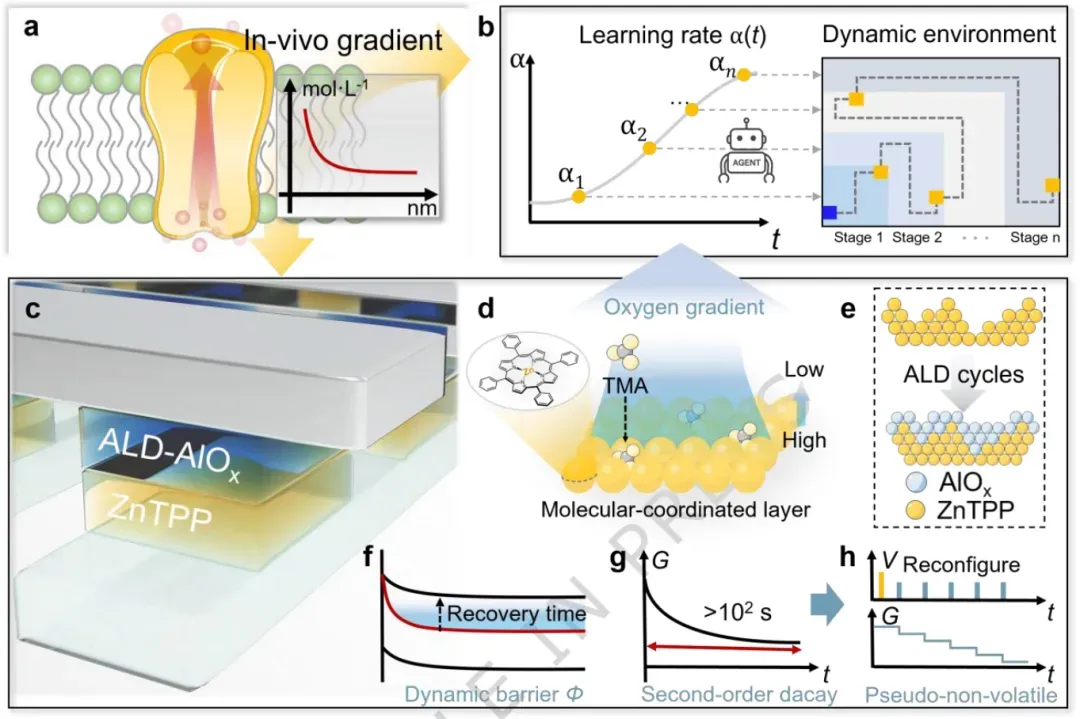
图1 ITO/ZnTPP/ALD-AlOx/Al器件的忆阻特性及二阶突触特性
图1展示了本征梯度驱动型二阶忆阻器的设计理念及其在持续强化学习中的应用框架。作者从生物系统中的跨膜离子梯度获得启发(图1a),将其抽象为一种时间自适应学习率调制机制(图1b)。器件结构为ITO/ZnTPP/ALD-AlOx/Al(图1c),其中ZnTPP分子层通过配位效应诱导本征氧梯度的形成(图1d),并通过原子层沉积工艺将其空间固定(图1e)。该本征梯度显著延长了界面势垒的恢复过程(图1f),使器件表现出超过10²秒的慢速二阶导电衰减行为(图1g)。进一步地,这种慢动力学可通过单极脉冲幅值进行调制,生成多个伪非易失性电导状态(图1h),为强化学习代理提供时间结构化、非平稳的输入信号。该图系统性地将材料设计、器件物理与算法需求相连接,奠定了全文的研究基础。
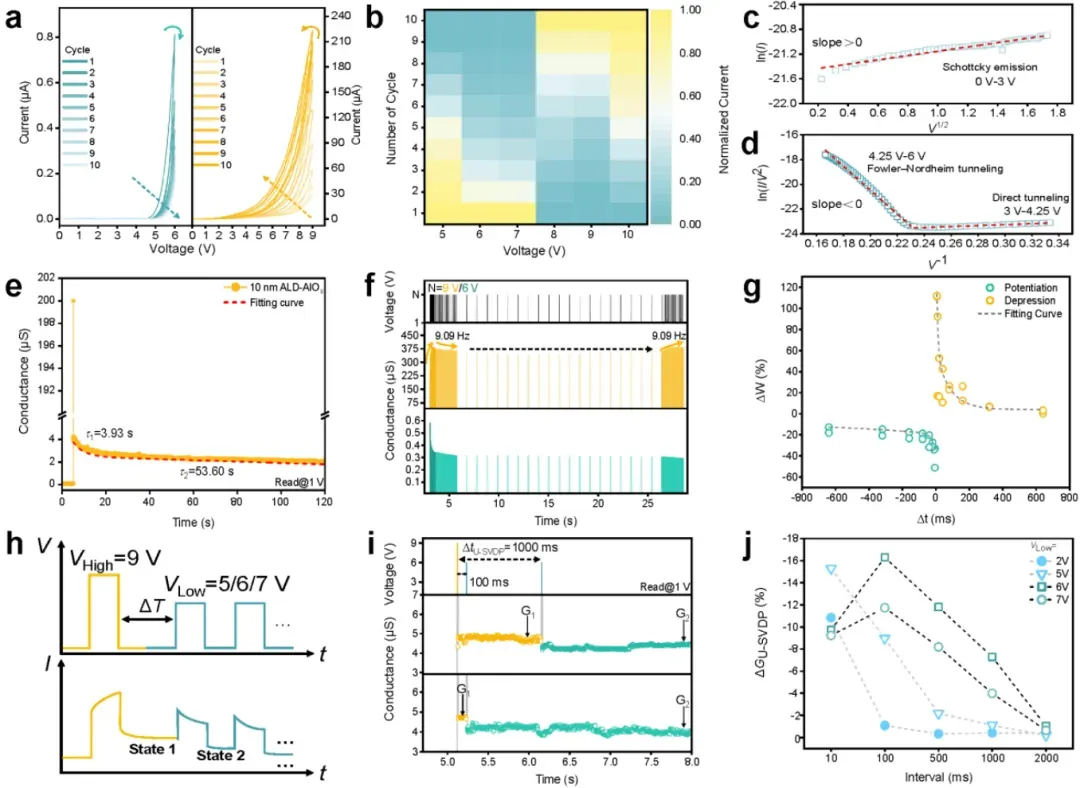
图2 ITO/ZnTPP/ALD-AlOx/Al器件的电学特性及其二阶突触可塑性
