IF17.1!南京医科大学用“机器学习+多组学”拿下一区TOP,重塑衰老评估新标准!
光看身份证上的出生日期,根本判断不了真正的衰老速度。南京医科大学在《Journal of Advanced Research》发表研究,利用英国生物银行近3.8万人的血浆蛋白数据,打造了“ProtPhenoAge”衰老时钟。
它不仅整合常规血检,还纳入血浆蛋白变化,对全因死亡的预测能力,优于表型年龄、蛋白年龄和实际年龄。还能发现与年龄无关但加速衰老的因素。衰老是多维度的,这项研究理清了关键脉络。
LITERATURE INTERPRETATION●中文标题:ProtPhenoAge:整合血浆蛋白质组学预测衰老相关疾病风险
●发表期刊:Journal of Advanced Research
光靠年龄判断衰老远远不够。表型年龄、蛋白年龄各有短板,临床指标只能间接反映遗传,蛋白时钟又漏掉那些与年龄无关但驱动衰老的事件。血浆蛋白能综合内外信号。研究者整合近3.8万人数据,融合蛋白组与临床优势,更全面量化衰老。
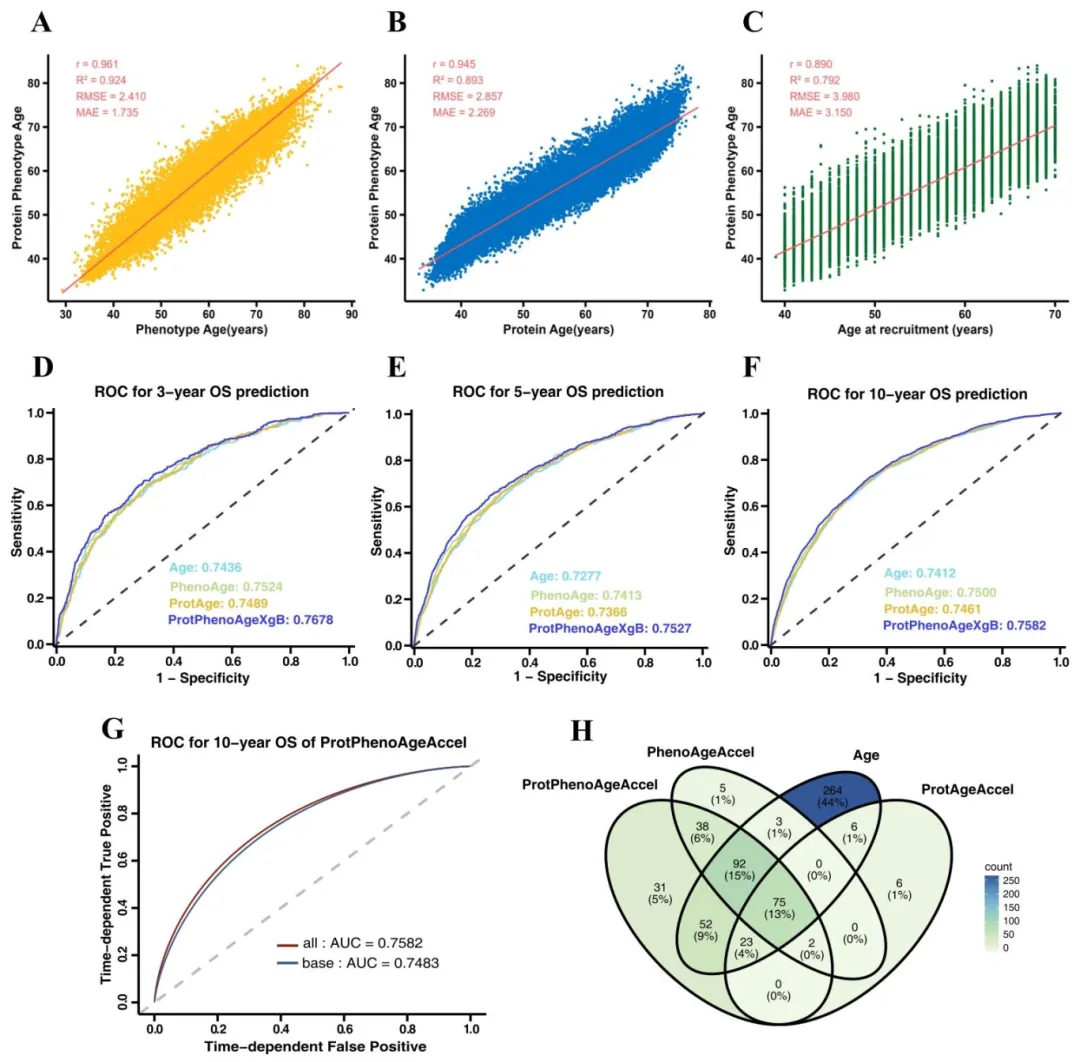
研究者从UK-Biobank中筛选出近3.8万名参与者,先基于九项临床血检指标算出每个人的PhenoAge作为生物年龄标签。随后用Boruta-SHAP算法从近3000种血浆蛋白中筛选出185种与衰老最相关的蛋白。接着同时训练了六种机器学习模型,比谁预测PhenoAge最准、预测死亡风险最强。最终XGBoost胜出,这就是ProtPhenoAge。
