蛋白质序列决定其三维结构和生物功能,因此蛋白测序是蛋白质组学、疾病诊断和生物标志物发现中的关键环节。
现有蛋白测序主要依赖Edman降解和质谱技术,但前者速度慢、读长短、通量低,后者对极短或极长肽段、低丰度蛋白以及翻译后修饰的解析仍存在明显瓶颈。纳米孔测序已在核酸分析中取得巨大成功,因此被寄予用于蛋白质和肽段测序的期望。
然而,肽链直接穿孔时获得的信息有限,传统肽链测序和外肽酶逐个释放氨基酸的策略也面临孔道分辨率、酶-孔耦合和单氨基酸识别等难题。该工作提出以镍修饰MspA纳米孔为核心,通过NTA-Ni适配器瞬时固定肽段N端,降低热运动干扰并放大事件差异。
该设计使氨基酸、肽段及其修饰形式能够在同一单分子平台上被区分,并进一步服务于肽段指纹分析和序列组装。
近日,南京大学的黄硕在Nature Nanotechnology发表了题为"High-resolution nanopore peptide sensing, profiling and sequence assembly"的研究论文。

核心亮点
1. 构建MspA-NTA-Ni纳米孔,利用Ni²⁺与肽段N端的可逆配位作用,实现高分辨肽段感知。
2. 在同一体系下记录20种蛋白氨基酸、4种修饰氨基酸、32种肽段、6种修饰肽、11种生物活性肽和2种新抗原肽信号。
3. 机器学习模型可在所研究数据集中实现最高97.4%的验证准确率,支持复杂分析物自动分类。
4. 酶解后的肽段可形成独特纳米孔指纹谱,用于数据库非依赖的肽段轮廓识别。
5. 通过外肽酶和内肽酶生成重叠片段,并结合事件数据库,实现参考肽序列组装及突变、缺失和翻译后修饰识别。
📄 全文速览
纳米孔在核酸测序成功后,被探索为蛋白质分析的潜在平台。然而,蛋白质测序仍具技术挑战,尚未建立用于蛋白质组学的成熟方法。
该研究展示了一种镍固定化的Mycobacterium smegmatis porin A纳米孔(MspA-NTA-Ni),可识别一系列蛋白质组分析物,包括氨基酸以及长度最高达39个氨基酸的肽段。
在相同条件下,该体系记录了20种蛋白氨基酸、4种翻译后修饰氨基酸、32种肽段、6种修饰肽、11种生物活性肽和2种新抗原肽的信号。基于机器学习的分析可在所研究数据集中以最高97.4%的验证准确率对这些分析物进行分类。
