南京医科大附一医院护理团队发表高分护理1区SCI! 应用机器学习和SHAP解释识别手术室护士中的高度共情疲劳: 一项多中心横断面研究
- 2026-06-26 00:28:59

专注科研一对一全流程教学
咨询微信:wzp1670423539



1.1 同情心疲劳:手术室护士的隐形职业伤害
手术室护士长期处于高强度、高紧张、高情感负荷的工作环境中——长时间站立、精神高度集中、目睹患者术中危急情况、应对术后不良结局等,使其成为同情心疲劳的高风险人群。同情心疲劳是指助人工作者因长期暴露于他人的痛苦和创伤情境中,导致自身情感资源耗竭、同理心下降的状态,包括继发性创伤应激、职业倦怠和同情心满意度下降三个核心维度。同情心疲劳不仅严重损害护士个人身心健康(如焦虑、抑郁、睡眠障碍),还削弱护理队伍稳定性(增加离职意愿),并危及患者安全(如注意力不集中导致差错)。然而,当前关于手术室护士同情心疲劳的大规模多中心调查仍然有限,且缺乏有效的风险预测工具。
1.2 研究空白与机器学习的机会
传统研究多采用回归分析识别同情心疲劳的影响因素,但无法充分捕捉复杂因素间的非线性交互作用。机器学习方法(如随机森林、XGBoost)能够处理高维数据、自动捕捉非线性关系,并可通过SHAP方法增强模型可解释性——使“黑箱”变得透明。因此,利用机器学习构建手术室护士同情心疲劳的预测模型,不仅可提高预测准确性,还能揭示各风险因素的相对贡献大小,为个性化干预提供依据。
1.3 研究目的
本研究旨在:分析手术室护士同情心疲劳的患病率及症状特征,利用机器学习构建并比较五种预测模型的性能,并通过SHAP分析确定不同特征对模型的相对贡献。

2.1 研究设计
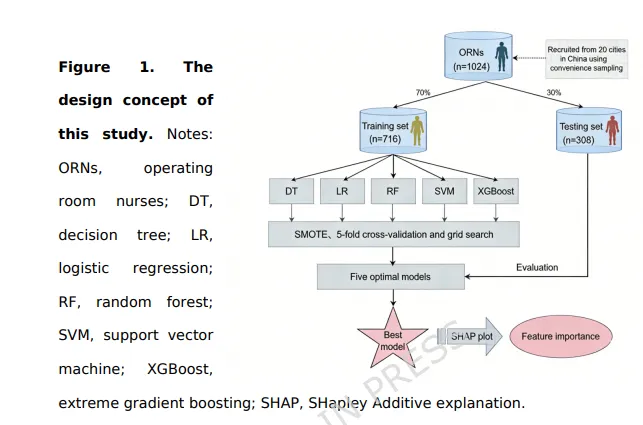
采用多中心横断面研究设计,覆盖中国20个城市。
2.2 研究对象
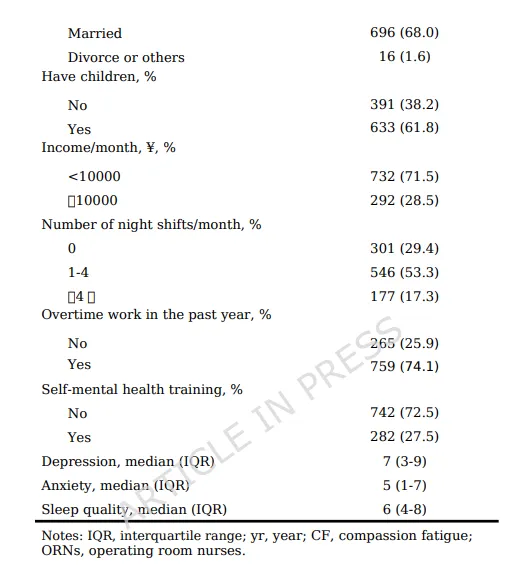
纳入1,024名手术室护士。纳入标准:在职注册护士;在手术室工作≥1年;自愿参与。

