南京航空航天大学微波光子学国家重点实验室潘时龙教授、李昂研究员领衔,联合重庆联合微电子中心共同完成,。团队研制出国际首个全集成可编程光电计算处理器,以单片 32×32 硅基光子计算芯片为核心,实现 2 倍至 256 倍连续可调的端到端图像压缩与高保真重建,端到端处理延迟低至 49.5 ps / 像素,总能耗仅 10.58 nJ / 像素,在 1.3 亿像素机载遥感图像上实现最高 34 dB 峰值信噪比,处理速度与能效较高端 GPU 提升 2 至 3 个数量级,彻底解决传统电子方案与被动光子架构在压缩比、集成度、实时性上的核心瓶颈,为星载遥感、医疗成像、机载探测等场景提供超高速、低功耗的图像实时处理新范式。
遥感、卫星雷达、医疗成像等领域的图像数据呈指数级增长,单幅超高清图像容量可达 GB 至 TB 级,传统图像压缩方案面临难以突破的性能壁垒。基于电子硬件的 JPEG 系列算法依赖域变换、量化与熵编码,并行化成本高、实时处理延迟大、功耗过高,无法适配星载与边缘设备;深度学习压缩重建模型虽性能更优,但在电子平台上算力与能效严重不足。光子计算凭借太赫兹带宽、飞秒级延迟与近零热耗散,成为突破电子算力极限的颠覆性技术。