MspA-NTA-Ni纳米孔既支持肽段直接识别,也支持酶解后的肽段轮廓分析。作为概念验证,研究人员使用外肽酶和内肽酶消化参考肽,生成重叠肽段片段。纳米孔测量结合机器学习预测,可识别片段组成和部分序列,从而重构原始肽序列。该基于水解的策略对突变、缺失和翻译后修饰等序列改变具有敏感性,显示出用于靶向肽段表征的潜力。
📊 图文解读
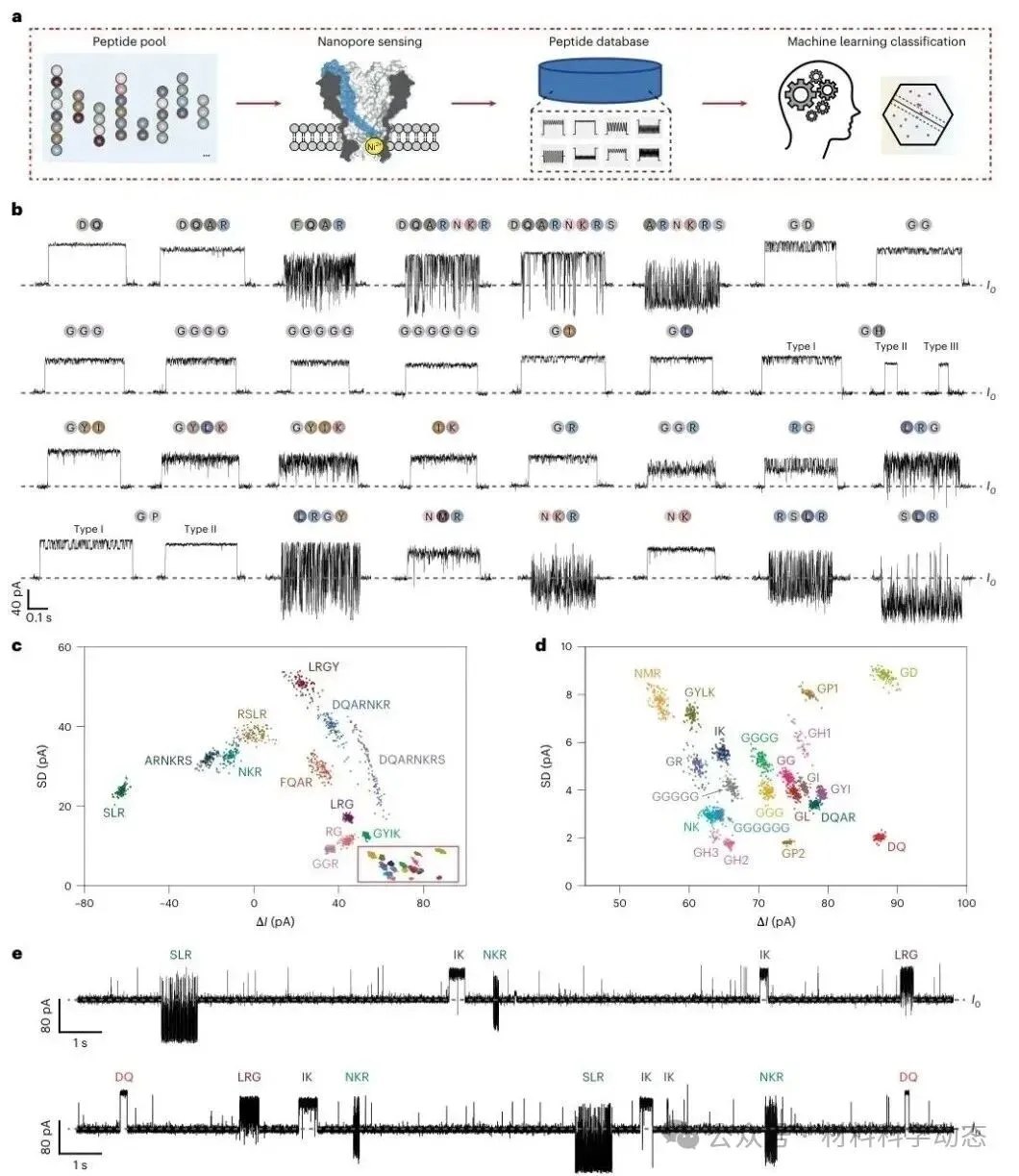
图1 | MspA-NTA-Ni纳米孔可为多种合成肽建立事件数据库,并通过机器学习实现混合肽段自动识别。
研究人员首先构建含30种模型肽的肽库,逐一采集MspA-NTA-Ni纳米孔事件,并提取ΔI、SD等特征。结果显示,不同肽段在二维散点图中可完全区分,平均阻塞幅度覆盖约149 pA动态范围。
即便RG/GR这类质谱较难区分的序列异构二肽,也能被清晰分辨;二次SVM模型在肽库分类中达到99.0%准确率。
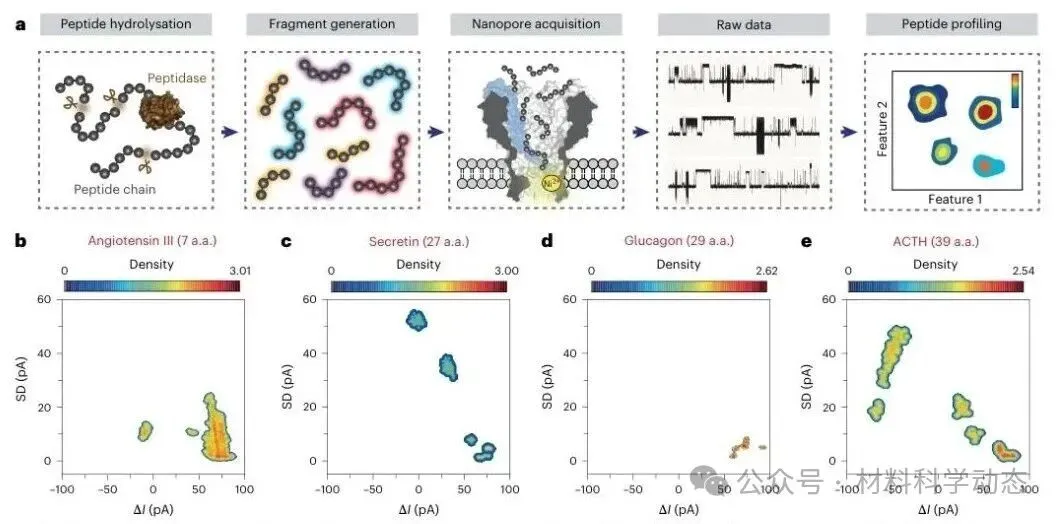