2.3 测量工具
职业生活质量量表:评估同情心疲劳的三个维度——继发性创伤应激、职业倦怠、同情心满意度。
患者健康问卷-9项:评估抑郁症状。
广泛性焦虑障碍量表-7项:评估焦虑症状。
匹兹堡睡眠质量指数:评估睡眠质量。
2.4 统计与机器学习方法
LASSO回归:从众多候选变量中筛选关键预测因子(降维)。
五种预测模型:决策树、Logistic回归、随机森林、支持向量机、XGBoost。
模型性能评估:使用受试者工作特征曲线下面积(AUC)比较模型区分能力。
模型解释:采用SHAP方法可视化各特征对预测的贡献。

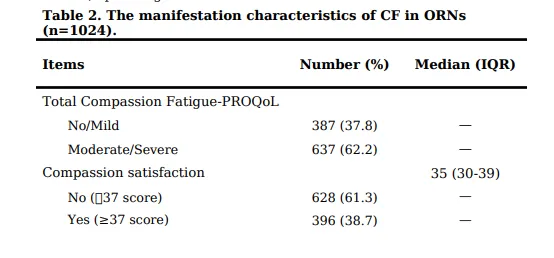
3.1 同情心疲劳的患病率
1,024名手术室护士中:
重度同情心疲劳:326人(31.8%)
中度同情心疲劳:311人(30.4%)
无或轻度同情心疲劳:387人(37.8%)
超过六成(62.2%)的手术室护士存在中重度同情心疲劳,问题严重。
3.2 三个维度的症状特征
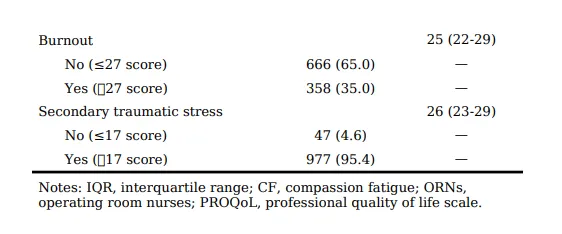
在同情心疲劳的三个维度中:
继发性创伤应激发生率最高:95.4%(几乎普遍存在)
低同情心满意度:61.3%
职业倦怠:35.0%
继发性创伤应激(即因间接接触患者创伤而产生的心理应激反应)是手术室护士最突出的问题,其发生率远高于职业倦怠。这一发现提示,手术室护士的同情心疲劳更多源于“目睹创伤”而非“工作倦怠”。
3.3 机器学习模型性能比较
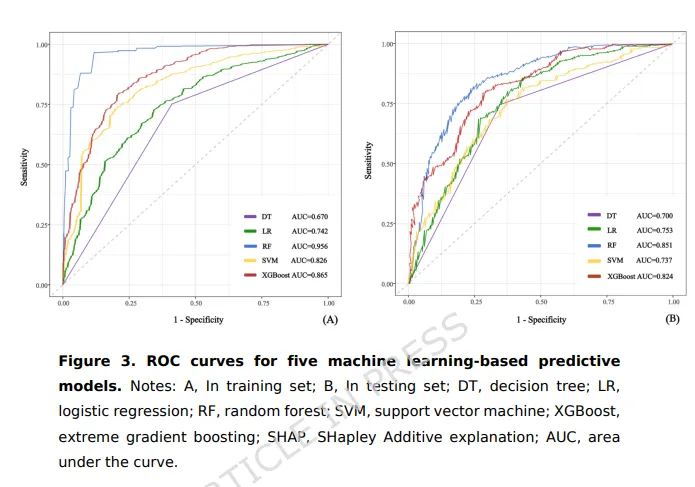
五种模型的AUC(测试集)比较:
随机森林:AUC=0.851(95% CI: 0.795-0.907)——最佳
XGBoost:AUC=0.824(95% CI: 0.769-0.879)——次优
其余三种模型(决策树、Logistic回归、支持向量机)表现略逊
随机森林模型在所有模型中表现最佳,AUC=0.851,表明其能够较好地区分“高同情心疲劳”和“低同情心疲劳”的手术室护士。
3.4 SHAP特征重要性分析
随机森林和XGBoost两个SHAP图结果一致,贡献最大的五个特征依次为:
抑郁(患者健康问卷-9项得分)
焦虑(广泛性焦虑障碍量表-7项得分)
自我心理健康培训(是否接受过)
睡眠质量(匹兹堡睡眠质量指数得分)
工作年限
这一排序提示,在预测手术室护士同情心疲劳时,心理因素(抑郁、焦虑)比工作年限等结构性因素更为重要。接受过自我心理健康培训的护士,其同情心疲劳风险更低(说明培训具有保护作用)。

