本工作室建立了微信群促进同学们之间的交流学习并有效讨论问题,可通过添加编辑微信进群。1.编辑微信:1)FEtunan(微信号)2)186006489282.工作室提供:二维材料生长及器件制作;科研绘图技巧;二维相关报告或会议推送;二维读博导师推荐、课题组招聘需求等欢迎大家投递中文的工作宣传稿及广告,具体联系微信:FEtunan(微信号)黄维院士,南京邮电大学凌海峰教授,香港城市大学何颂贤教授等发表题为Gradient-distributed metal-halide dynamic memristors for adaptive and robust voiceprint recognition”于Nature Communications上。
当前声纹识别系统大多采用传统数字电路完成信号采集与后端降噪运算,声音采集单元和特征处理硬件相互分离,数字串行运算模式功耗极高,在手机、可穿戴这类边缘终端设备上很难长时间稳定运行。而且现实场景里雨声、车流、设备运转等各类背景噪声会严重掩盖人声专属频谱特征,传统软件降噪算法计算开销大、实时性差,普通忆阻器器件又存在明显短板:丝状阻变器件开关突变、无法连续模拟编码时变语音;扩散型动态忆阻器长时间工作下界面电荷持续堆积,电导不受控漂移,会丢失细微人声特征,很难实现自适应噪声抑制。针对上述一系列实际应用痛点,本文设计一种组分梯度分布金属卤化物动态忆阻器(MHDM),通过一步共蒸工艺在 Cs-Cu-I 功能层内部自发形成垂直元素梯度,依靠梯度结构调控肖特基势垒与界面离子迁移行为,器件具备微秒级快速弛豫动态突触特性,可在硬件层面实时对语音信号自适应滤波降噪,搭配一维卷积神经网络搭建完整片上声纹识别系统,安静环境识别精度达 99.3%,嘈杂真实场景下仍保持 93.2% 高识别率,信噪比整体提升超 20%。
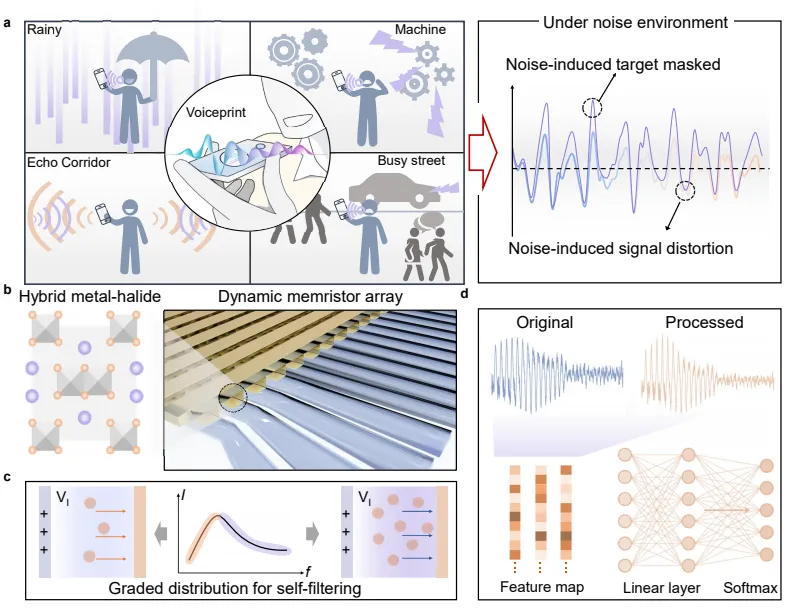