然而,2024 年亚利桑那大学提出的被动光子压缩系统存在致命缺陷:仅依靠随机散射实现固定 4 倍压缩,压缩比不可调;光学损耗高、无主动可编程能力;未集成调制器、探测器与电控模块,集成度极低;图像重建依赖外部计算机与复杂 AI 模型,无法实现端到端实时处理,难以工程化部署。
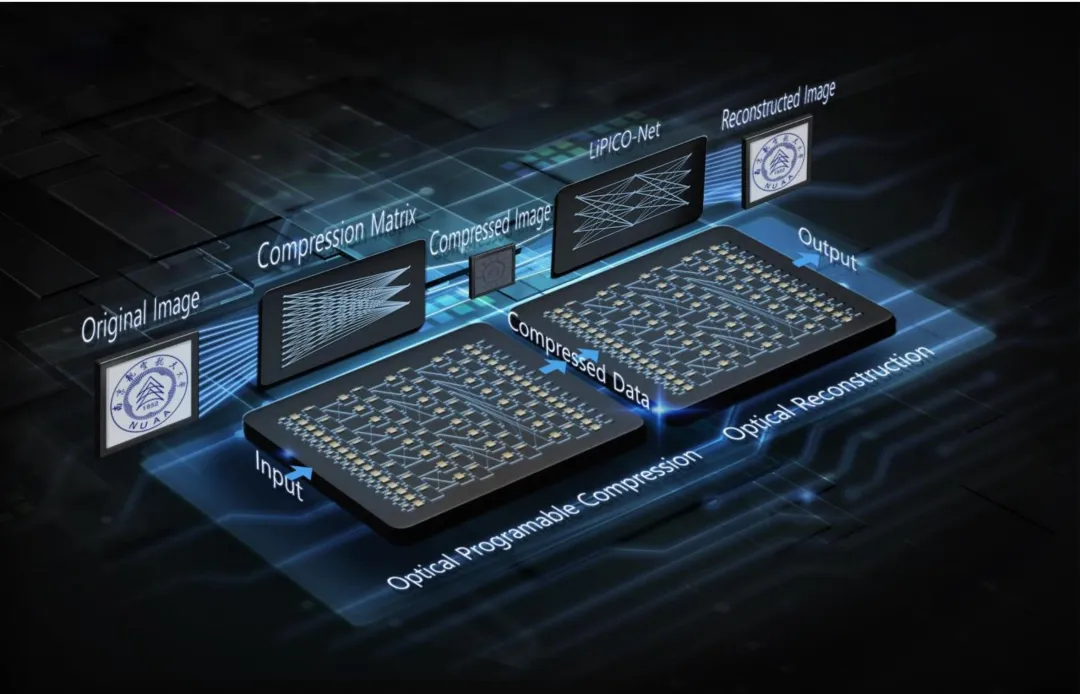
针对上述痛点,本研究提出 ** 光电计算处理器(OECP)** 架构,其核心为单片集成的 32×32 硅基光子计算芯片(PCC)。该芯片采用绝缘体上硅(SOI)平台与 130 nm 硅光工艺制备,创新性采用 FFT Mesh 架构,仅使用 80 个马赫 - 曾德尔干涉仪,较传统 Clements 架构减少约 80% 器件数量,大幅降低光学损耗与制备复杂度;片上集成 192 个带热槽的高效热光移相器,半波功率低于 18.4 mW,具备高速可编程能力;同时单片集成 32 路带宽超 30 GHz 的高速行波调制器与 32 路带宽超 40 GHz、响应度~0.95 A/W 的锗光电探测器,实现光信号编码、矩阵运算、光电探测的全闭环集成。芯片与 6 GSPS 数模转换器、2 GSPS 模数转换器、跨阻放大器及 FPGA 异质共封装,构成可独立运行的端到端处理系统,无需外部计算辅助。