4.1 主要发现及其意义
本研究首次在多中心大样本中,结合传统调查与机器学习方法,系统评估了手术室护士同情心疲劳的患病率并构建了预测模型。核心结论如下:
第一,同情心疲劳在手术室护士中极为普遍(中重度占62.2%),其中继发性创伤应激是最突出的症状维度(95.4%)。 这一比例远超既往研究,可能与COVID-19疫情期间的持续高压工作环境、手术室特有的创伤性情境暴露以及中国手术室护士的工作负荷有关。
第二,随机森林模型(AUC=0.851)可有效识别高危个体,优于传统Logistic回归。 这证明了机器学习在护理职业健康预测中的应用价值——它能捕捉传统回归难以发现的非线性交互作用。
第三,抑郁、焦虑、缺乏心理健康培训、睡眠障碍和较长工作年限是同情心疲劳的五大核心预测因子。 其中抑郁和焦虑的贡献最大,提示心理状态是同情心疲劳的上游驱动力。这一发现对干预设计具有直接指导意义——管理者应优先关注护士的心理健康状态,而非仅关注工作负荷。
4.2 临床与公共卫生意义
早期筛查:可使用该模型对手术室护士进行定期风险评估,识别高危个体。
分层干预:对抑郁和焦虑得分高的护士,应优先提供心理咨询和支持;对睡眠质量差者,提供睡眠管理干预;对缺乏心理健康培训者,将培训纳入常规继续教育。
组织支持:鉴于继发性创伤应激的高发生率(95.4%),医院应建立创伤应激疏导机制,如定期的巴林特小组、心理援助热线。
4.3 研究优势与局限性
优势:
多中心大样本(20个城市,1,024人),代表性好。
首次将机器学习应用于手术室护士同情心疲劳预测。
SHAP分析增强了模型的可解释性,便于临床转化。
局限性:
横断面设计,不能确定因果关系(如抑郁是同情心疲劳的原因还是结果)。
便利抽样,可能存在选择偏倚。
未纳入手术室特异性变量(如手术类型、日手术量、暴露于死亡事件的频率)。
4.4 未来研究方向
开展纵向研究,追踪同情心疲劳的动态变化及预测因子的因果方向。
将模型转化为临床决策支持工具(如简易评分卡),便于护理管理者使用。
开展干预研究,验证针对“抑郁、焦虑、睡眠”的综合干预方案对降低同情心疲劳的效果。

本研究通过对中国20个城市1,024名手术室护士的多中心横断面调查,结合机器学习方法,得出以下结论:
手术室护士同情心疲劳问题严重:中重度者占62.2%,其中继发性创伤应激是最突出的症状维度,发生率高达95.4%。这提示干预应重点针对创伤应激,而非仅关注职业倦怠。
随机森林模型是最优预测模型:测试集AUC=0.851(95% CI: 0.795-0.907),优于XGBoost(AUC=0.824)及其他三种传统算法,证明机器学习在护理职业健康预测中的优越性。
五大核心预测因子:抑郁、焦虑、自我心理健康培训、睡眠质量和工作年限,对模型贡献最大。心理因素(抑郁、焦虑)的贡献强于结构性因素(工作年限),提示干预应优先从心理健康入手。
临床意义:医疗管理者应建立手术室护士同情心疲劳的定期筛查机制,对高风险者提供分层干预(心理咨询、睡眠管理、心理健康培训),并重视继发性创伤应激的预防与疏导,以保障护士队伍稳定性和患者安全。
1.1 选择研究主题
背景阅读: 阅读关于同情心疲劳、手术室护士、机器学习预测模型、SHAP解释等文献。您会发现:
手术室护士工作强度大、情感负荷重,同情心疲劳风险很高;
传统研究多用回归分析找影响因素,但回归有局限——假设线性关系,无法捕捉复杂交互;
机器学习(随机森林、XGBoost)能处理非线性,预测更准;
但机器学习是“黑箱”,需要SHAP“打开”它,让医生和管理者信任结果。
这就是研究空白: 没有人用机器学习方法预测手术室护士的同情心疲劳,也没有人用SHAP解释过哪些因素最重要。
1.2 明确研究目的
确定目标:
调查手术室护士同情心疲劳的患病率及症状特征(三个维度的分布)。
用5种机器学习算法构建预测模型,找出最优算法。
用SHAP分析揭示各特征对预测的贡献大小。
小白提示: 这类研究的最大亮点是“传统调查+机器学习+SHAP解释”的组合拳。你不需要自己发明算法——随机森林、XGBoost都有现成的R/Python包。SHAP也有现成的库。你需要做的只是收集数据、清洗数据、跑模型、读结果。