图 1 完整展示整套梯度金属卤化物忆阻器声纹识别系统整体应用场景、器件堆叠结构、动态信号调控原理与完整识别工作链路,把终端实际使用场景和器件底层信号处理逻辑串联起来,清晰说明整套系统从收音到身份判定的完整流程。图 1a 模拟日常手机远距离非接触声纹核验场景,现实环境中各类杂声会覆盖人声关键特征,常规处理方式识别准确率大幅下滑,而本文搭建的硬件预处理系统可以先在器件端完成噪声滤除再送入识别网络。图 1b 给出核心 MHDM 垂直堆叠结构,基底为图案化 ITO 底电极,中间 80nm 厚梯度 Cs-Cu-I 功能层,顶部蒸镀金顶电极,单层共蒸发制备工艺让薄膜从底到顶形成铯富集、铜碘富集的渐变组分,天然形成可动态调节的界面肖特基势垒。图 1c 直观展示器件自适应电流响应规律,输入连续时序语音转化的电压脉冲时,内部碘空位会在电场驱动下发生迁移,界面势垒高度实时变化,对强弱不同的声学信号做出差异化电导反馈,自动压制高频大振幅噪声信号、保留人声细微频谱特征,实现原生硬件滤波效果。图 1d 梳理完整识别链路,原始音频先归一化转为低压脉冲输入忆阻器,器件输出经过自适应调制的时序电流信号,再送入五层一维卷积神经网络提取人声特征完成说话人分类,整套架构把降噪预处理前移至硬件器件层面,大幅削减后端神经网络计算量,从系统顶层设计上解决数字电路高功耗、延迟高的固有缺陷,也直观体现梯度卤化物忆阻器作为时域模拟预处理单元的核心价值。
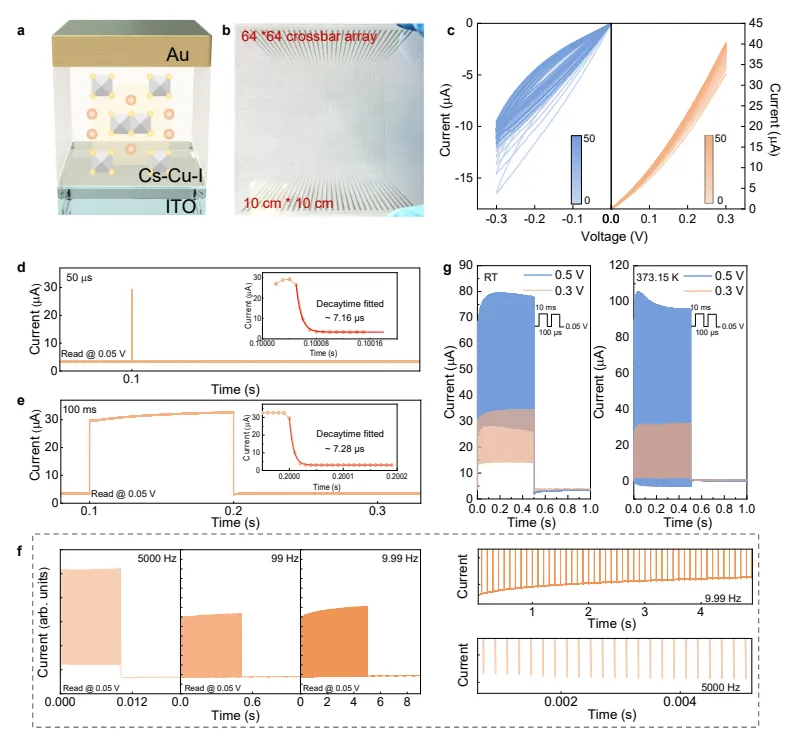
图 2 系统性表征梯度 Cs-Cu-I 忆阻器阵列规模化制备水平、基础阻变回线、单脉冲短时可塑性动态、频率与幅值依赖的突触行为以及温度调控规律,全部电学测试数据互相印证器件自适应时域响应的物理基础。图 2b 展示 10cm×10cm 衬底上制备 64×64 大规模交叉阵列,一百支器件电学参数统计离散度极低,证明一步共蒸工艺重复性强,具备晶圆级规模化制造潜力。