性能验证表明,XGBoost从六种模型中胜出。ProtPhenoAge与PhenoAge高度相关(r=0.961),3年死亡预测AUC达0.768,优于现有指标。校正混杂后,生物年龄每增1岁,死亡风险升高约11%。局限在于样本全为英国白人,外推性存疑,且基线数据无法捕捉动态衰老(图1)。
先用PhenoAge当标签,它本身就是基于死亡风险校准的临床指标,比直接用年龄更科学。再让算法从近3000个蛋白里自己挑“有用”的,不靠人工预设,减少主观偏差。六种模型同时训练、择优录取,最后用死亡风险而非拟合精度定胜负。这套“标签选得巧、特征筛得精、模型比得狠”的框架,值得借鉴。
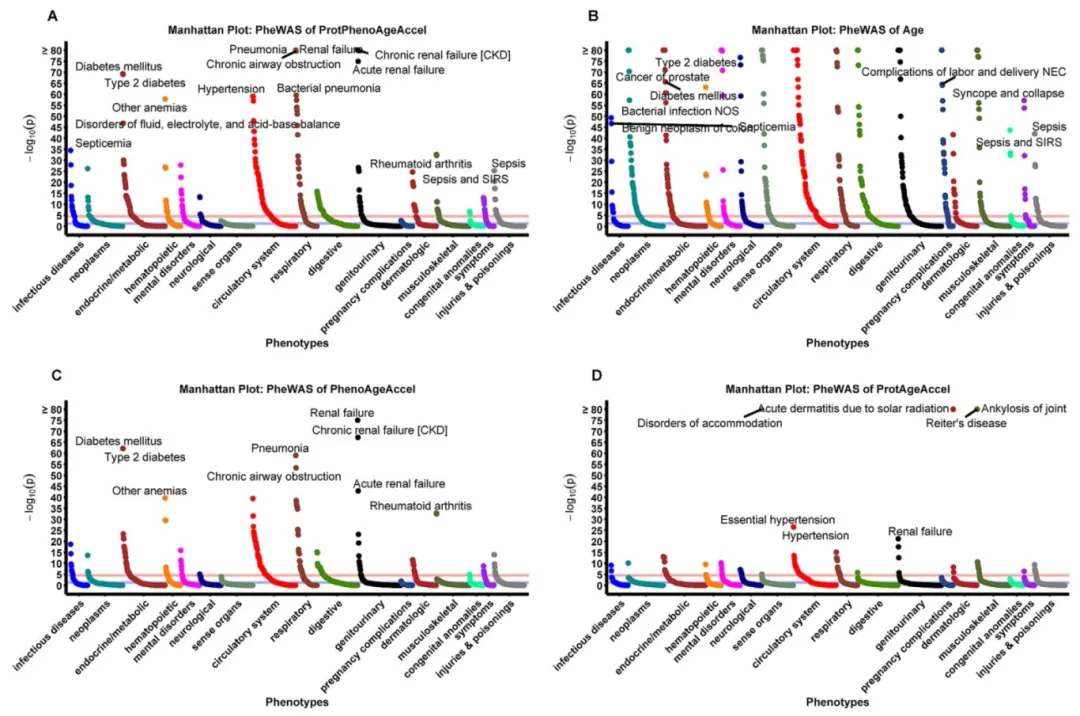
回归关联分析显示,ProtPhenoAgeAccel与313种疾病显著相关,其中77%为经典年龄相关疾病。还能捕获31种年龄独立表型,以免疫紊乱和精神障碍为主。双向孟德尔随机化证实,糖尿病、心衰与加速衰老存在双向因果。局限在于横断面数据难定因果时序,部分关联或受残留混杂干扰(图2)。