图2系统表征了ITO/ZnTPP/ALD-AlOx/Al器件的电学特性及其二阶突触可塑性。图2a展示了器件在连续扫描下的I-V曲线,表现出电压幅值依赖的抑制与激发行为,7V为转折点(图2b)。通过I-V曲线拟合,作者揭示了低电压区(0–3V)由肖特基发射主导(图2c),而高电压区(3–6V)则表现为隧穿机制转变(图2d)。图2e展示了9V脉冲后的导电衰减过程,拟合得到τ₁=3.93 s和τ₂=53.60 s的双指数衰减,证实了二阶动力学特性。图2f显示了频率依赖的氧离子迁移-扩散行为,图2g则实现了反赫布学习规则的STDP曲线。图2h–j展示了单极脉冲电压依赖可塑性的脉冲方案及其导电响应,图2k进一步量化了不同脉冲组合下的电导变化率。该图全面揭示了器件在电压幅值、脉冲频率和时序依赖下的突触可塑性机制。
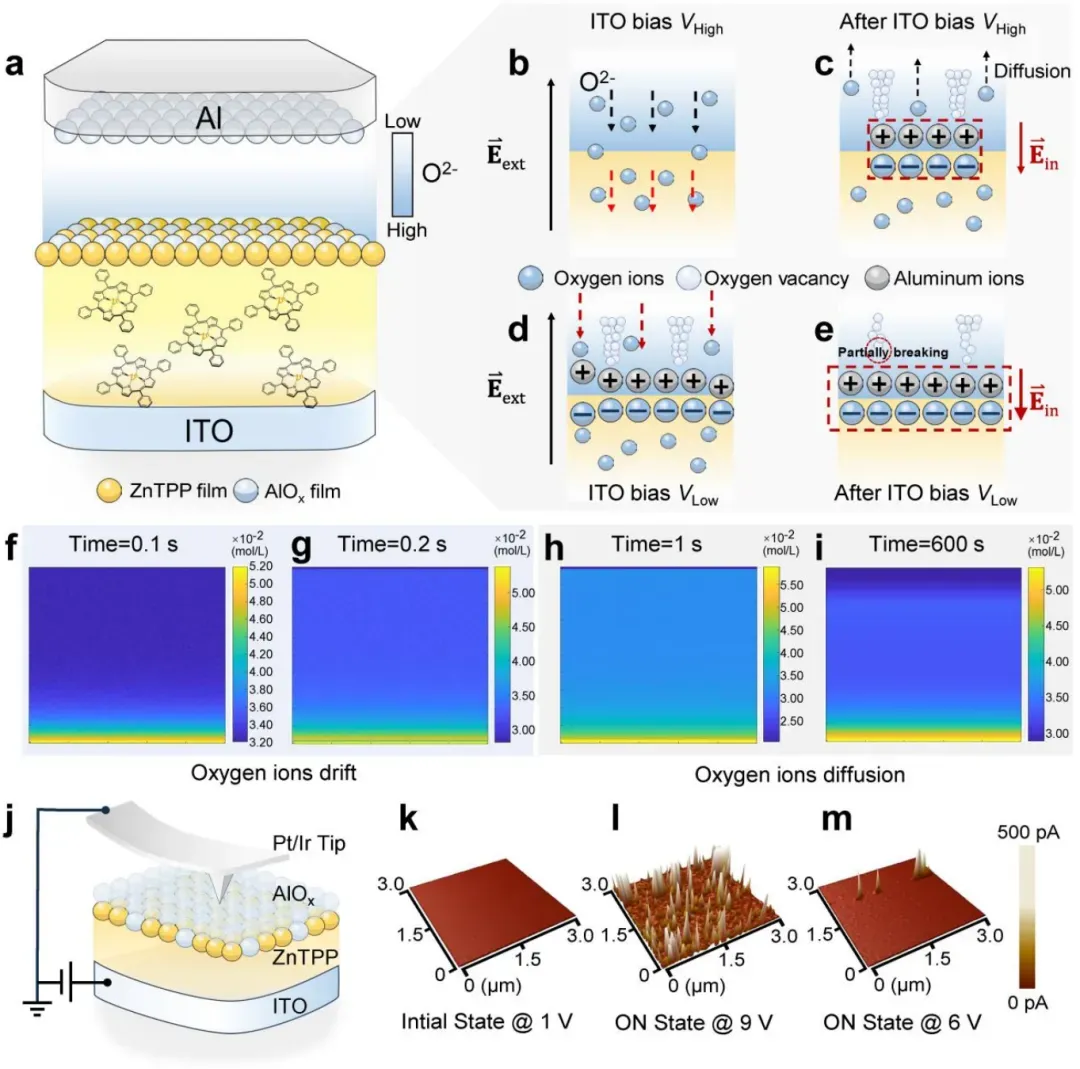
图3 氧离子在ZnTPP/ALD-AlOx界面处的动态行为
图3通过机理示意图和原位导电原子力显微镜揭示了氧离子在ZnTPP/ALD-AlOx界面处的动态行为。图3a展示了新鲜器件中氧浓度从ZnTPP界面到AlOx层逐渐降低的分布特征。