图 2c 为双极性扫描下典型 I-V 回线,清晰呈现捏滞忆阻迟滞曲线,不对称电流走势直接佐证上下界面存在可调制肖特基势垒。图 2d、e 分别施加 50 微秒、100 毫秒单脉冲测试瞬态电流变化,脉冲施加时电流快速抬升,移除后迅速衰减,拟合得到主要弛豫时间常数仅 7.16μs,这种快速可逆电流变化和生物短时突触可塑性高度吻合,超快衰减速度刚好适配千赫兹级语音信号处理需求。图 2f 设置 9.99Hz、99Hz、5000Hz 三组连续脉冲刺激,低频脉冲下界面碘空位缓慢累积,势垒降低电流逐步提升表现为增强效应;高频刺激时离子往复迁移造成界面过量空位堆积,势垒抬高电流持续衰减呈现抑制行为,这种频率区分自适应响应正是硬件降噪的核心来源。图 2g 对比 0.3V、0.5V 两种脉冲幅值,低压缓慢增强、高压快速抑制,同时升温至 373K 后增强、抑制两种动态效果同步加剧,佐证器件行为由热激活碘空位迁移主导,梯度界面能平衡离子累积速度,不会出现传统器件电导失控漂移,多组梯度变量对照完整说明器件可依靠输入信号频率、幅值自主调整电导,天然区分人声低频特征与高频环境噪声。
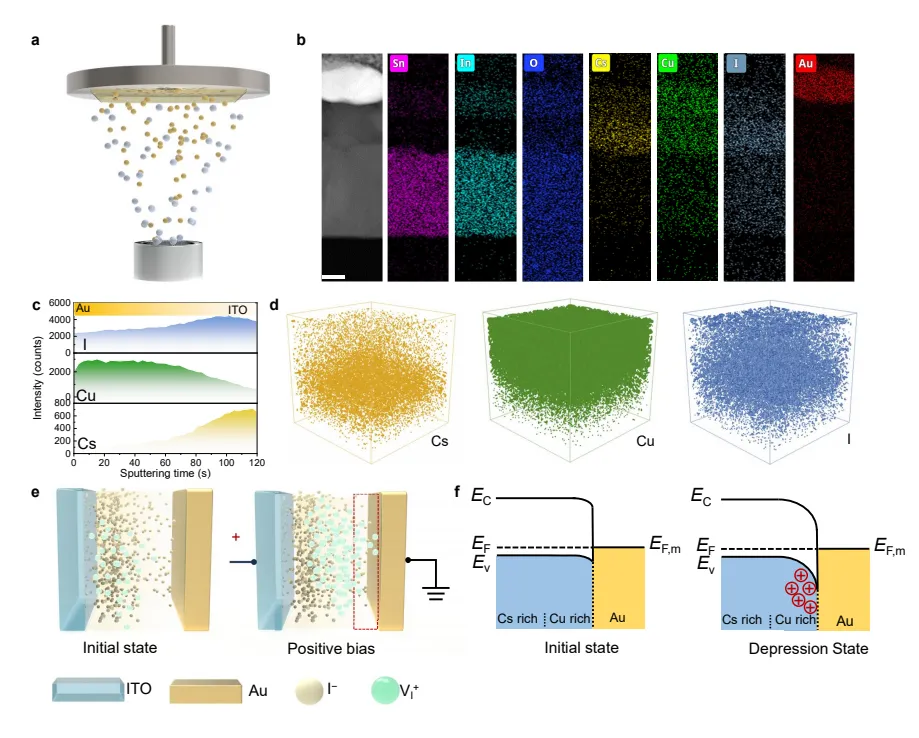
图 3 从薄膜沉积工艺、横截面元素分布、飞行时间二次离子深度剖析、离子输运机理、对照器件性能对比多个维度,完整解释一步共蒸如何自发形成垂直组分梯度,以及梯度结构调控肖特基势垒、实现自适应突触动态的微观机理。图 3a 介绍 CsI 与 CuI 共蒸发制备流程,蒸发前期 Cs 原料消耗快,薄膜靠近 ITO 一侧铯元素占比高,后期仅 CuI 持续沉积,薄膜靠近金电极区域铜碘组分富集,自发形成垂直渐变两相复合薄膜,XRD 图谱同时出现正交 CsCu₂I₃与 γ-CuI 特征衍射峰,证实薄膜两相共存。