这项研究的分析思路很清晰。先拿加速衰老指标去“扫”1854种疾病,不设限、不预判,看看它到底跟什么有关。扫出来之后,特意揪出那些与实际年龄无关的表型,看看这个时钟能不能发现“年龄看不出的问题”。最后用双向孟德尔随机化验证因果关系,筛掉单纯的相关性。这套“广筛查—找差异—验因果”的三步走策略,值得参考。
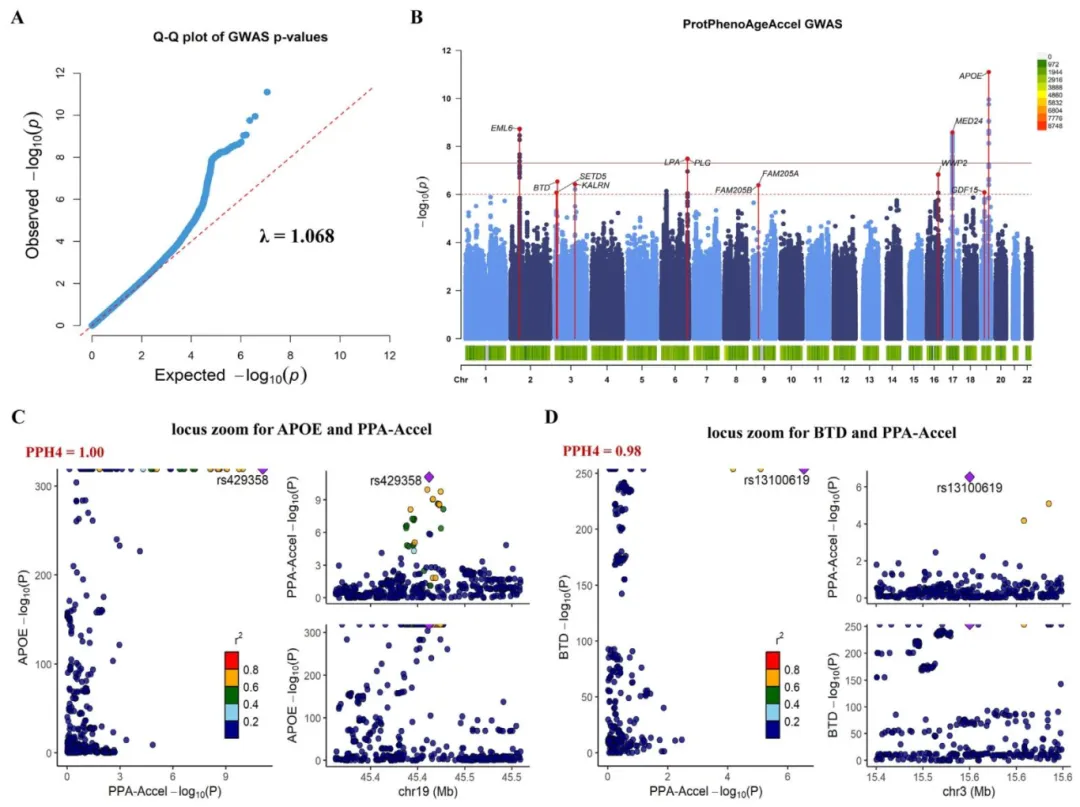
GWAS鉴定出10个衰老相关位点,其中2个为已知(APOE),8个为新增,指向脂代谢、炎症与吸烟通路。共定位证实APOE和BTD通过调控蛋白表达影响衰老,BTD为首次发现的潜在靶点。已知位点复现增强了可信度,但样本均为欧洲人群,外推性待验证,部分位点统计效力偏低(图3)。
先做全基因组扫描,把与加速衰老相关的位点全都拉出来,不预设候选基因,避免遗漏信号。接着把找到的位点分成已知和新增两类,能复现APOE这类经典位点说明方法靠谱,新增位点则提示脂代谢和炎症等通路可能参与其中。最后用共定位分析追问关键位点是不是通过调控蛋白来影响衰老,把遗传变异和蛋白机制串了起来。
不得不说,ProtPhenoAge这把新尺子确实比老几样好使。最值得借鉴的是整合思路,融合临床指标与蛋白数据,放到死亡风险这个硬终点上验货,蛋白负责敏感,临床负责稳健,各取所长。
要是你也手握公共数据想做预测模型,卡在多组学融合或模型筛选上,“标签选得巧、特征筛得精、模型比得狠”这套框架准没错。原文干货满满,值得一读~