2.1 选择研究类型
多中心横断面研究设计:
在单一时间点通过问卷收集所有数据。
特点: 可快速获取大样本(1024人,20个城市),但不能确定因果关系。
2.2 确定研究参与者
样本选择: 采用便利抽样法,从中国20个城市招募手术室护士。
纳入标准: 在职注册护士;手术室工作≥1年;自愿参与。
样本量要求: 机器学习通常要求样本量至少为特征数的10-20倍。本研究1024人,足够。
小白操作: 通过各医院护理部或手术室护士长发放问卷链接,注意伦理审批和知情同意。
2.3 变量的选择与测量
结局变量(Y): 同情心疲劳(根据职业生活质量量表分为“高/低”两组,用于分类预测)。
候选预测因子(X) :人口学变量、抑郁(PHQ-9)、焦虑(GAD-7)、睡眠质量(PSQI)、心理健康培训经历等。
协变量: 年龄、性别、职称、工作年限等。
2.4 分析框架
描述性统计:同情心疲劳的患病率及各维度特征。
LASSO回归:从几十个候选变量中筛选关键预测因子(降维)。
5种机器学习模型:决策树、Logistic回归、随机森林、SVM、XGBoost——分别训练、比较AUC。
SHAP分析:解释最优模型的预测机制(特征重要性排序)。
3.1 数据获取
数据集: 不依赖公开数据库,通过在线问卷收集一手数据。于2025年某时间段,通过20个城市的医院护理部发放问卷链接。
小白操作: 设计问卷时,将多个量表组合在一起,设置必填。通过预调查测试信效度(Cronbach‘s α > 0.7)。
3.2 数据整理
清理数据:
剔除填写时间过短、规律作答、关键变量缺失的无效问卷。
有效问卷1024份。
变量生成:
计算同情心疲劳总分,按标准分为“高/低”二分类(结局变量)。
计算抑郁总分、焦虑总分、睡眠质量总分(连续变量)。
对分类变量(如性别、职称、有无心理健康培训)进行编码。
数据分割: 将数据随机分为训练集(70%)和测试集(30%),用于模型训练和验证。
最终生成R数据集: 1024行,列包括:结局变量(高/低疲劳)、候选预测因子、协变量。
4.1 描述性分析
计算同情心疲劳的患病率(重度31.8%,中度30.4%,合计62.2%)。计算三个维度的发生率——继发性创伤应激(95.4%)、低同情心满意度(61.3%)、职业倦怠(35.0%)。
4.2 LASSO回归——特征筛选
定义: LASSO(最小绝对收缩和选择算子)是一种带L1惩罚的回归方法,能将不重要的变量系数压缩为0,实现自动变量选择。它在机器学习建模前使用,可以减少特征数量、防止过拟合。
本研究的应用: 从所有候选变量中筛选出与同情心疲劳最相关的关键预测因子。
4.3 五种机器学习模型
简介(小白版):
Logistic回归:传统基准模型,假设线性关系。
决策树:用“如果…那么…”规则做分类,直观但容易过拟合。
随机森林:多棵决策树“投票”决定结果,比单棵树更稳更准。
支持向量机(SVM) :找一条“最宽的分界线”分隔两类。
XGBoost:梯度提升树的升级版,逐棵树纠正前一棵的错误。
操作(R的caret或Python的scikit-learn):
用训练集分别训练5种模型。
在测试集上预测,计算每个模型的AUC。
比较AUC,选出最优模型。
结果: 随机森林AUC=0.851,XGBoost AUC=0.824,其余更低 → 随机森林赢了。
4.4 模型评估指标——AUC
定义: AUC(受试者工作特征曲线下面积)衡量模型区分“高疲劳”和“低疲劳”的能力。AUC>0.7为可接受,>0.8为良好,>0.9为优秀。