图 3b 横截面 EDS 元素 mapping 直观呈现分层梯度分布,ITO 侧 Cs 信号强,Au 侧 Cu 信号富集,碘元素沿厚度连续渐变。图 3c、d 的 ToF-SIMS 深度溅射谱逐层解析元素含量变化,溅射初期铯信号突出,随溅射加深铜信号持续上升,完美验证薄膜纵向组分梯度真实存在。图 3e、f 绘制碘空位迁移能带机理示意图,正向电压下碘空位向 Au 界面移动,低刺激时空位少量聚集、界面势垒降低电流上升;高频高幅值刺激后大量空位堆积在金侧,势垒抬升电流被抑制,两相梯度结构里 CsCu₂I₃为离子迁移通道,表层 CuI 层作为势垒调控层,一维链状晶体结构限制离子无序扩散,彻底解决传统三维钙钛矿离子无规堆积、性能漂移问题。文章同时制备 40nm 无梯度纯 CsCu₂I 对照薄膜、纯 CuI 薄膜做对比,无梯度薄膜不存在高压抑制行为,纯 CuI 仅欧姆导通无忆阻迟滞,只有两相梯度共存结构才能形成可动态调节肖特基界面,从材料合成、元素表征、离子动力学、对照组实验多层级完整阐明梯度组分是器件自适应噪声处理的决定性结构条件。
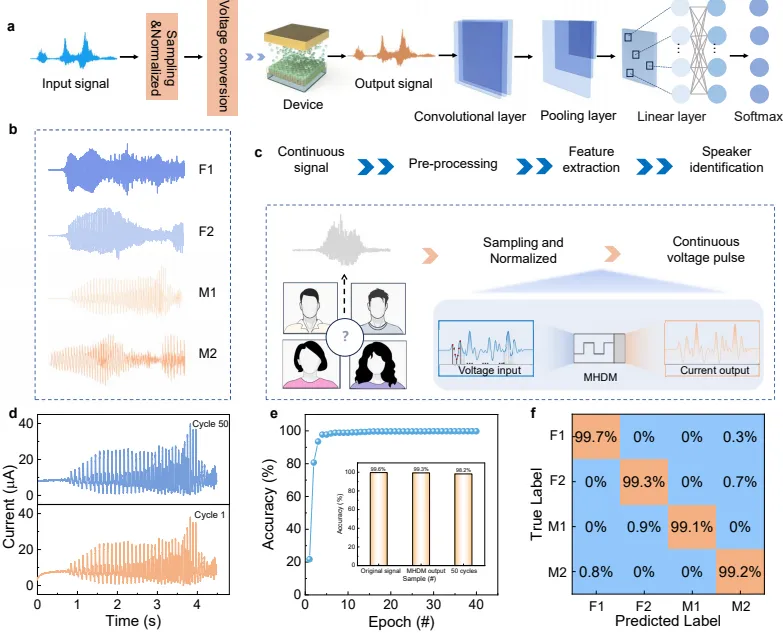
图 4 搭建纯净人声采集测试系统,采用四位男女受试者 “你好” 短句构建数据集,将语音波形转化脉冲输入忆阻器,输出电流特征送入一维卷积网络,全面评估无噪声环境下器件预处理后的声纹识别精度与循环稳定性。图 4b 展示四位说话人原始音频波形,振幅、时域细微差异代表各自专属声纹特征,全部音频归一化映射至 0-0.3V 低压区间匹配器件工作窗口。图 4c 记录器件输出时序电流,不同人声转化后的电流曲线存在稳定可区分差异,这些由器件自适应调制的电流波形作为全新声纹特征送入神经网络训练,数据集合计四千余组有效样本,器件循环带来细微信号差异反而扩充数据多样性,提升模型泛化能力。