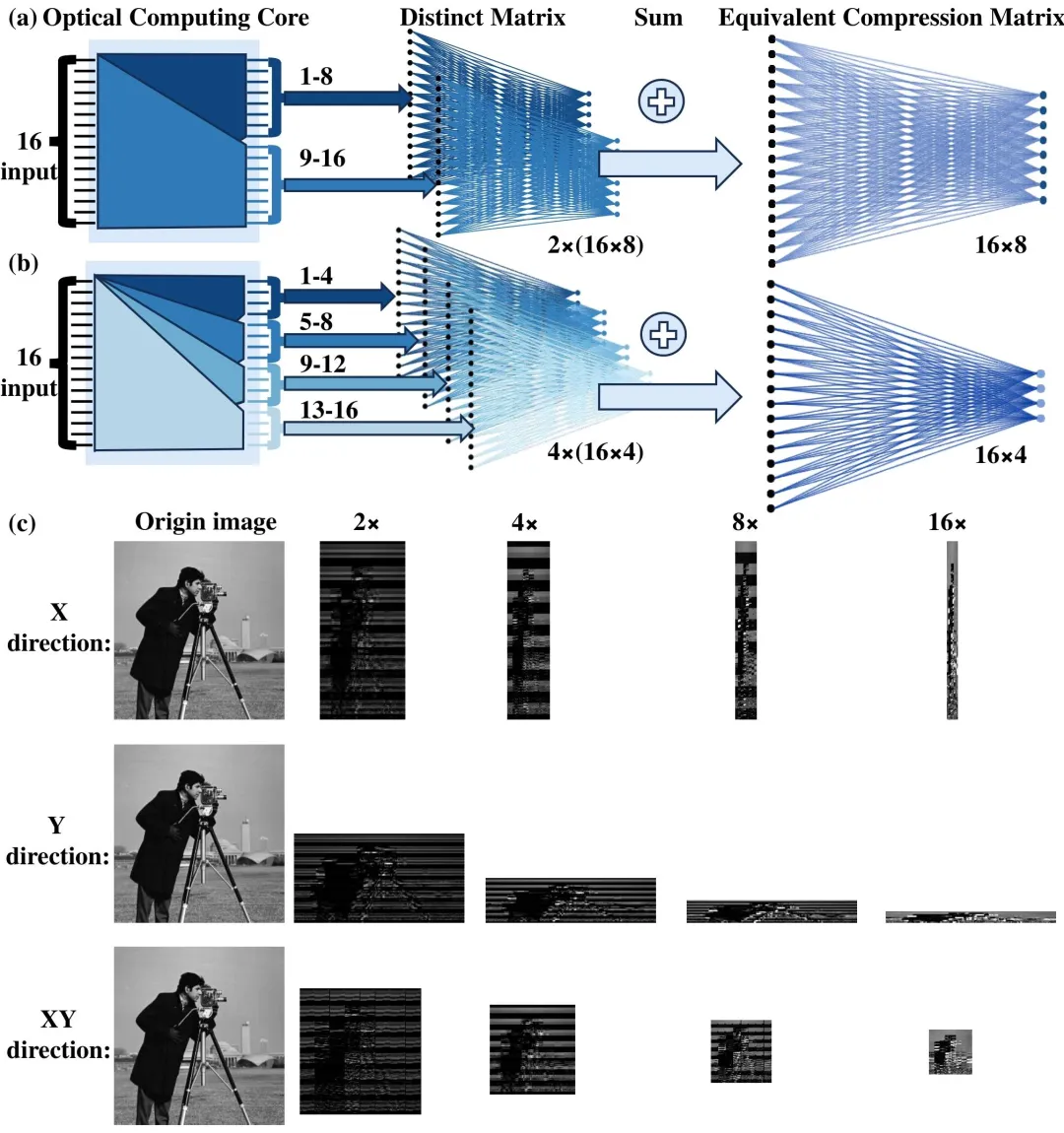
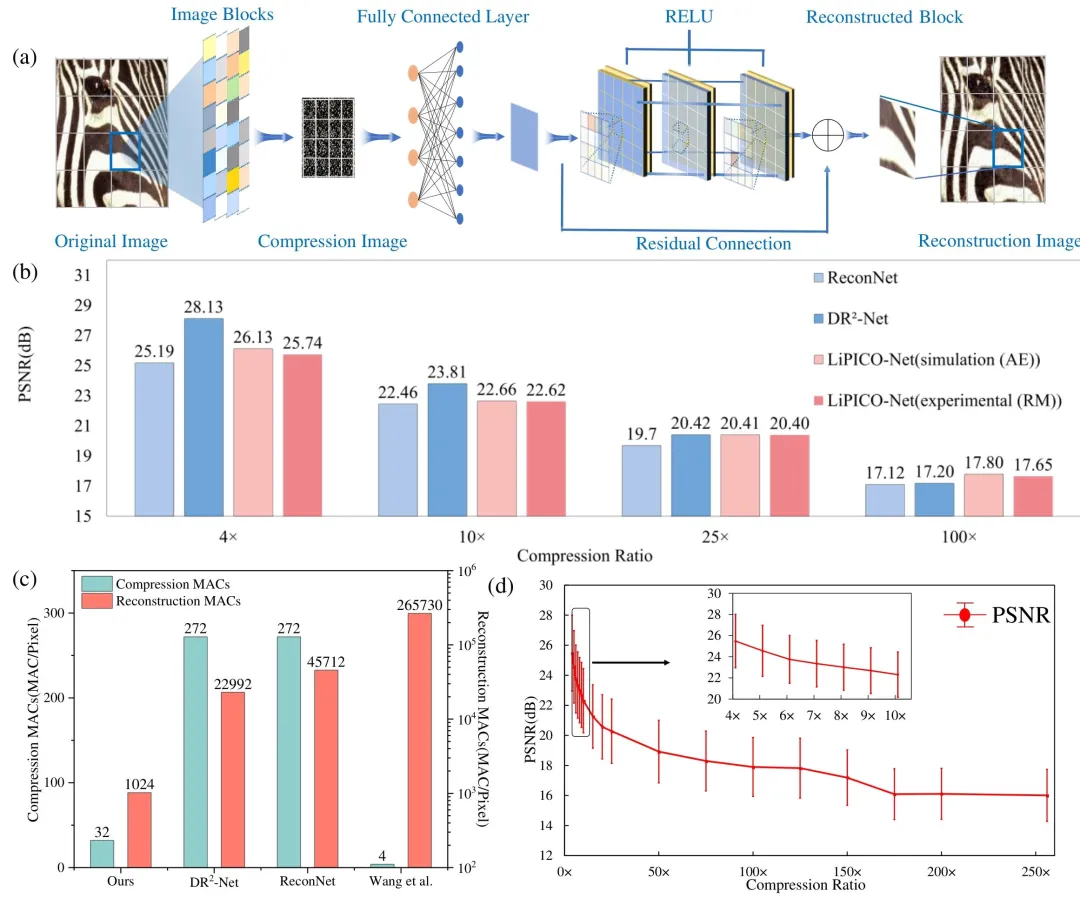
在图像压缩层面,团队提出子矩阵动态划分与可编程求和的创新方法:将 32×32 光子矩阵按输出通道划分为多组子矩阵,通过对不同子矩阵的输出进行相干求和,实现 X 方向、Y 方向、XY 双向的任意维度压缩,压缩比覆盖 2× 至 256×,最高支持 16×16 二维联合压缩。该方法摒弃传统端口截断带来的信息丢失与信噪比劣化,在提升压缩比的同时最大化保留图像有效信息,保证重建质量。在图像重建层面,团队专为光子硬件定制轻量化光子集成电路网络(LiPICO-Net),网络由 1 个 256×1024 全连接层、1 个残差连接与 3 个卷积层构成,卷积层保持 16 通道恒定宽度,核心卷积运算由光子芯片执行,全连接与残差部分由 FPGA 完成。该网络计算量较 ReconNet、DR²-Net 分别降低 95.46% 与 97.70%,且可与压缩矩阵联合训练,无需更换矩阵时重新训练全部参数,仅需更新全连接层即可适配不同压缩比。