在施加9V高压(VHigh)后,氧离子克服Al–O库仑力,通过ZnTPP网络迁移,形成界面内建电场(图3b–c)。撤去电压后,部分氧离子沿本征梯度扩散回AlOx层(图3d–e)。有限元模拟结果(图3f–i)进一步验证了氧离子在电场驱动下的非对称分布及其在撤压后的缓慢弛豫过程。图3j–m展示了原位c-AFM测量的电流分布图,6V偏压诱导均匀隧穿电流,而9V偏压则生成多个氧空位细丝,其位置与ZnTPP/AlOx界面的反应位点相关。6V再次施加后可部分溶解细丝,证实了U-SVDP功能。该图从实验和模拟双重视角阐明了本征梯度调控氧离子动力学的物理机制。
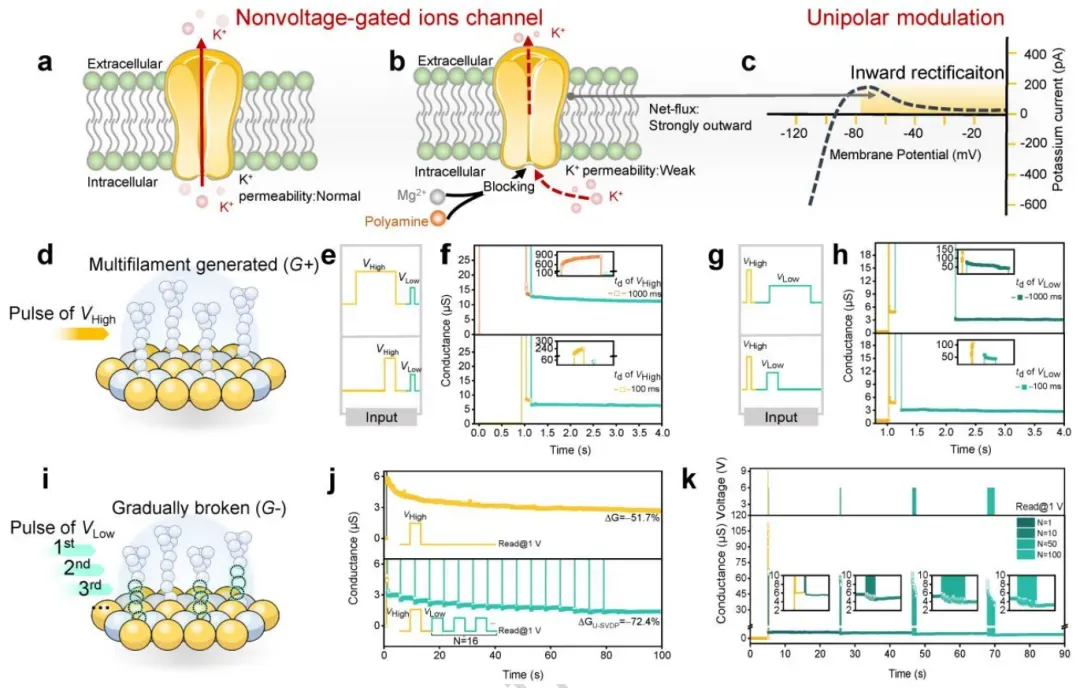
图4 受非电压门控通道单极性调制过程启发的传导调节作用
图4借鉴生物非电压门控离子通道的工作原理,展示了基于U-SVDP的伪非易失性电导调制过程。图4a–c类比了NVGCs在膜电位变化下的离子输运行为,强调其幅值依赖、梯度导向的离子调控特性。图4d示意了VHigh诱导的多细丝系统。图4e–h系统研究了不同脉冲时长组合对电导调制的影响,发现100 ms的VHigh与100 ms的VLow组合可实现最佳的慢梯度恢复和PNV状态稳定性。