图 4e 统计识别准确率,原始音频识别精度 99.6%,经过忆阻器硬件预处理后仍维持 99.3%,五十次连续循环测试后精度稳定在 98.2%,证明器件提取人声特征时不会丢失关键身份信息,重复工作稳定性优异。图 4f 混淆矩阵清晰区分四位说话人,分类错误占比极低,整套系统单脉冲功耗仅纳瓦级别,和传统数字语音处理芯片相差六个数量级,超低功耗优势适配各类便携边缘设备,完整验证梯度卤化物忆阻器作为硬件声纹预处理单元,在纯净声学环境下高精度、低功耗识别的可行性。
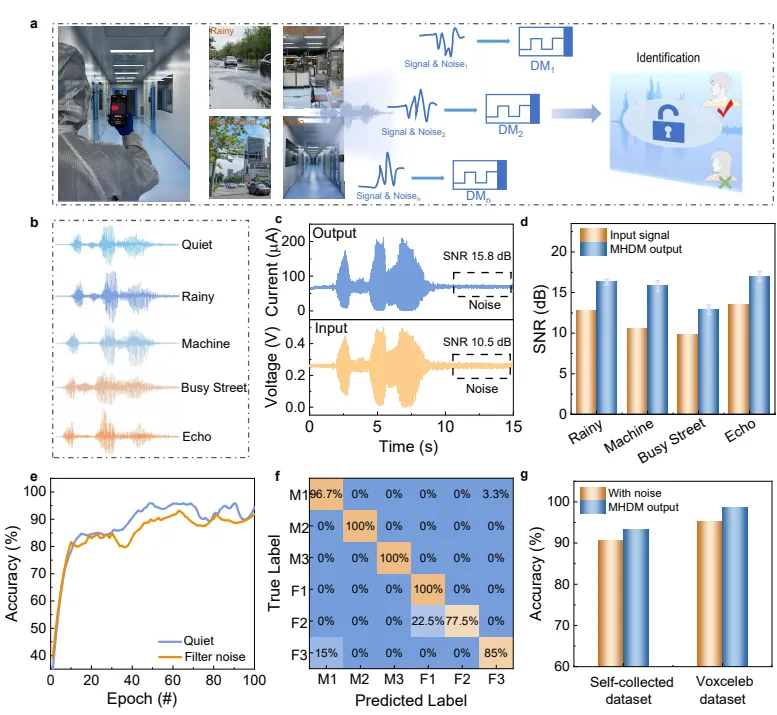
图 5 引入多类真实场景噪声构建复杂语音数据集,涵盖雨声、车间机械、闹市、回声四类干扰,分别采用自制数据集与公开 VoxCeleb 户外语音库测试器件降噪鲁棒性,量化信噪比提升幅度与嘈杂环境识别精度。图 5b 展示无噪声、四类噪声叠加后的语音波形,噪声会大幅掩盖说话人固有振幅特征,常规算法识别效果急剧下滑。图 5c 对比机械噪声处理前后音频信噪比,原始仅 10.5dB,经过 MHDM 自适应硬件滤波后提升至 15.8dB,单类场景信噪比提升超 20%,图 5d 汇总全部四种噪声下增益数据,无论何种干扰类型器件均能稳定抬升信噪比,依靠高频噪声对应的高幅值脉冲触发电流抑制效应,自动过滤杂声、保留低频人声特征。图 5e、f 为嘈杂场景识别精度与混淆矩阵,自制多说话混合数据集噪声环境识别精度 93.2%,和安静场景 95.9% 差距极小;拓展至公开户外 VoxCeleb 数据集,原始嘈杂音频识别 95.3%,经器件硬件预处理后提升至 98.7%,充分证明该梯度忆阻器的降噪效果具备普适性,不局限于固定录音环境。整套多噪声对照实验直接解决现有忆阻器语音系统抗干扰差的短板,证实组分梯度动态忆阻器可以直接在硬件层面完成实时降噪,不用依赖高算力数字后端,大幅降低复杂场景声纹识别设备的功耗与硬件体积。
文献:https://doi.org/10.1038/s41467-026-74047-3