本研究的应用: 随机森林AUC=0.851(良好),说明模型能较好地区分高危和低危护士。
4.5 SHAP分析——模型解释
定义: SHapley Additive exPlanations——一种解释机器学习模型预测的方法,量化每个特征对预测结果的贡献大小和方向。它把模型的“黑箱”打开一条缝,告诉你“为什么这个护士被判为高风险”。
本研究的应用: 两个SHAP图(随机森林和XGBoost)结果一致,贡献最大的5个特征:
抑郁(PHQ-9得分)——贡献最大
焦虑(GAD-7得分)
自我心理健康培训(有无)
睡眠质量(PSQI得分)
工作年限
小白理解: SHAP告诉你“这个护士被判为高危,主要是因为她的抑郁得分高、焦虑得分高、睡眠差”——这让模型结果在临床上可信、可用。
5.1 主要结果
中重度同情心疲劳占62.2%(重度31.8%+中度30.4%)。
继发性创伤应激发生率最高(95.4%)。
随机森林模型最优(AUC=0.851)。
五大核心特征:抑郁、焦虑、心理健康培训、睡眠质量、工作年限。
5.2 统计显著性
AUC的95% CI不包含0.5 → 模型有效。
SHAP值比较 → 特征重要性排序。
5.3 临床/管理意义
管理者应重点筛查抑郁、焦虑、睡眠差的护士。
提供心理健康培训可降低同情心疲劳风险。
5.4 局限性
横断面不能因果;便利抽样外推有限;未纳入手术室特异性变量。
6.1 讨论框架(5段式)
总结:同情心疲劳患病率高,继发性创伤应激最突出;随机森林预测最佳;SHAP揭示抑郁焦虑是关键。
与文献比较:首次在手术室护士中用机器学习+SHAP。
机制:目睹创伤→继发性创伤应激→同情心疲劳;抑郁焦虑放大效应。
实践:定期筛查抑郁焦虑睡眠;提供心理健康培训;建立创伤应激疏导机制。
局限与未来:纵向研究、干预验证、手术室特异性变量。
6.2 结论
“手术室护士同情心疲劳中重度占62.2%,继发性创伤应激最高(95.4%)。随机森林模型(AUC=0.851)可有效预测高危个体。抑郁、焦虑、睡眠质量和心理健康培训是关键干预靶点。”
7.1 撰写报告
遵循STROBE声明(横断面研究)。
标题建议: “Prevalence and machine learning-based prediction of compassion fatigue among operating room nurses: a multicenter cross-sectional study”
方法关键点:
报告LASSO回归的λ选择方法(交叉验证)。
报告5种机器学习模型的超参数设置。
报告数据分割方法(训练/测试比例)。
报告SHAP分析的具体实现。
结果:
表1:基线特征。
表2:同情心疲劳患病率及维度分布。
表3:5种模型性能比较(AUC及95% CI)。
图1:SHAP特征重要性图(条形图或蜂群图)。
7.2 投稿前自查清单
是否报告了伦理批准号和知情同意?
是否报告了各量表的信效度(Cronbach‘s α)?
是否报告了LASSO的交叉验证方法?
是否报告了数据分割的随机种子?
是否报告了各模型的超参数设置?
是否报告了AUC的95%置信区间?
是否提供了SHAP图?
7.3 推荐期刊
Journal of Nursing Management
International Journal of Nursing Studies
BMC Nursing
Frontiers in Public Health
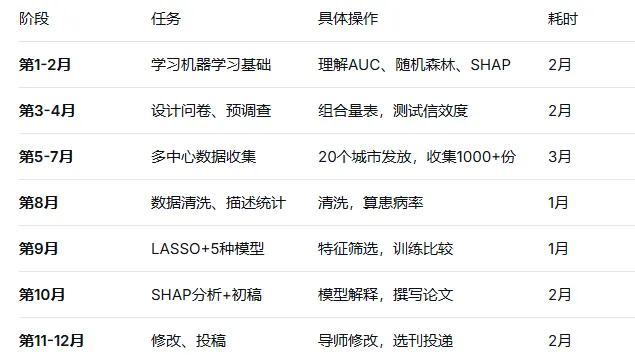
给小白的总体时间表(8-12个月)