图4i示意了连续VLow脉冲逐步溶解多细丝的过程,图4j显示16次U-SVDP调制后电导变化率达-72.4%,显著高于自发衰减的-51.7%。图4k进一步验证了不同VLow序列下的PNV状态稳定性。该图通过精细的脉冲工程,实现了对氧离子动力学的时间尺度调控,为后续强化学习中的动态学习率映射提供了物理基础。
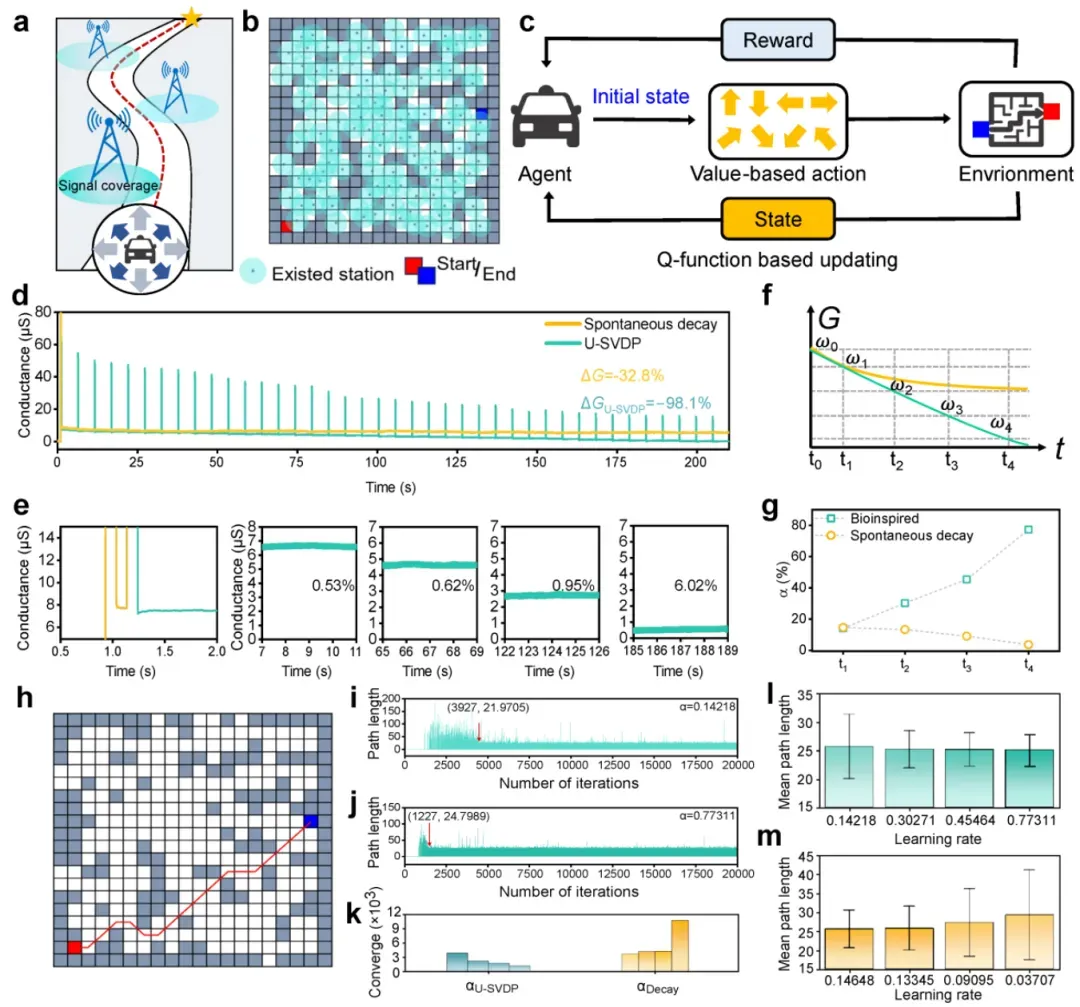
图5 在静态环境中持续强化学习(RL)中基于内在梯度驱动的学习率更新方法
图5将本征梯度驱动的U-SVDP电导状态映射为强化学习中的动态学习率,并在静态环境中验证其有效性。图5a–b展示了自主车辆在信号覆盖下的最优路径选择任务,图5c为基于Q学习的持续强化学习框架。图5d–e显示40个PNV电导状态的调制范围达-98.1%,且波动极小,证明多细丝系统的稳定性。图5f–g将电导随时间的变化定义为学习率α(t),对比了U-SVDP调制与自发衰减的α演化趋势。图5h为最优路径示意图。