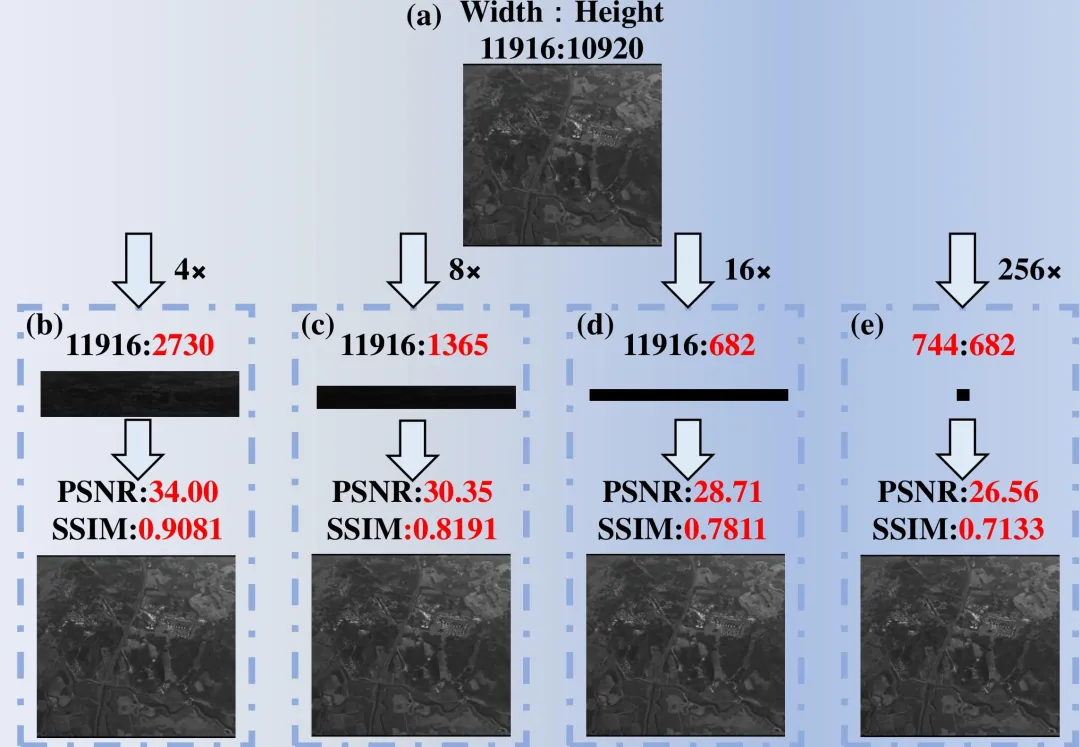
实验验证覆盖多标准数据集与实际场景:在 TEST11、BSDS200、General100 数据集上,256 倍压缩下重建 PSNR 仍高于 17 dB;针对 1.3 亿像素、1 GB 大小的机载遥感图像,4 倍、8 倍、16 倍、256 倍压缩下 PSNR 分别达到 34.00 dB、30.35 dB、28.71 dB、26.56 dB,结构相似性(SSIM)最高达 0.9081,实现超大幅面图像的高保真重建。性能基准测试表明,本系统图像压缩延迟仅 1.04 ps / 像素、能耗 1.26 pJ / 像素,端到端延迟 49.5 ps / 像素、总能耗 10.58 nJ / 像素,较传统被动光子方案、GPU 运行的经典深度学习模型,在延迟上降低 2 至 3 个数量级,能耗降低 3 个数量级,综合性能实现革命性提升。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