1.1 多中心横断面研究设计
定义: 横断面研究是指在特定时间点上,对样本群体进行数据收集,以评估不同变量间的关系。本研究采用多中心横断面设计,于2025年期间,通过在线问卷同时收集中国20个城市手术室护士的同情心疲劳、抑郁、焦虑、睡眠质量及人口学、工作特征等数据。
特点:
现状描述: 适合估计手术室护士同情心疲劳的患病率(62.2%中重度)及各维度特征(继发性创伤应激95.4%)。
预测模型开发: 能够基于横断面数据构建分类模型,识别高同情心疲劳风险个体,但无法确定因果关系。
1.2 便利抽样
定义: 便利抽样是一种非概率抽样方法,研究者选择最容易接触到的研究对象。本研究通过20个城市的医院护理部发放问卷链接,选择自愿参与的手术室护士。
特点: 操作简便,成本低,可快速获取大样本(1024人),但样本代表性有限,外推需谨慎。
1.3 数据分割(训练集与测试集)
定义: 将数据随机分为两部分:训练集(70%)用于构建模型,测试集(30%)用于评估模型性能。这样可以避免“用同一批数据既训练又考试”的过拟合问题。
本研究的应用: 1024人随机分为训练集(约717人)和测试集(约307人),在训练集上训练模型,在测试集上计算AUC。
小白理解: 就像用一部分题目让学生学习,再用另一部分题目考试——这样才能真正检验学生学会了多少。