图2 | 酶解生成的肽段混合物可形成特异纳米孔指纹谱,用于生物活性肽轮廓识别。
该团队将单分子肽段识别扩展到肽段profiling:先用胰蛋白酶切割多肽,再用MspA-NTA-Ni检测水解产物。
血管紧张素III、促胰液素、胰高血糖素和ACTH等不同长度生物活性肽,均产生各自特征性的事件组合和核密度分布,说明酶解片段集合可作为肽段身份识别的独特指纹。
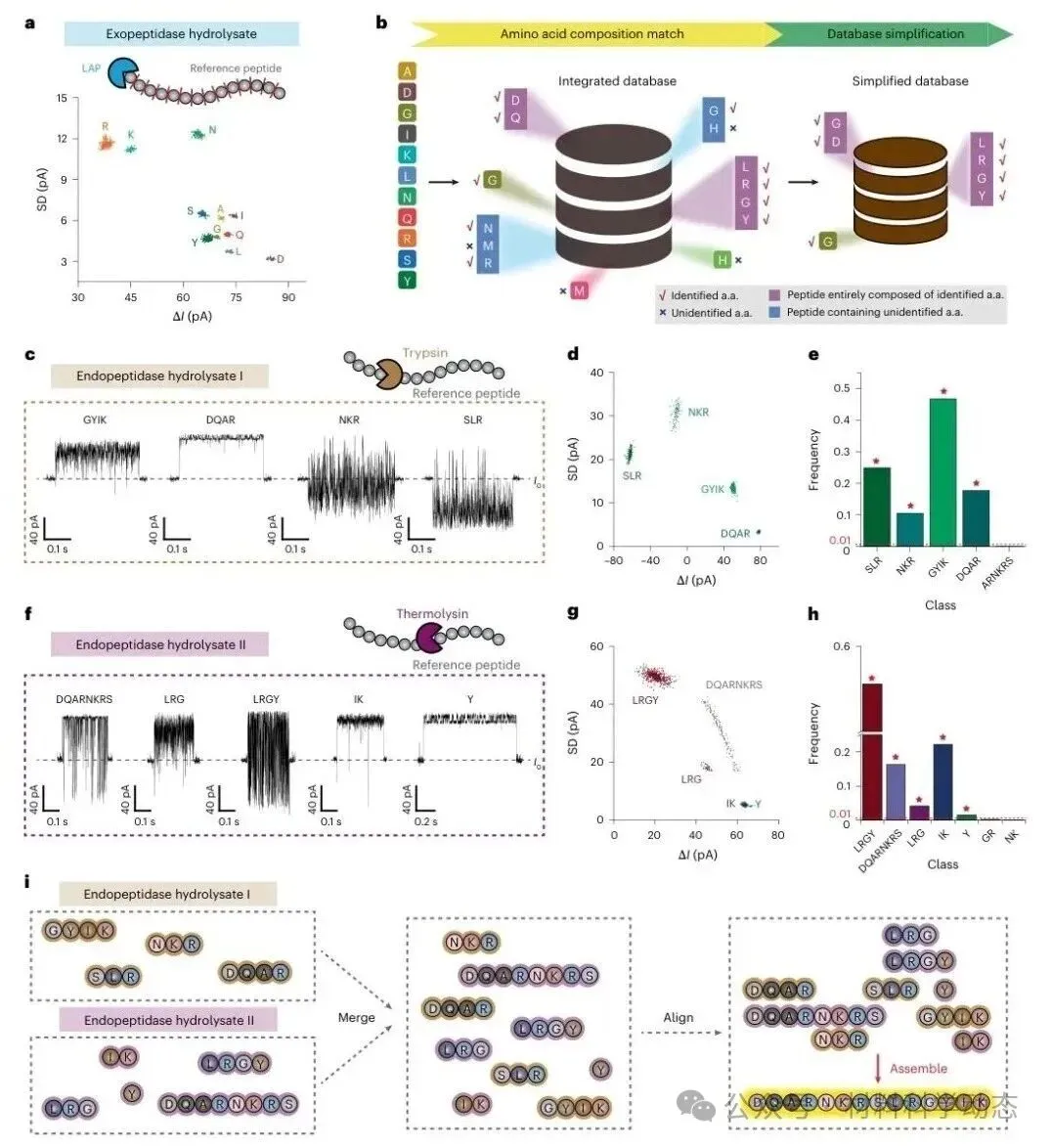
图3 | 外肽酶与内肽酶产生互补片段,结合纳米孔事件数据库可实现参考肽序列组装。
研究人员设计参考十四肽DQARNKRSLRGYIK,并先用外肽酶完全水解,确认其氨基酸组成,再据此简化整合数据库。
随后分别用胰蛋白酶和热溶菌素产生重叠内切片段,纳米孔识别出SLR、NKR、GYIK、DQAR、DQARNKRS、LRGY、LRG、IK等片段。通过片段重叠关系,最终组装出与真实序列一致的参考肽。
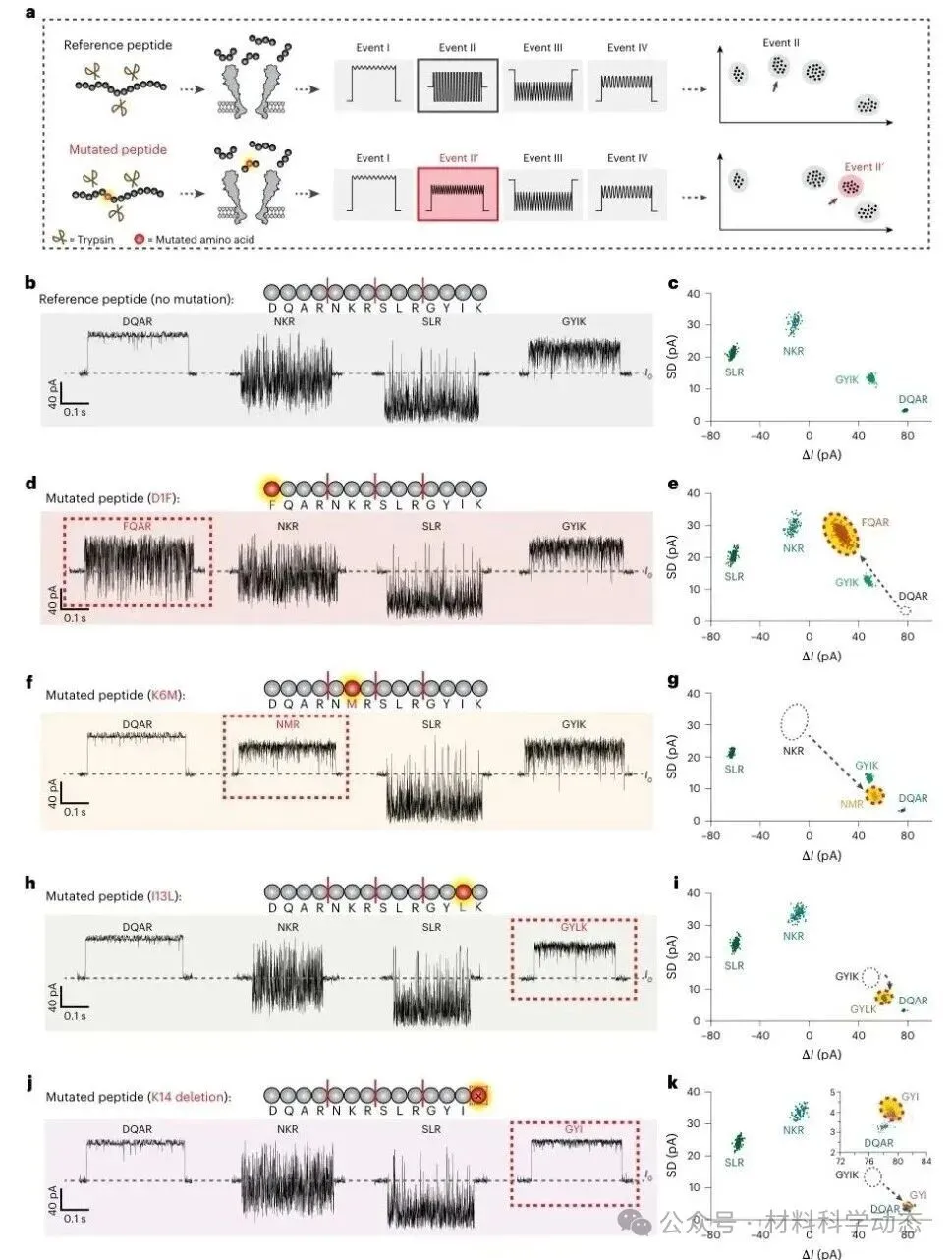
图4 | 基于水解片段的纳米孔序列组装能够识别单氨基酸突变、异亮氨酸/亮氨酸替换和末端缺失。