图5i–j展示了不同α下的收敛过程,α从0.142增至0.773时,收敛迭代次数从3927降至1227,减少68.75%。图5k–m对比显示U-SVDP驱动的α具有更快的收敛速度和更低的波动性。该图首次将器件级慢动力学与算法级学习率更新直接耦合,展示了物理驱动学习调制的优越性。
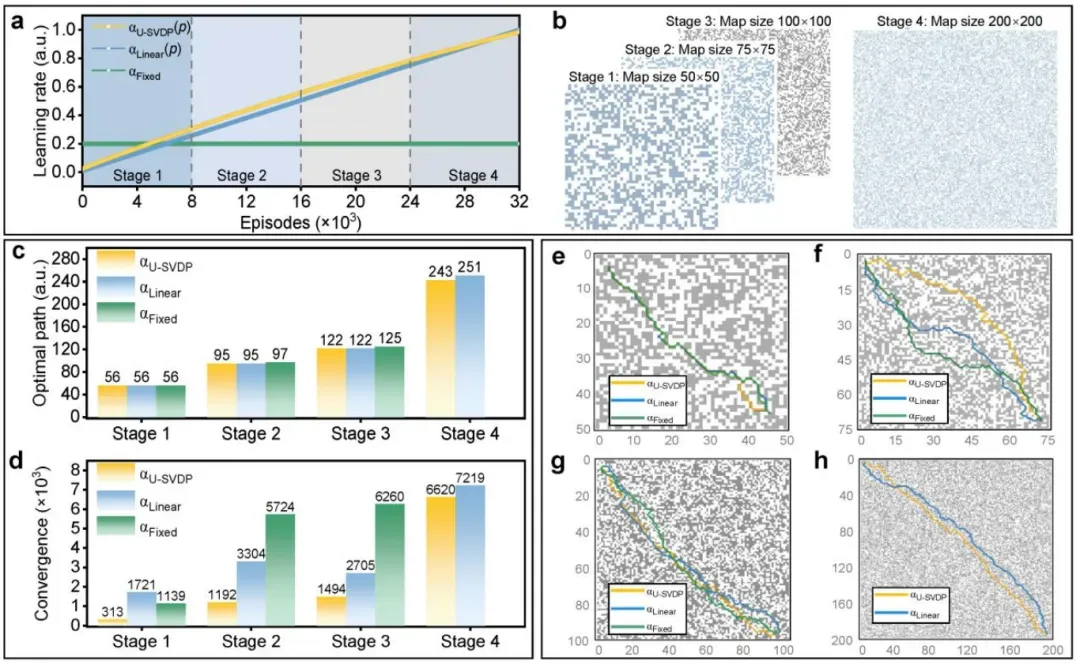
图6 在动态环境中进行持续强化学习时基于内在梯度驱动的学习率调节
图6将本征梯度驱动的动态学习率策略拓展至多阶段动态环境中,验证其在持续强化学习中的泛化能力。图6a展示了U-SVDP衍生的非线性学习率曲线与线性和固定学习率策略的对比。图6b为四阶段地图尺寸递增的任务设置(50×50 → 200×200)。图6c显示U-SVDP策略在各阶段均能生成更灵活的最优路径。图6d的收敛曲线表明U-SVDP策略在各阶段均加速收敛,总训练次数较线性调制减少35.65%。图6e–h详细对比了各阶段的最优路径长度。此外,作者还在附录中验证了该方法在障碍密度变化、多奖励结构和动态目标环境中的鲁棒性。该图充分证明,基于本征梯度慢动力学的学习率调制策略能够有效支持智能体在复杂动态环境中的持续适应能力。
该项研究成功展示了基于本征氧梯度的二阶忆阻器,其通过ZnTPP分子配位效应促进了增强型氧化物生长并诱导了空间氧浓度梯度,从而实现了延长的界面势垒演化。利用单极脉冲电压依赖可塑性,氧离子的漂移与扩散得以平衡,将宽范围衰减过程(ΔG = -98.1%)重构为超过40个伪非易失性电导状态。这些状态使二阶忆阻器能够保留持续学习所需的时间相关内部状态。将其映射为动态学习率后,强化学习任务的训练迭代次数减少了68.75%,并显著缓解了收敛振荡和局部最优问题。即使在动态环境中,本征梯度驱动的学习率仍比传统方法减少了35.65%的训练次数。该工作为设计具有慢动态特性的二阶忆阻器提供了生物启发的框架,为神经形态计算中的持续学习铺平了道路。
Ming, J., Wang, R., Fu, J. et al. Intrinsic gradient oxygen-driven second-order memristors for continual reinforcement learning. Nat Commun (2026). https://doi.org/10.1038/s41467-026-70014-0