2.1 结局变量(因变量):同情心疲劳(二分类)
定义: 根据职业生活质量量表得分,将护士分为“高同情心疲劳”和“低同情心疲劳”两组。在机器学习中,这就是模型要“预测”的目标。
2.2 候选预测因子(自变量)
定义: 可能影响同情心疲劳的各种因素,包括:
人口学变量:年龄、性别、职称、工作年限
心理变量:抑郁(PHQ-9得分)、焦虑(GAD-7得分)
行为变量:睡眠质量(PSQI得分)
经历变量:是否接受过自我心理健康培训
2.3 特征筛选(LASSO回归)
定义: LASSO(最小绝对收缩和选择算子)是一种带L1惩罚的回归方法,能将不重要的变量系数压缩为0,实现自动变量选择。在机器学习建模前使用,可以减少特征数量、防止过拟合。
本研究的应用: 从所有候选变量中筛选出与同情心疲劳最相关的关键预测因子,减少模型输入的变量数。
小白理解: 就像从一堆杂物里挑出真正有用的几件——LASSO自动帮你扔掉没用的东西。

3.1 决策树
定义: 一种用“如果…那么…”规则做分类的树状模型。它通过不断分裂数据,形成一系列决策规则,最终将样本归入某一类别。
优点: 直观易懂,可视化强。缺点:容易过拟合(在训练集上表现好,在新数据上差)。
小白理解: 就像玩“20个问题”游戏——通过一系列“是/否”问题猜出答案。
3.2 Logistic回归
定义: 传统统计方法,用于分析多个自变量与一个二分类因变量的关系,输出风险概率。它是“基准模型”,用于衡量机器学习算法是否真的更好。
优点: 可解释性强,系数直接反映影响方向。缺点:假设线性关系,无法捕捉复杂交互。
小白理解: 算OR的那套方法,相当于“常规武器”。
3.3 随机森林(本研究最佳模型)
定义: 一种集成学习方法——构建多棵决策树,每棵树用随机样本和随机特征子集训练,最终通过“投票”决定结果。它比单棵决策树更稳、更准。
优点: ①能处理非线性;②自动捕捉特征交互;③不易过拟合。缺点:可解释性较差(黑箱)。
本研究的应用: 在五种模型中AUC最高(0.851),成为最优模型。
小白理解: 就像“众人拾柴火焰高”——很多棵决策树一起“投票”,比一棵树更可靠。
3.4 支持向量机
定义: 一种通过寻找“最宽的分界线”(最优超平面)将两类样本分开的算法。适合高维数据。
优点: 在小样本高维数据中表现好。缺点:对参数敏感,大数据集训练慢。
3.5 XGBoost
定义: “极端梯度提升”——一种集成学习方法,通过反复构建决策树,每棵新树专门纠正前一棵树的错误。它是数据科学竞赛的常胜将军。
优点: 性能强,速度快。缺点:参数多,调优复杂。
本研究的应用: AUC=0.824,仅次于随机森林。
小白理解: 就像“纠错机制”——后面的人专门改前面人的错误,越改越准。
3.6 五种模型的本质区别


4.1 受试者工作特征曲线与曲线下面积(ROC & AUC)
定义: ROC曲线以假阳性率为横坐标、真阳性率为纵坐标,用于评估模型区分“高同情心疲劳”和“低同情心疲劳”的能力。AUC是曲线下面积,范围0.5-1.0:0.5为随机猜测,0.7-0.8为可接受,0.8-0.9为良好,>0.9为优秀。
本研究的应用:
随机森林AUC=0.851(95% CI: 0.795-0.907)→ 模型良好
XGBoost AUC=0.824(95% CI: 0.769-0.879)→ 良好
其他模型略低
小白理解: 随机抽一个高疲劳者和一个低疲劳者,模型有85.1%的概率给前者打出更高风险。
4.2 AUC的95%置信区间
定义: 表示AUC估计的精度。若区间不包含0.5,则模型优于随机猜测。
本研究的应用: 随机森林AUC的95% CI为0.795-0.907,全部>0.5,显著优于随机猜测。

5.1 SHAP分析
定义: SHapley Additive exPlanations——一种基于博弈论的解释方法,量化每个特征对每个样本预测结果的贡献大小和方向。它让“黑箱”模型变得可解释。
本研究的应用: 两个SHAP图(随机森林和XGBoost)结果一致,贡献最大的五个特征依次为:抑郁、焦虑、自我心理健康培训、睡眠质量、工作年限。
小白理解: SHAP告诉你“这个护士被判为高危,主要是因为她的抑郁得分高、焦虑得分高、睡眠差”——这让预测结果在临床上可信、可用。
5.2 特征重要性排序
定义: 各特征对模型预测贡献的排名。SHAP值的平均绝对值越大,特征越重要。
本研究的发现: 抑郁和焦虑排前两名,说明心理因素是同情心疲劳的最强预测因子。
祝大家发文顺利,有什么不懂可以在评论区留言,吴老师尽量解答!零基础的同学可以咨询一对一辅导,快速发表SCI文章!
吴老师微信:wzp1670423539
还在担心没有SCI论文,缺少竞争力?找专人学习、快速发表人生第一篇SCI,点⬇️链接报名咨询!
0基础发护理SCI!一对一全程教学指导(教到发表模式)招生报名!
护研SCI专注护士SCI论文一对一指导,让每个护士都学会从0到1发表SCI!
我们定期解读优质文献,分享文章的具体思路和方法学。此外,我们面向护士提供高端一对一科研线上辅导,让零基础的普通人快速学会从0到1发表临床科研SCI论文。



感兴趣请扫描文末吴老师的二维码具体咨询如何加入SCI论文辅导项目。微信:wzp1670423539
本期编辑

你的分享、点赞、在看
我都喜欢



授人以鱼不如授人以渔
学无止境,终身学习!