该研究合成了相对参考肽仅发生单点改变或缺失的D1F、K6M、I13L和K14 deletion肽段,并用胰蛋白酶水解后检测。与参考肽相比,缺失事件簇和新增事件簇共同指示突变发生位置。特别是I13L变体中Ile/Leu等质量替换也被明确区分,展示出该体系在传统质谱难点上的分辨优势。
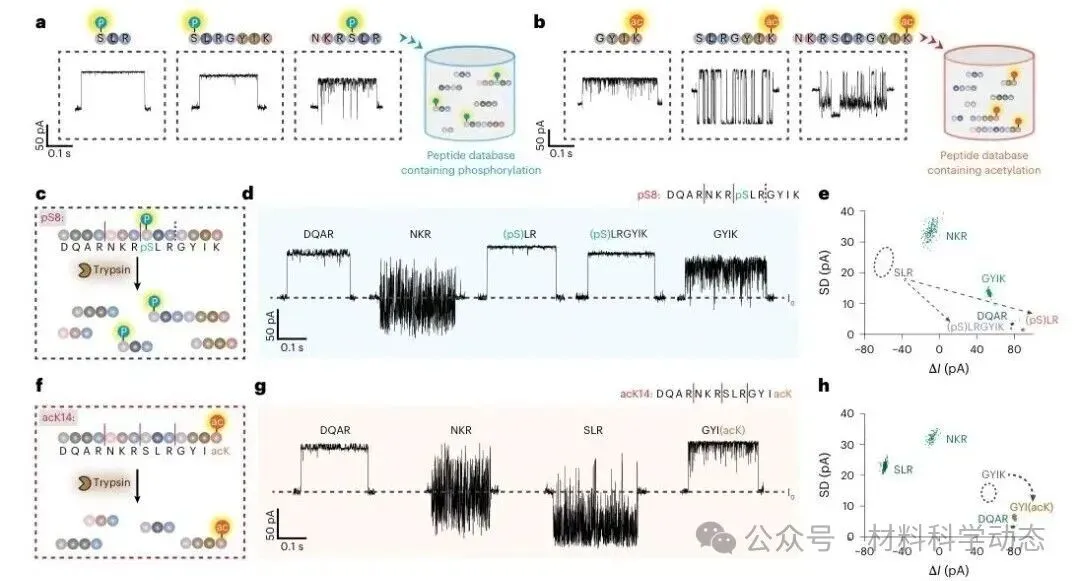
图5 | 扩展含磷酸化和乙酰化片段的数据库后,MspA-NTA-Ni可定位肽段翻译后修饰。
为验证翻译后修饰识别能力,研究人员合成含磷酸化丝氨酸的pS8和含乙酰化赖氨酸的acK14肽段,并补充测量相关修饰片段,建立修饰肽事件数据库。
胰蛋白酶水解后,pS8中的(pS)LR、(pS)LRGYIK以及acK14中的GYI(acK)等片段被准确识别,由此确定修饰位点。
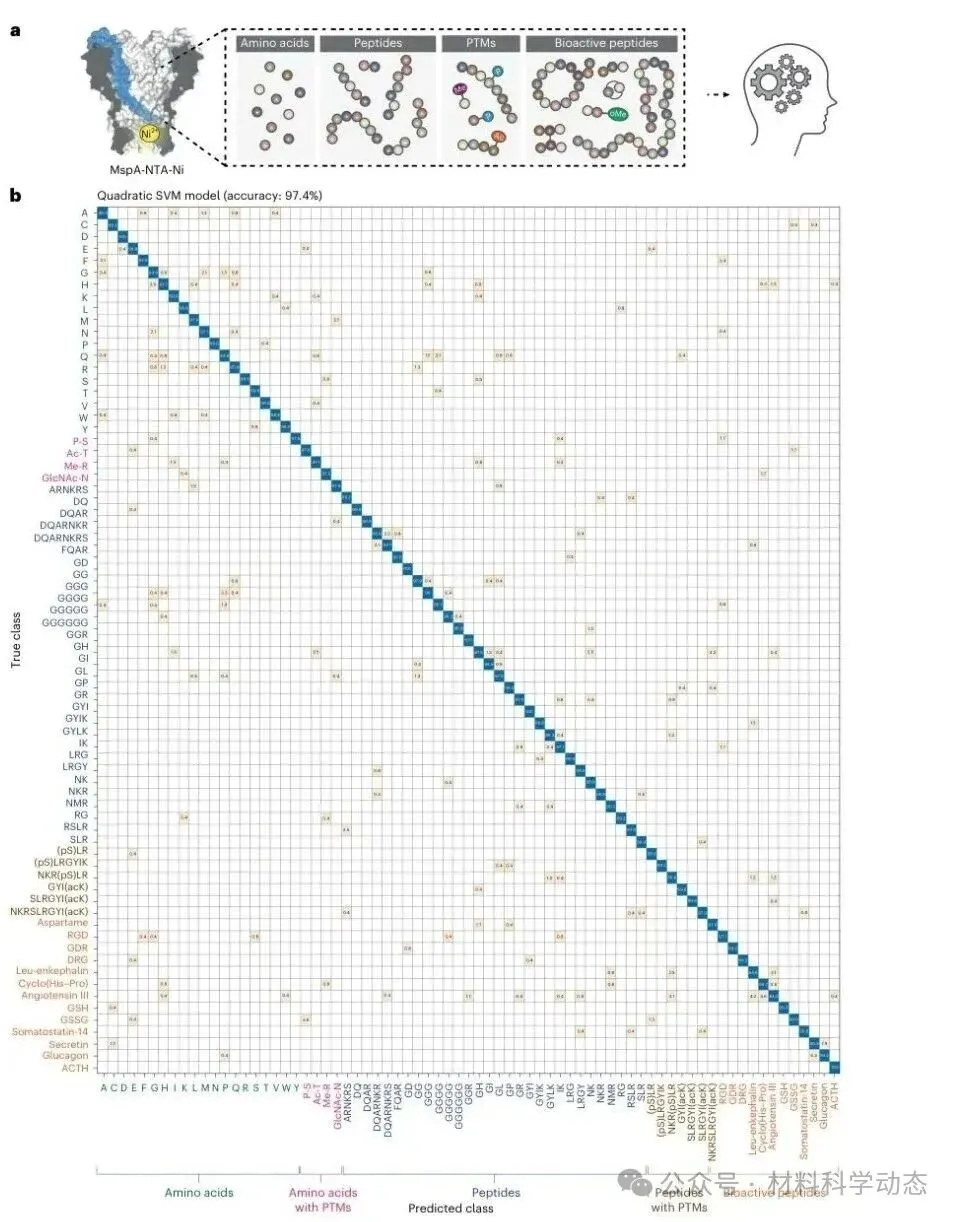
图6 | 73种氨基酸、肽段、修饰体和生物活性肽可在同一纳米孔体系中被统一分类识别。
研究人员将30种初始肽、6种修饰肽、20种氨基酸、4种修饰氨基酸、11种生物活性肽和2种RGD异构肽整合为73种分析物数据库。
重新训练后,二次SVM模型达到97.4%准确率,并能对先前参考肽水解片段进行稳定识别,说明数据库扩展并未明显削弱分类性能,为后续复杂蛋白质组分析奠定基础。
📝 总结
综上,该研究建立了一种基于MspA-NTA-Ni纳米孔的高分辨肽段感知与分析平台。通过镍离子与肽段N端的瞬时配位作用,该体系能够在单分子水平区分多种氨基酸、肽段、生物活性肽、新抗原肽及翻译后修饰形式。结合机器学习,纳米孔事件可被自动分类;
结合酶解策略,水解片段能够形成特征指纹,用于肽段profiling,并可通过重叠片段实现序列组装。该水解辅助纳米孔策略还能识别突变、缺失和翻译后修饰,显示出用于靶向肽段表征和未来单分子蛋白质组学分析的潜力。
High-resolution nanopore peptide sensing, profiling and sequence assembly,Nature Nanotechnology,2026,DOI:10.1038/s41565-026-02192-3